百度API:頻道新聞API_易源
第二個看這個是因為百度APIStore裡面免費+綜合排序這個就排第二,也是因為公司之前需要新聞采集,自己做的不好。用一下這個看看能有多少有效新聞:

今天看一共有44個頻道,每個頻道第一頁都可以取20條新聞。很強大。代碼很簡單:
1 <html>
2 <head><meta charset="utf-8"></head>
3 <body>
4 <?php
5 $ch = curl_init();
6 $url = 'http://apis.baidu.com/showapi_open_bus/channel_news/channel_news';
7 $header = array(
8 'apikey:百度API密鑰',
9 );
10 curl_setopt($ch, CURLOPT_HTTPHEADER , $header);
11 curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
12 curl_setopt($ch , CURLOPT_URL , $url);
13 $res = curl_exec($ch);
14 $data=json_decode($res,true);
15 echo '<pre>';
16 $channel=array();//頻道
17 if(isset($data['showapi_res_code']) && $data['showapi_res_code']===0 && is_array($data['showapi_res_body']['channelList'])){
18 $channel=$data['showapi_res_body']['channelList'];
19 }else{
20 echo 'error!';
21 exit;
22 }
23 //print_r($data);
24 foreach($channel as $v){
25 $id=$v['channelId'];
26 $name=$v['name'];
27
28 $ch = curl_init();
29 $url = "http://apis.baidu.com/showapi_open_bus/channel_news/search_news?channelId={$id}&page=1&needContent=1&needHtml=1";
30 curl_setopt($ch, CURLOPT_HTTPHEADER , $header);
31 curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
32 curl_setopt($ch , CURLOPT_URL , $url);
33 $res = curl_exec($ch);
34 $data=json_decode($res,true);
35 if(isset($data['showapi_res_body']['pagebean']['contentlist']) && is_array($data['showapi_res_body']['pagebean']['contentlist'])){
36 //$num=count($data['showapi_res_body']['pagebean']['contentlist']);
37 echo '<span>$name.'</span>:';
38 foreach($data['showapi_res_body']['pagebean']['contentlist'] as $dk=>$dv){
39 echo "<a href='{$dv['link']}' style='color:#646'>".$dv['title'].'</a>';
40 foreach($dv['imageurls'] as $iv){
41 echo '<img src="'.$iv['url'].'">;
42 }
43 echo ' ';
44 if($dk>3) break; //一類獲取三條退出,只做初步查看用
45 //print_r($dv);
46 }
47 }
48 echo '<br/>';
49 //break;
50 }
51 echo '</pre>';
52 ?>
53 </body>
54 </html>
自己之前給公司做的新聞采集就比較弱,上一篇提到過,就是用file_get_contents()獲取內容然後preg_match正則去取,正則用的也屬於新手階段。
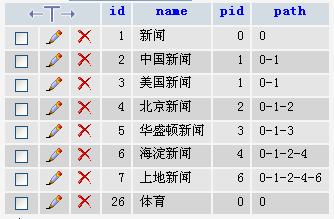
說一下當時的新聞采集的思路,就是找新聞列表頁,比如:人民網-北京-區縣,然後分析出來所有鏈接,去鏈接裡面去采集新聞標題,內容,圖片。數據庫存儲:`tag`表存儲標簽,字段名稱,鏈接地址,列表開始結束標簽,新聞標題開始結束標簽,內容開始結束標簽。以後采集時候直接選取名稱然後去查詢。目標網站改版後得更新。
遇到的難點有:1.編碼,GB2312轉UTF-8,開始用iconv()後來改用mb_detect_encoding().2.就是正則了,獲取圖片等等。獲取新聞的調試頁面
代碼特別亂,就不獻丑。