介紹
COLUMN分區是5.5開始引入的分區功能,只有RANGE COLUMN和LIST COLUMN這兩種分區;支持整形、日期、字符串;RANGE和LIST的分區方式非常的相似。
COLUMNS和RANGE和LIST分區的區別
1.針對日期字段的分區就不需要再使用函數進行轉換了,例如針對date字段進行分區不需要再使用YEAR()表達式進行轉換。
2.COLUMN分區支持多個字段作為分區鍵但是不支持表達式作為分區鍵。
COLUMNS支持的類型
整形支持:tinyint,smallint,mediumint,int,bigint;不支持decimal和float
時間類型支持:date,datetime
字符類型支持:char,varchar,binary,varbinary;不支持text,blob
一、RANGE COLUMNS分區
1.日期字段分區
CREATE TABLE members (
id INT,
joined DATE NOT NULL
)
PARTITION BY RANGE COLUMNS(joined) (
PARTITION a VALUES LESS THAN ('1960-01-01'),
PARTITION b VALUES LESS THAN ('1970-01-01'),
PARTITION c VALUES LESS THAN ('1980-01-01'),
PARTITION d VALUES LESS THAN ('1990-01-01'),
PARTITION e VALUES LESS THAN MAXVALUE
);
1.插入測試數據
insert into members(id,joined) values(1,'1950-01-01'),(1,'1960-01-01'),(1,'1980-01-01'),(1,'1990-01-01');
2.查詢分區數據分布
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='members';
當前有5個分區只插入了4條記錄,其中C分區是沒有記錄的,結果和實際一樣。

3.分析執行計劃
explain select id,joined from tb_partition.members where joined=YEAR(now()); explain select id,joined from tb_partition.members where joined='1963-01-01';
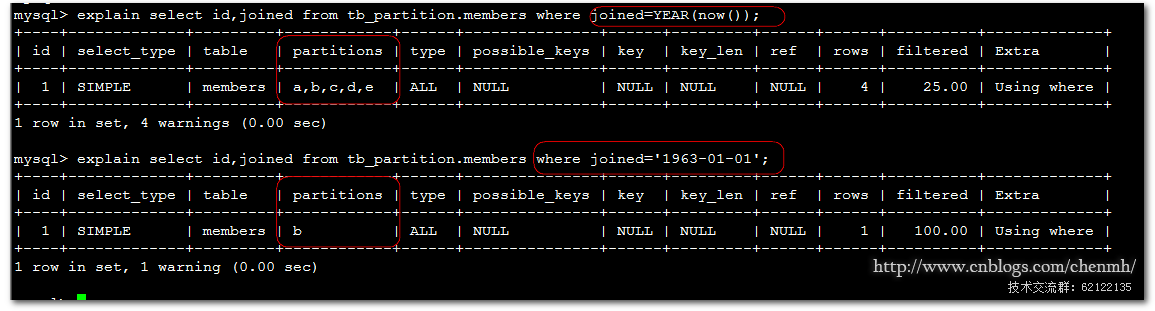
第一條查詢使用了函數導致查詢沒有走具體的分區而是掃描的所有的分區,而第二條查詢執行語句查找具體的分區。
2.多個字段組合分區
CREATE TABLE rcx ( a INT, b INT ) PARTITION BY RANGE COLUMNS(a,b) ( PARTITION p0 VALUES LESS THAN (5,10), PARTITION p1 VALUES LESS THAN (10,20), PARTITION p2 VALUES LESS THAN (15,30), PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE) );
注意:多字段的分區鍵比較是基於數組的比較。它先用插入的數據的第一個字段值和分區的第一個值進行比較,如果插入的第一個值小於分區的第一個值那麼就不需要比較第二個值就屬於該分區;如果第一個值等於分區的第一個值,開始比較第二個值同樣如果第二個值小於分區的第二個值那麼就屬於該分區。

例如:
insert into rcx(a,b)values(1,20),(10,15),(10,30);
第一組值:(1,20);1<5所以不需要再比較20了,該記錄屬於p0分區。
第二組值:(10,15),10>5,10=10且15<20,所以該記錄屬於P1分區
第三組值:(10,30),10=10但是30>20,所以它不屬於p1,它滿足10<15所以它屬於p2
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='rcx';

注意:RANGE COLUMN的多列分區第一列的分區值一定是順序增長的,不能出現交叉值,第二列的值隨便,例如以下分區就會報錯
PARTITION BY RANGE COLUMNS(a,b) ( PARTITION p0 VALUES LESS THAN (5,10), PARTITION p1 VALUES LESS THAN (10,20), PARTITION p2 VALUES LESS THAN (8,30), PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE) );
由於分區P2的第一列比P1的第一列要小,所以報錯,後面的分區第一列的值一定要比前面分區值要大,第二列沒規定。
二、LIST COLUMNS分區
1.非整形字段分區
CREATE TABLE listvar (
id INT NOT NULL,
hired DATETIME NOT NULL
)
PARTITION BY LIST COLUMNS(hired)
(
PARTITION a VALUES IN ('1990-01-01 10:00:00','1991-01-01 10:00:00'),
PARTITION b VALUES IN ('1992-01-01 10:00:00'),
PARTITION c VALUES IN ('1993-01-01 10:00:00'),
PARTITION d VALUES IN ('1994-01-01 10:00:00')
);
ALTER TABLE listvar ADD INDEX ix_hired(hired);
INSERT INTO listvar() VALUES(1,'1990-01-01 10:00:00'),(1,'1991-01-01 10:00:00'),(1,'1992-01-01 10:00:00'),(1,'1993-01-01 10:00:00');
LIST COLUMNS分區對分整形字段進行分區就無需使用函數對字段處理成整形,所以對非整形字段進行分區建議選擇COLUMNS分區。

EXPLAIN SELECT * FROM listvar WHERE hired='1990-01-01 10:00:00';

2.多字段分區
CREATE TABLE listvardou ( id INT NOT NULL, hired DATETIME NOT NULL ) PARTITION BY LIST COLUMNS(id,hired) ( PARTITION a VALUES IN ( (1,'1990-01-01 10:00:00'),(1,'1991-01-01 10:00:00') ), PARTITION b VALUES IN ( (2,'1992-01-01 10:00:00') ), PARTITION c VALUES IN ( (3,'1993-01-01 10:00:00') ), PARTITION d VALUES IN ( (4,'1994-01-01 10:00:00') ) ); ALTER TABLE listvardou ADD INDEX ix_hired(hired); INSERT INTO listvardou() VALUES(1,'1990-01-01 10:00:00'),(1,'1991-01-01 10:00:00'),(2,'1992-01-01 10:00:00'),(3,'1993-01-01 10:00:00'); SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='listvardou';

EXPLAIN SELECT * FROM listvardou WHERE id=1 and hired='1990-01-01 10:00:00';

由於分區是組合字段,filtered只有50%,對於組合分區索引也最好是建組合索引,其實如果能通過id字段刷選出數據,單獨建id字段的索引也是有效果的,但是組合索引的效果是最好的,其實和非分區鍵索引的概念差不多。
ALTER TABLE listvardou ADD INDEX ix_hired1(id,hired);

備注:文章中的示例摘自mysql官方參考手冊
三、移除表的分區
ALTER TABLE tablename REMOVE PARTITIONING ;
注意:使用remove移除分區是僅僅移除分區的定義,並不會刪除數據和drop PARTITION不一樣,後者會連同數據一起刪除
總結
RANGE COLUMNS和LIST COLUMNS分區其實是RANG和LIST分區的升級,所以可以直接使用COLUMN分區。注意COLUMNS分區不支持timestamp字段類型。
以上所述是小編給大家介紹的MySQL COLUMNS分區,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對網站的支持!