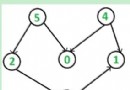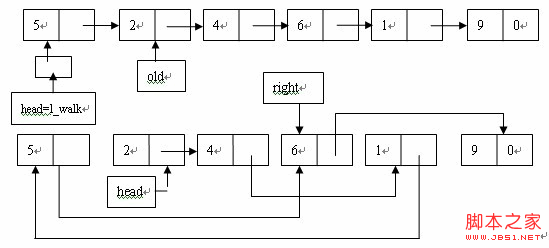
這裡假設鏈表的值一次是5、2、4、6、1。根據程序首先head = left_walk指向值為5的節點,old指向值為2的節點,2小於5,所以加入2到左面的子鏈表中,*left_walk=old,我們知道,*left_walk指向的是第一個節點,這樣做改變了head指針值,使其指向第二個節點,然後left_walk後移,old後移,4同樣小於5,故繼續上述操作,但是這是*left_walk和old指向的是同一個節點,沒有引起任何變化,left_walk和old後移,6大於5,這時不同就出現了,要把其加入到右邊的子鏈表中,故是*right_walk = old,其實right_walk初試化為&right,這句話相當於right = old,即令old當前指向的節點作為右邊子鏈表的第一個節點,以後大於基准的節點都要加入到這個節點中,且總是加入到尾部。此時right_walk,和old後移,1小於5應該加入到左邊的子鏈表中,*left_walk = old,此時*left_walk指向6,故此語句的作用是更改節點4的next值,把其改為1的地址,這樣6就從原來的鏈表中脫鉤了,繼續left_walk和old後移到9節點,應加入到右邊的子鏈表中,此時*right_walk指向1,故把9節點加入到6節點的後面。
這就是基本的排序過程,然而有一個問題需要搞明白,比如有節點依次為struct node *a, *b, *c,node **p , p = &b,如果此時令*p = c,即實際效果是a->next = c;我們知道這相當於該a的next域的值。而p僅僅是一個指針的指針,它是指向b所指向的節點的地址的指針,那麼當我們更改*p的值的時候怎麼會改到了a的next呢(這個可以寫程序驗證下,確實如此)?其實並非如此,我們仔細的看看程序,left_walk初始化為head,那麼第一次執行*left_walk是把head指向了左邊鏈表的起始節點,然後left_walk被賦值為&(old->next),這句話就有意思了,我們看一看下面在執行*left_walk=old時的情況,可以簡單的來個等價替換,*left_walk = old也就相當於*&(old->next) = old,即old->nex = old,不過這裡的old可不一定是old->next所指向的節點,應為left_walk和right_walk都指向它們的old節點,但是卻是不同的。
算法到這裡並沒有完,這只是執行了一次劃分,把基准放入了正確的位置,還要繼續,不過下面的就比較簡單了,就是遞歸排序個數比較小的子鏈表,迭代處理節點數目比較大的子鏈表。
完整的代碼如下:
代碼如下:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
//鏈表節點
struct node
{
int data;
struct node *next;
};
//鏈表快排序函數
void QListSort(struct node **head,struct node *h);
//打印鏈表
void print_list(struct node *head)
{
struct node *p;
for (p = head; p != NULL; p = p->next)
{
printf("%d ", p->data);
}
printf("\n");
}
int main(void)
{
struct node *head = NULL;
struct node *p;
int i;
/**
* 初始化鏈表
*/
srand((unsigned)time(NULL));
for (i = 1; i < 11; ++i)
{
p = (struct node*)malloc(sizeof(struct node));
p->data = rand() % 100 + 1;
if(head == NULL)
{
head = p;
head->next = NULL;
}
else
{
p->next = head->next;
head->next = p;
}
}
print_list(head);
printf("---------------------------------\n");
QListSort(&head,NULL);
print_list(head);
system("pause");
return 0;
}
void QListSort(struct node **head, struct node *end)
{
struct node *right;
struct node **left_walk, **right_walk;
struct node *pivot, *old;
int count, left_count, right_count;
if (*head == end)
return;
do {
pivot = *head;
left_walk = head;
right_walk = &right;
left_count = right_count = 0;
//取第一個節點作為比較的基准,小於基准的在左面的子鏈表中,
//大於基准的在右邊的子鏈表中
for (old = (*head)->next; old != end; old = old->next)
{
if (old->data < pivot->data)
{ //小於基准,加入到左面的子鏈表,繼續比較
++left_count;
*left_walk = old; //把該節點加入到左邊的鏈表中,
left_walk = &(old->next);
}
else
{ //大於基准,加入到右邊的子鏈表,繼續比較
++right_count;
*right_walk = old;
right_walk = &(old->next);
}
}
//合並鏈表
*right_walk = end; //結束右鏈表
*left_walk = pivot; //把基准置於正確的位置上
pivot->next = right; //把鏈表合並
//對較小的子鏈表進行快排序,較大的子鏈表進行迭代排序。
if(left_walk > right_walk)
{
QListSort(&(pivot->next), end);
end = pivot;
count = left_count;
}
else
{
QListSort(head, pivot);
head = &(pivot->next);
count = right_count;
}
}
while (count > 1);
}