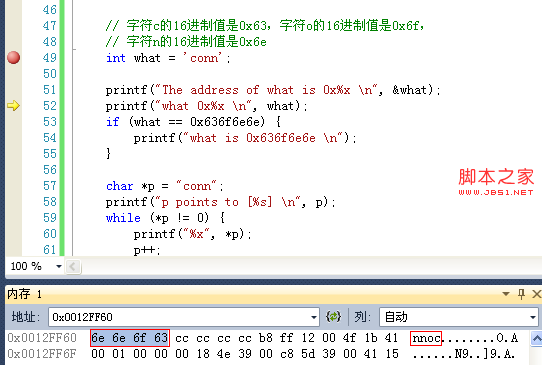
C++對象可以使用兩種方式進行創建:構造函數和復制構造函數。假如我們定義了類A,並使用它創建對象。
代碼如下:
A a,b;
A c=a;
A d(b);
對象a和b使用編譯器提供的默認構造函數A::A()創建出來,我們稱這種創建方式為對象的定義(包含聲明的含義)。對象c和d則是使用已有的對象,通過編譯器提供的復制構造函數A::A(const A&)創建,我們稱這種創建方式為對象的初始化(包含定義和聲明的含義)。
可能不少人會把對象的初始化和對象的賦值混淆,比如。
代碼如下:
c=d;
這裡把對象d賦值給對象c並非創建新的對象,它不會調用任何構造函數。編譯器默認提供的賦值運算符重載函數const A&operator=(const A&)為該語句提供支持。
編譯器除了提供默認構造函數、復制構造函數和賦值運算符重載函數之外,有可能還為我們提供了析構函數A::~A(),但是這裡的析構函數並不是virtual的(相信會有童鞋忘記這一點)。
這些基礎的語法對學習過C++的人或許並不陌生,我們自從學習了面向對象C++後,一直都知道編譯器為我們提供了這樣的便利條件。經過多年的編程實踐和體驗,我們絕對相信編譯器的確為我們做了這些工作,因為我們沒有遇到過任何問題。甚至我們腦子中會默認形成一個概念——即使我定義了一個空類(類內什麼都沒有),編譯器依然會“乖乖的”為我們生成上邊所說的四個函數。
如果你真的形成了這種觀念的話,那麼恭喜你,因為你已經將C++基本規則運用的十分熟練了。同時遺憾的是你我都看到了冰山一角,編譯器的工作方式遠不像我們使用它的那樣。讀者可能會疑問,難道編譯器沒有生成這些函數嗎?答:要看你類的定義。那麼編譯器到底如何生成這些函數呢?和我一樣又好奇心的人都想一探究竟,而這些內容在《Inside The C++ Object Model》被诠釋的比較徹底。筆者也通過“借花獻佛”的方式將該書所描述的對象構造的內幕結合個人的理解和大家一起分享。
首先我們從最簡單的談起,編譯器為類生成構造函數了嗎?如果按照上邊描述的例子,只有一個空的類定義的話,我們可以肯定的說——沒有。對編譯器這樣的做法,我們不必感到驚訝。試想一個空的類——沒有數據成員,沒有成員函數,即使生成了構造函數又能做什麼呢?即便是生成了,也只是一個空構造函數而已。
代碼如下:
A(){}
它什麼也做不了,也什麼都不必做。更“悲劇”,它的出現不僅沒有任何積極意義,還會為編譯器和程序運行增加完全不必要的函數調用負擔。
既然如此,我們讓這個類再復雜一點,我們為它增加數據成員和成員函數,比如下邊這段代碼(我們記它為例子1)。
代碼如下:
class A
{
public:
int var;
void fun(){}
};
即便如此,結果還是和上邊的一樣,不生成構造函數!因為沒有任何理由對var初始化,況且編譯器也不知道用什麼值給它初始化。

果然,在主函數內定義對象a後,沒有任何構造函數被調用。
有人可能會說用0初始化不行嗎?這只是我們的“一廂情願”而已。一個沒有初始化的變量本身的值就可以是不確定的,何必要生成一個沒有任何意義的初始化為0的語句呢。
編譯器到底怎樣才能生成構造函數呢?!或許你和我一樣有點“抓狂”了。不過現在還不是絕望的時候,因為編譯器需要我們給它一個“正當的理由”生成構造函數。有四個正當的理由,讓編譯器不得不生成構造函數,這裡一一介紹。
首先,我們修改一下var的類型。這裡假設它不是內置類型int,而是一個定義好的類B。
B var;
修改一下數據成員的類型為自定義類型能影響編譯器的抉擇嗎?答:可能。這要看類B有沒有定義構造函數。讀者可能有點明白了,是的,如果B沒有定義構造函數(和這裡的A一個樣子),那麼編譯器仍然沒有理由生成構造函數——為B初始化什麼呢?反之,B一旦定義了默認構造函數B::B(),即便它是空的,編譯器就不得不為A創建默認構造函數了(這裡不考慮編譯器的深度優化)。因為A的對象需要用B的默認構造函數初始化它自己的成員var,雖然B的構造函數什麼也沒做。因為編譯器不能假定B的構造函數做了什麼樣的操作(極端一點:萬一修改了一個全局變量了呢?),因此編譯器有絕對的必要生成A的構造函數,保證B類型的數據成員的構造函數正常執行。
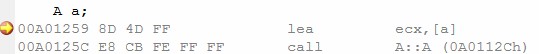
轉到編譯器為A生成的構造函數處,我們發現了B的構造函數被調用的語句(選中行)。
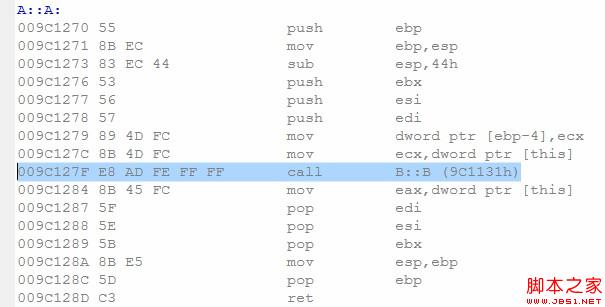
當然,如果B提供了構造函數,但不是默認的構造函數,那麼必須要程序員介入為var初始化,否則編譯器就不客氣了——error!
因此,編譯器生成默認構造函數的第一個正當理由是——類內數據成員是對象,並且該對象的類提供了一個默認構造函數。
現在,我們回到例子1,這裡我們不修改var的類型,而是讓A繼承於另一個類C。
代碼如下:
class A:public C
我們都知道,在C++構造函數初始化語法中,構造函數會先初始化基類C,再初始化自身的數據成員或者對象。因此,這裡的問題和對象成員var類似。如果基類C沒有提供任何構造函數,那麼編譯器仍然不提供A的默認構造函數。如果C提供了默認構造函數,結果和前邊類似。
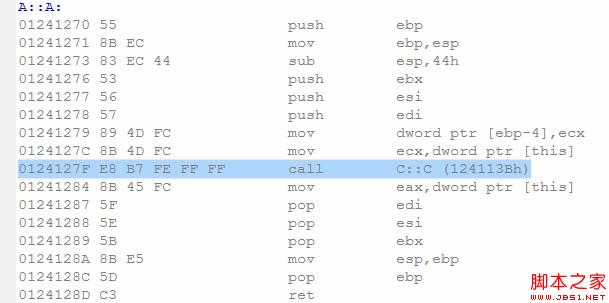
結果不出所料,編譯器為A生成了構造函數,並且調用了基類C定義的默認構造函數。同樣,若C沒有提供默認默認構造函數,而提供了其他構造函數,編譯是無法通過的。
這也是編譯器生成默認構造函數的第二個正當理由——類的基類提供了默認的構造函數。
我們再次回到例子1,這次我們修改成員函數fun。
代碼如下:
virtual void fun(){}
我們把類A的成員函數fun修改為虛函數,再次看看是否產生了默認構造函數。
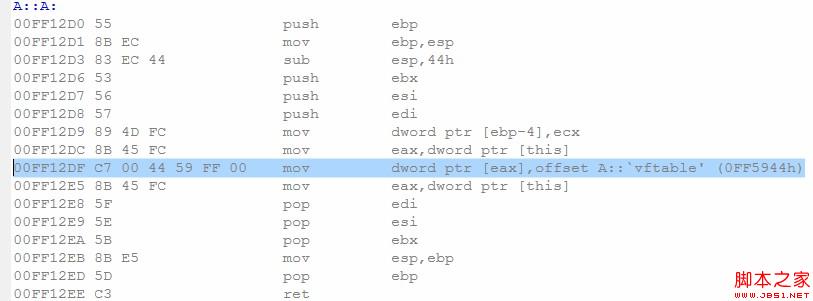
這次編譯器“毫不客氣”的為A生成了默認構造函數,雖然它沒有調用任何其他的構造函數!這是什麼原因呢?原來,C++為了實現多態機制,需要為類維護一個虛函數表(vftable),而每個該類的對象都保存一個指向該虛函數表的一個指針(一般保存在對象最開始的四個四節處,多態機制的實現這裡暫不介紹)。編譯器為A生成構造函數,其實不為別的,就為了保證它定義的對象都要正常初始化這個虛函數表的指針(vfptr)!
好了,因此我們得出編譯器生成默認構造函數的第三個正當理由——類內定義了虛函數。這裡可能還涉及一個更復雜點的情況:類內本身沒有定義虛函數,但是繼承了基類的虛函數。其實按照上述的原則,我們可以推理如下:基類既然定義了虛函數,那麼基類本身就需要生成默認構造函數初始化它本身的虛函數表指針。而基類一旦產生了默認構造函數,派生類就需要產生默認構造函數調用它。同時,如果讀者對多態機制了解清除的話,派生類在生成的默認構造函數內還會初始化一次這個虛函數表指針的。
最後,我們再次回到例子1,這次仍然讓A繼承於C,但是這次C是一個空類——什麼都沒有,也不會自動生成默認構造函數。但是A繼承C的方式要變化一下。
代碼如下:
class A:public virtual C
A虛繼承於C,這次又有什麼不同呢?
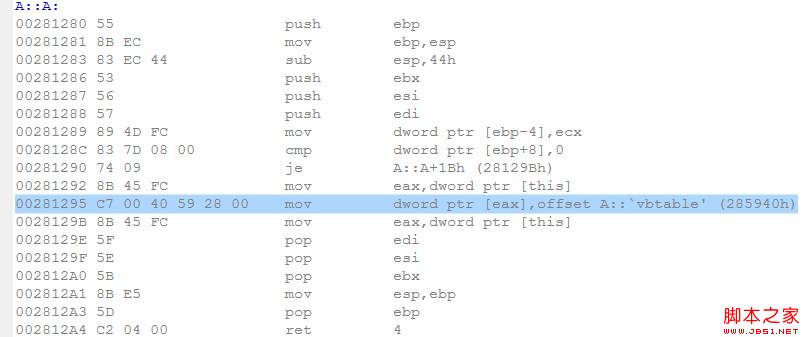
這次編譯器也生成了A的構造函數,並且初始化過程和虛函數時有點類似。細心觀察下發現,這次構造函數也初始化了一張表——vbtable。了解虛繼承機制的讀者應該不會陌生,這張表叫虛基類表,它記錄了類繼承的所有的虛基類子對象在本類定義的對象內的偏移位置(至於虛繼承機制的實現,我們以後詳細探討)。為了保證虛繼承機制的正確工作,對象必須在初始化階段維護一個指向該表的一個指針,稱為虛表指針(vbptr)。編譯器因為它提供A的默認構造函數的理由和虛函數時類似。
這樣,我們得出編譯器生成默認構造函數的第四個正當理由——類使用了虛繼承。
到這裡,我們把編譯器為類生成默認構造函數的正當理由闡述完畢,相信大家應該對構造函數的生成時機有了一個大致的認識。這四種“正當理由”其實是編譯器不得不為類生成默認構造函數的理由,《Inside The C++ Object Model》裡稱這種理由為nontrival的(候sir翻譯的很別扭,所以怎麼翻譯隨你啦)。除了這四種情況外,編譯器稱為trival的,也就是沒有必要為類生成默認構造函數。這裡討論的構造函數生成准則的內容是寫進C++Standard的,如此看來標准就是“貼合正常思維”的一套准則(簡單YY一下),其實本就是這樣,編譯器不應該為了一致化做一些沒有必要的工作。
通過對默認構造函數的討論,相信大家對復制構造函數、賦值運算符重載函數、析構函數的生成時機應該可以自動擴展了。沒錯,它們遵循著一個最根本的原則:只有編譯器不得不為這個類生成函數的時候(nontrival),編譯器才會真正的生成它。
因此,正如標題所說,我們不要被C++語法中所描述的那些條條框框所“蒙騙”了。的確,相信這些生成規則不會對我們的編程帶來多大的影響(不會產生錯誤),但是只有了解它們的背後操作,我們才知道編譯器究竟為我們做了什麼,我們才知道如何使用C++才能讓它變得更有效率——比如消除不必要的構造和虛擬機制等(如果可以的話)。相信本文對C++自動生成的內容的描述讓不少人認清對象構造函數產生的前因後果,希望本文對你有所幫助。