1. sizeof()和strlen()函數
sizeof常見標准用法(1)、(2)、(3) [摘自C++ Reference]:
//(1)
char buff[6];
strncpy(buff, argv[1], sizeof(buff));
//(2)
int array[] = { 3, 1, 4, 1, 5, 9 };
unsigned int array_size = sizeof(array) / sizeof(array[0]);
//(3)
typedef struct data_type {
int age;
char name[20];
} data;
data *bob;
bob = (data*) malloc( sizeof(data) );
if( bob != NULL ) {
bob->age = 22;
strcpy( bob->name, "Robert" );
printf( "%s is %d years old\n", bob->name, bob->age );
}
free( bob );
可見,sizeof主要用於求某種數據(例如int,數組,字符串,指針,結構體…)的size,例如:
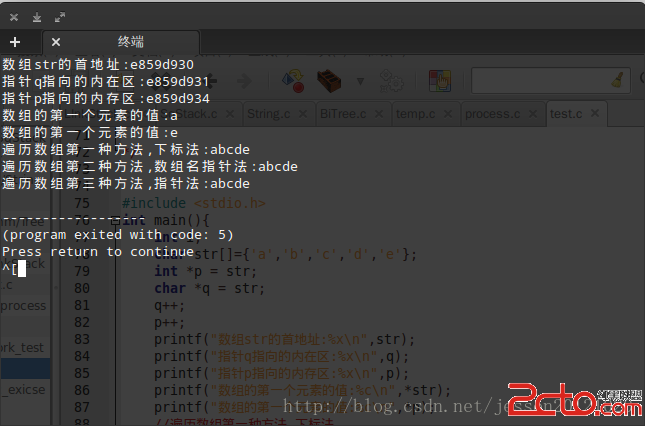
char str[]="hello";
char *p1=str;
此時,用sizeof(str)得到的是6,因為hell0是5個字符,系統儲存的時候會在hello的末尾加上結束標識\0,一共為6個字符;
而sizeof(p1)得到的卻是4,它求得的是指針變量p1的長度,在32位機器上,一個地址都是32位,即4個字節。
用sizeof(*p1)得到的是1,因為*p1定義為char,相當於一個字符,所以只占一個字節。
用strlen(str),得到的會是5,因為strlen求得的長度不包括最後的\0。
用strlen(p1),得到的是5,與strlen(str)等價。
上面的是sizeof和strlen的區別,也是 指針字符串和 數組字符串 的區別。
編程時這種錯誤非常隱秘,見下面的一個例子。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main( )
{
char *src="hello world";
char *dest=NULL;
int len=strlen(src);//這裡很容易出錯,寫成sizeof(src)就是求指針的長度,即4
dest=(char *)malloc(len+1);//這裡很容易出錯,寫成len
char *d=dest;
char *s=&src[len-1]; //這裡很容易出錯,寫成len
while(len--!=0)
*d++=*s--;
*d='\0'; //這句很容易漏寫
printf("%s\n", dest);
free(dest); //這句很容易漏寫
return 0;
}
注意,我上面這個C語言程序是在Linux平台下gcc編譯的,Windows平台下的VC6不支持即用即聲明的形式,必須先定義後使用。用VC6編譯可以改成下面的形式:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main( )
{
char *src, *dest, *d, *s;
int len;
src="hello world";
dest=NULL;
len=strlen(src);
dest=(char *)malloc(len+1);
d=dest;
s=&src[len-1];
while(len--!=0)
*d++=*s--;
*d='\0';
printf("%s\n", dest);
free(dest);
return 0;
}
首先說明一下malloc函數和free函數的使用www.2cto.com
#include <stdlib.h>
void *malloc( unsigned int size );
它的功能是在內存的動態存儲區分配一個長度為size字節的連續空間。函數返回的是一個指向分配域其實地址的指針,這個指針的類型是void類型。如果函數未能執行成功則返回一個空指針NULL,使用這個函數必須包含頭文件stdio.h。
void類型的指針,指向一個類型未定的變量,也就是說它可以指向char類型變量,也可以指向int類型或其它類型。因此在將它的值賦值給另外一個指針時要進行強制類型轉換,例如:
char *p1="123456";
void *p2="abcdef";
p1=(char *)p2;//兩者類型必須相同,也可以p2=(void *)p1;
malloc函數必須和free函數成對出現,使用完了free(dest);
2. 數組中易錯的地方
分析下面這段小程序:
#include<stdio.h>
void main()
{
int a[5]={1,2,3,4,5};
int *ptr=(int *)(&a+1);
printf("%d, %d\n", *(a+1), *(ptr-1));
}
以及下面這個程序:
#include <stdlib.h>
#include <stdio.h>
static void show_str_pointer(const char **ppstr)
{
printf("%s\n", *ppstr);
}
int main()
{
char array[4] = "abc";
char *pointer = "abc";
show_str_pointer(&pointer);
show_str_pointer(&array);
return 0;
}
執行結果為:
abc
7�
&array與array的語義相同。在這裡指針與數組是不能互換的。&pointer為指針的地址,與show_str_pointer參數char **ppstr指向指針的指針的變量類型相同。而&array仍然為數組地址,與參數char **ppstr的類型不符。
3. 數組的最大長度問題
int n[1000000];這樣肯定是不行的,因為這樣定義的數組用的是棧內存,系統默認值為最大1Mb,一個int型占4字節這樣最大可以申請1024*1024/4=264144個,如果考慮到系統自身的占用最大值約為25000個。
int *p=(int *)malloc(1000000*sizeof(int));,這樣用的是堆內存,只要你內存有那麼多的連續空間就可以。例子如下:
#include<stdio.h>
#include<malloc.h>
int main()
{
int *p=(int *)malloc(1000000*sizeof(int));
//int p[1000000];
int i=0;
for(;i<1000000;i++)
printf("%d\n",p[i]=i);
free(p);
return 0;
}
如果非要用數組的話,一般這樣寫,不能再大了:
#define MAXSIZE 250000
int a[MAXSIZE];
2. fscanf和fprintf函數
將文件中的數據讀出來存入指定的指針位置,例如fscanf (fp,"%d", &a[i]);
將數據存入文件中可以用fprintf函數,但是對於二進制文件,寫成fprintf(fp, "%d", a[i]);就不對,因為存入的是%d格式是十進制的,所以此時不要用fprintf,換成fwrite即可。
有關二進制文件的讀寫參加下面一個程序:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define DATASIZE 250000
int main(int argc, char ** argv)
{
const char * file_name = "out.dat";
FILE * fp = fopen(file_name, "wb");//必須放在其他變量的定義之前
int i, a, b[DATASIZE];
srand( time(NULL) );
for(i=0; i<DATASIZE; i++)
{
a=rand()%100;
fwrite(&a, sizeof(int), 1, fp);
}
fclose(fp);
fp = fopen(file_name, "rb");
fread(&b, sizeof(int), DATASIZE, fp);
for(i=0; i<200; i++)
printf("%d ", b[i]);
printf("\n");
return 0;
}
程序說明:隨機生成25萬個0~100的整數以二進制的形式存入文件out.dat中,然後再讀取文件out.dat中的整數挨個賦值給數組b[DATASIZE],最後打印出該數組的前200個數。
3. 遞歸棧空間溢出
我們知道快速排序通常是用遞歸算法寫的,雖然說號稱是速度最快的(其實也不是最快的),但是我排20萬個整數它就受不鳥了(貌似系統給棧空間分配的大小為2M或者8M,快速排序最壞情況下,遞歸深度為n,所需要的棧空間為O(n),一個整數4位32個字節,100W*32那就有30多M了,棧空間必定溢出),排18萬個整數的時候近似時間復雜度約為1.4億,運行了0.497秒,而VC6自帶庫函數裡面的那個qsort()要慢很多,用了1.942秒,堆排序只用了0.032秒(太給力了!),還有就是哥那個優化過的希爾排序,用了8.518秒,復雜度約為16億,傷不起啊!
我把快速排序稍微改進一下,用首中尾三者取中作為基准的辦法,速度肯定是提高了不少,但是可排序的元素個數銳減到了3萬個,4萬個元素都可能導致遞歸棧空間溢出,5萬個元素想都別想了,所以呀這個快速排序的極限是排3萬個元素。而當我用3萬個元素去測試的時候,快排用了0.169秒,堆排序用了0.006秒,快慢一眼明了。
當待排序的數據量比較大時,你就別想用什麼冒泡排序、直接選擇排序、直接插入排序等,效率太低了!最好是用堆排序。
補充一點:
遞歸算法的實現過程:是通過棧實現的,例如下面一個求階乘的算法:
int Fac(n)
int n;
{
if( n==1 ) return 1;
else return n*Fac(n-1);
}
系統最初是不會去計算的,它會在內存中開辟一個棧空間,假如說n=3,那麼首先3*Fac(2)入棧,占據棧底的位置,然後2*Fac(1)入棧,此時Fac(1)就不再遞歸了,所以沒有元素再入棧了,Fac(1)返回值1,然後2*Fac(1)、3*Fac(2)依次出棧,最終出棧的是數字6,這就是3的階乘。
由此可見,遞歸的函數越復雜,數據量越大,變量越多,那麼占用的棧空間就越大,因為棧的每一層都要保存這些,其實很多的重復的,但是依然保存了,只有到該層出棧的時候才釋放。編譯器就是這樣的,沒有太多的優化,內存開銷相當的大,所以——少用遞歸,慎用遞歸!
摘自 勁草...無香