指針的實質就是一個變量,其完整的名稱是指針變量,與普通的變量沒什麼區別。指針存儲的是地址,而普通變量存儲的是數值。
定義指針時的星號的位置不一樣從而有三種定義:(1)int * a; (2)int* a;(3)int *a;
我編寫了一下代碼來驗證以上的三種情況:
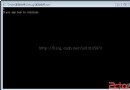
#includeint main(void) { int a=5; int *p1; int* p2; int * p3; p1 = &a; p2 = &a; p3 = &a; printf("*p1 = %d\n",*p1); printf("*p2 = %d\n",*p2); printf("*p3 = %d\n",*p3); return 0; }
在linux系統中利用terminal中的gcc交叉編譯工具來編譯和運行c代碼,運行結果如下圖所示:

結論:三種定義的運行結果一樣,故三種定義等價
關聯指針變量的兩種方法:(1)在定義指針時,初始化指針變量(2)指針變量= &變量
通過以上的兩種方法,可以將指針指向應該訪問的地方,如果沒對指針進行關聯,就訪問指針指向地址中的變量,會導致系統出現不可預料的嚴重後果。
星號在用於指針相關功能的時候有2種用法:第一種是指針定義時,*結合前面的類型用於表明要定義的指針的類型;第二種功能是指針解引用,解引用時*p表示p指向的變量本身
(1)C語言中*可以表示乘號,也可以表示指針符號。這兩個用法是毫無關聯的,只是恰好用了同一個符號而已。
(2)星號在用於指針相關功能的時候有2種用法:第一種是指針定義時,*結合前面的類型用於表明要定義的指針的類型;第二種功能是指針解引用,解引用時*p表示p指向的變量本身
取地址符使用時直接加在一個變量的前面,然後取地址符和變量加起來構成一個新的符號,這個符號表示這個變量的地址。
NULL在C/C++中定義為:
#ifdef _cplusplus // 定義這個符號就表示當前是C++環境 #define NULL 0 // 在C++中NULL就是0 #else #define NULL (void *)0 // 在C中NULL是強制類型轉換為void *的0 #endif
(1)放在賦值運算符左邊的就叫左值,右邊的就叫右值。所以賦值操作其實就是:左值= 右值;
(2)當一個變量做左值時,編譯器認為這個變量符號的真實含義是這個變量所對應的那個內存空間;當一個變量做右值時,編譯器認為這個變量符號的真實含義是這個變量的值,也就是這個變量所對應的內存空間中存儲的那個數。
(3)左值與右值的區別,就好象現實生活中“家”這個字的含義。譬如“我回家了”,這裡面的家指的是你家的房子(類似於左值);但是說“家比事業重要”,這時候的家指的是家人(家人就是住在家所對應的那個房子裡面的人,類似於右值)
(1)因為指針變量在定義時如果未初始化,值也是隨機的。指針變量的值其實就是別的變量(指針所指向的那個變量)的地址,所以意味著這個指針指向了一個地址是不確定的變量,這時候去解引用就是去訪問這個地址不確定的變量,所以結果是不可知的。
(2)因為野指針指向地址是不可預知的,所以有3種情況:
第一種是指向不可訪問(操作系統不允許訪問的敏感地址,譬如內核空間)的地址,結果是觸發段錯誤,這種算是最好的情況了;
第二種是指向一個可用的、而且沒什麼特別意義的空間(譬如我們曾經使用過但是已經不用的棧空間或堆空間),這時候程序運行不會出錯,也不會對當前程序造成損害,這種情況下會掩蓋你的程序錯誤,讓你以為程序沒問題,其實是有問題的;
第三種情況就是指向了一個可用的空間,而且這個空間其實在程序中正在被使用(譬如說是程序的一個變量x),那麼野指針的解引用就會剛好修改這個變量x的值,導致這個變量莫名其妙的被改變,程序出現離奇的錯誤。一般最終都會導致程序崩潰,或者數據被損害。這種危害是最大的。
(1)野指針的錯誤來源就是指針定義了以後沒有初始化,也沒有賦值(總之就是指針沒有明確的指向一個可用的內存空間),然後去解引用。故在指針的解引用之前,一定確保指針指向一個絕對可用的空間。
(2)常規的做法是:
第一點:定義指針時,同時初始化為NULL
第二點:在指針使用之前,將其賦值綁定給一個可用地址空間
第三點:在指針解引用之前,先去判斷這個指針是不是NULL
第四點:指針使用完之後,將其賦值為NULL
#includeint main(void) { int a; int *p = NULL;//第一點:定義指針時,同時初始化為NULL *p = &a; //第二點:在指針使用之前,將其賦值綁定給一個可用地址空間 if(NULL!=p)//第三點:在指針解引用之前,先去判斷這個指針是不是NULL { ..... p = NULL; //第四點:指針使用完之後,將其賦值為NULL } return 0; }
1. const修飾指針的4種形式
第一種:const int *p;
第二種:int const *p;
第三種:int * const p;
第四種:const int * const p;
指針變量涉及到2個變量:第一個是指針變量p本身,第二個是p指向的那個變量(*p)。一個const關鍵字只能修飾一個變量,所以弄清楚這4個表達式的關鍵就是搞清楚const放在某個位置是修飾誰的。
(1)const int *p 或者int const *p
p指向的變量是const常量
(2)int * const p 或者 const int * const p
p本身是const常量,p指向的變量也是const常量
(1)從內存角度講,數組變量就是一次分配多個變量,而且這多個變量在內存中的存儲單元是依次相連接的。
(2)我們分開定義多個變量(譬如int a, b, c, d;)和一次定義一個數組(int a[4]);這兩種定義方法相同點是都定義了4個int型變量,而且這4個變量都是獨立的單個使用的;不同點是單獨定義時a、b、c、d在內存中的地址不一定相連,但是定義成數組後,數組中的4個元素地址肯定是依次相連的。
(3)數組中多個變量雖然必須單獨訪問,但是因為他們的地址彼此相連,因此很適合用指針來操作,因此數組和指針天生就叫糾結在一起。
(1)a就是數組名。
la做左值時表示整個數組的所有空間,又因為C語言規定數組操作時要獨立單個操作,不能整體操作數組,所以a不能做左值;
la做右值表示數組首元素(數組的第0個元素,也就是a[0])的首地址(首地址就是起始地址,就是最開始第一個字節的地址)。a做右值等同於&a[0];
(2)a[0]表示數組的首元素,也就是數組的第0個元素。
la[0]做左值時表示數組第0個元素對應的內存空間(連續4字節);
la[0]做右值時表示數組第0個元素的值(也就是數組第0個元素對應的內存空間中存儲的那個數)
(3)&a就是數組名a取地址,字面意思來看就應該是數組的地址。
l&a不能做左值(&a實質是一個常量,不是變量因此不能賦值,所以自然不能做左值。);
l&a做右值時表示整個數組的首地址。
(4)&a[0]字面意思就是數組第0個元素的首地址(搞清楚[]和&的優先級,[]的優先級要高於&,所以a先和[]結合再取地址)。
l做左值時表示數組首元素對應的內存空間,做右值時表示數組首元素的值(也就是數組首元素對應的內存空間中存儲的那個數值)。
l做右值時&a[0]等同於a。
總結:
1:&a和a做右值時的區別:&a是整個數組的首地址,而a是數組首元素的首地址。這兩個在數字上是相等的,但是意義不相同。意義不相同會導致他們在參與運算的時候有不同的表現。
2:a和&a[0]做右值時意義和數值完全相同,完全可以互相替代。
3:&a是常量,不能做左值。
4:a做左值代表整個數組所有空間,所以a不能做左值。
因為數組是編譯器在內存中自動分配的。當我們每次執行程序時,運行時都會幫我們分配一塊內存給這個數組,只要完成了分配,這個數組的地址就定好了,本次程序運行直到終止都無法再改了。那麼我們在程序中只能通過&a來獲取這個分配的地址,卻不能去用賦值運算符修改它。
1.以指針方式來訪問數組元素
(1)數組元素使用時不能整體訪問,只能單個訪問。訪問方式有2種:數組形式和指針形式:
l數組格式訪問數組元素是:數組名[下標]; (注意下標從0開始)
l指針格式訪問數組元素是:*(指針+偏移量);
注:如果指針是數組首元素地址(a或者&a[0]),那麼偏移量就是下標;指針也可以不是首元素地址而是其他哪個元素的地址,這時候偏移量就要考慮疊加了。
數組下標方式和指針方式均可以訪問數組元素,兩者的實質其實是一樣的。在編譯器內部都是用指針方式來訪問數組元素的,數組下標方式只是編譯器提供給編程者一種殼(語法糖)而已。所以用指針方式來訪問數組才是本質的做法。
int *p; int a[5];p = a;//類型匹配
int *p; int a[5];p = &a;//類型不匹配。p是int *,&a是整個數組的指針,也就是一個數組指針類型,不是int指針類型,所以不匹配
總結:&a、a、&a[0]從數值上來看是完全相等的,但是意義來看就不同了。
l從意義來看,a和&a[0]是數組首元素首地址,而&a是整個數組的首地址
l從類型來看,a和&a[0]是元素的指針,也就是int *類型;而&a是數組指針,是int (*)[常量]類型。
(1)指針參與運算時,因為指針變量本身存儲的數值是表示地址的,所以運算也是地址的運算。
(2)指針參與運算的特點是,指針變量+1,並不是真的加1,而是加1*sizeof(指針類型);如果是int *指針,則+1就實際表示地址+4,如果是char *指針,則+1就表示地址+1;如果是double *指針,則+1就表示地址+8.
(1)所有的類型的數據存儲在內存中,都是按照二進制格式存儲的,即內存中只保存0和1。但是他們的存儲方式(數轉換成二進制往內存中放的方式)不一定相同。
(2)int、char、short等屬於整形,他們的存儲方式是相同的,只是占用的內存大小不同(所以這幾種整形就彼此叫二進制兼容格式);而float和double的存儲方式彼此不同,和整形更不同。
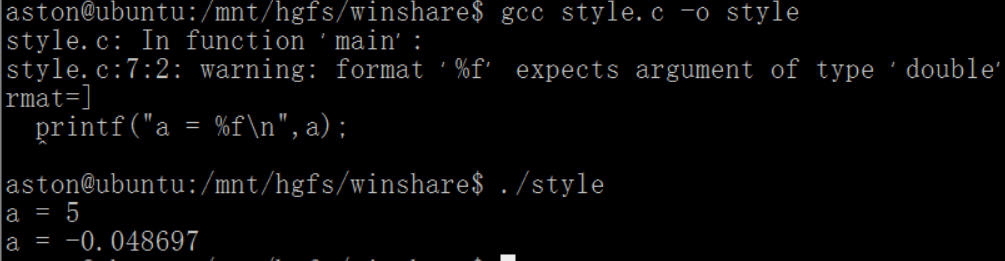
(3)當編譯代碼int a = 5;時,編譯器給a分配4字節空間,並且將5按照int類型的存儲方式轉成二進制存到a所對應的內存空間中去(a此時做左值);我們printf去打印a的時候(a此時做右值),采用%d或者%f的方式解析內存中二進制數值時,如果解析方式與存儲的方式相同,則能輸出正確的數值,如下面的代碼運行結果所示:
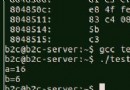
#include運行結果如下圖所示:int main(void) { int a = 5; printf("a = %d\n",a); printf("a = %f\n",a); return 0; }
分析幾個題目:
* 按照int類型存卻按照float類型取一定會出錯
* 按照int類型存卻按照char類型取有可能出錯也有可能不出錯
* 按照short類型存卻按照int類型取有可能出錯也有可能不出錯
* 按照float類型存卻按照double取一定會出錯
int和char類型都是整形,類型兼容的。int和char的不同在於char只有1個字節而int有4個字節,所以int的范圍比char大。在char所表示的范圍之內int和char是可以互轉的不會出錯;但是超過了char的范圍後char轉成int不會錯(向大方向轉就不會錯,就好比拿小瓶子的水往大瓶子倒不會漏掉不會丟掉),而從int到char轉就會出錯(就好象拿大瓶子水往小瓶子倒一樣)。
(1)指針的本質是:變量,指針就是指針變量
(2)一個指針涉及2個變量:一個是指針變量自己本身,一個是指針變量指向的那個變量
(3)int *p;定義指針變量時,p(指針變量本身)是int *類型,*p(指針指向的那個變量)是int類型的。
(4)int *類型說白了就是指針類型,只要是指針類型就都是占4字節,解析方式都是按照地址的方式來解析(意思是裡面存的32個二進制加起來表示一個內存地址)的。結論就是:所有的指針類型(不管是int * 還是char *還是double *)的解析方式是相同的,都是地址。
(5)指針所指向的那個變量的類型(它所對應的內存空間的解析方法)要取決於指針類型。譬如指針是int *的,那麼指針所指向的變量就是int類型的。
----------------文章未完,待後續更新----------------