好久沒寫過雙緩存了,趁現在有空重新溫習下。
我們經常聽說雙緩存,但是很少使用多緩存,起碼大多數情況下是這樣吧。為什麼不需要多緩沖呢,今天分析下。並不是緩沖區越多越好,這個需要考慮具體的應用場景。我們抽象假設一下應用場景,為了簡化場景,假設只有一個讀線程和一個寫線程,設讀時間為rt,寫時間為wt,有三種情況:
1、當 rt==wt時,也就是說,讀時間等於寫時間。這時候,開辟幾個緩沖區好呢,應該是兩個。看以下時間圖(圖畫得水,看得懂就好)
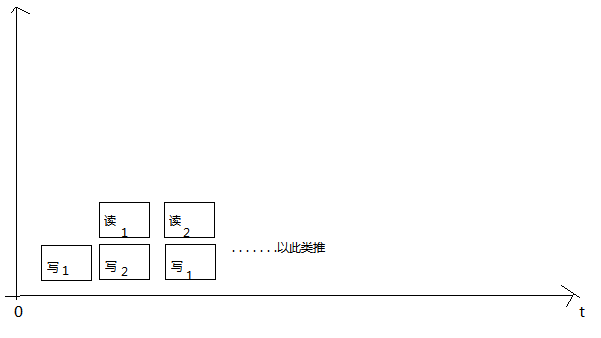
重上面的圖可以看出,從寫1開始,寫1完成後,讀1開始同時寫2,當讀1完成時寫2正好也完成,因此理論上,這重情況下使用雙緩存就可以了。
2、當rt>wt時,即讀快於寫,也就是讀的時間小於寫的時間,那麼這時候應該使用幾個緩存呢?理論上應該不超過兩個,看以下時間圖
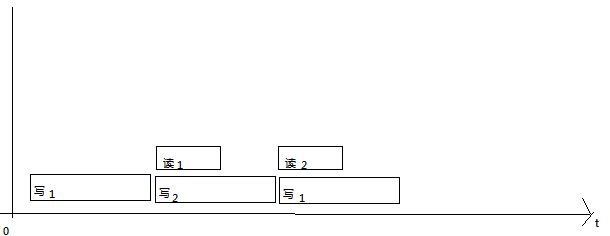
寫的時間比讀的長,寫1開始,寫1完成後,讀1開始時同時開始寫2。當讀1完成時,寫2還沒寫完,所以這時候,即使有再多的緩存也沒用(這裡不考慮多線程寫),所以最多有兩個緩存就夠了。為了搞高性能,這裡最好使用多線程寫,當然了,要是多核cpu。
3、當rt<wt時,即寫快於讀,這時候理論上應該設置2到3個緩存區就夠了。看圖
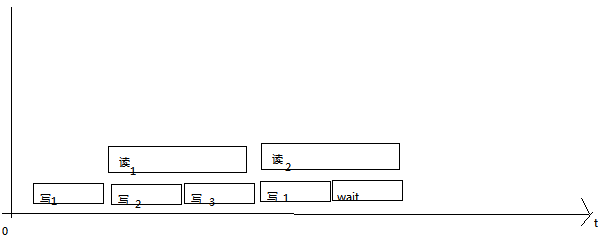
這個就不解釋了,因為前面有,都類似,讀得慢,寫的再快也沒有多大意義(除了占空間)。
有考慮不到的情景,請多多指教,謝謝!上個代碼:代碼裡對_read_list和_write_list進行上鎖操作,只是為了同時滿足那三種時間關系。若已確定了是哪兩種模型,可以去掉鎖采用更快的方法
char buffer1[1024];
char buffer2[1024];
std::vector<char*> _buffer_list;
std::vector<int> _read_list; // 可讀緩存下標集合
std::vector<int> _write_list;// 可寫緩存下標集合
std::mutex _mutex; // 同步鎖
std::atomic<bool> _stopflag(false); // 全局停工標志
void thread_read(Event* _er,Event* _ew)
{
while(!_stopflag)
{
// 等待讀
if (_er->wait_for(std::chrono::milliseconds(2000)))
{
while(true)
{
// 檢查可讀緩存的下標集合
int idx = -1;
_mutex.lock();
if (!_read_list.empty())
{
idx = *_read_list.begin();
_read_list.erase(_read_list.begin());
}
_mutex.unlock();
if (idx==-1)
{
break;
}
// 進行寫
char* pbuffer = _buffer_list[idx];
cout << pbuffer << endl;
// 模擬讀很慢
//Sleep(500);
// 加入可寫,上鎖
_mutex.lock();
_write_list.push_back(idx);
_mutex.unlock();
// 通知可寫
_ew->notify_all();
}
}
// do other
}
}
void thread_write(Event* _er,Event* _ew)
{
int global = 0;
while(!_stopflag)
{
// 等待寫
if (_ew->wait_for(std::chrono::milliseconds(2000)))
{
while(true)
{
// 檢查可寫緩存的下標集合
int idx = -1;
_mutex.lock();
if (!_write_list.empty())
{
idx = *_write_list.begin();
_write_list.erase(_write_list.begin());
}
_mutex.unlock();
if (idx==-1)
break;
// 進行寫
char* pbuffer = _buffer_list[idx];
memset(pbuffer,0,1024);
sprintf(pbuffer,
"this is threadid %i write %i buffer %i times",
std::this_thread::get_id().hash(),
idx,
++global);
// 加入可讀
_mutex.lock();
_read_list.push_back(idx);
_mutex.unlock();
// 通知可讀
_er->notify_all();
}
}
// do other
}
}
int main()
{
_buffer_list.push_back(buffer1);
_buffer_list.push_back(buffer2);
Event event_read,event_write;
std::list<std::thread> _list_thr;
// 讀線程
_list_thr.push_back(std::thread(thread_read,&event_read,&event_write));
// 寫線程
_list_thr.push_back(std::thread(thread_write,&event_read,&event_write));
system("pause");
// 開始時,全部緩存可寫
for (size_t i=0; i<_buffer_list.size(); ++i)
_write_list.push_back(i);
//通知寫
event_write.notify_once();
system("pause");
_stopflag = true;
for (auto& thr : _list_thr)
thr.join();
return 0;
}