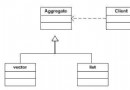
sizeof
sizeof操作符的作用是返回一個對象或類型名的長度,長度的單位是字節。
返回值的類型是標准庫命名為size_t的類型,size_t類型定義在cstddef頭文件中,該頭文件是C標准庫的頭文件stddef.h的C++版本。他是一個和
機器相關的unsigned類型,其大小足以保證內存中對象的大小。
1、什麼是sizeof
首先看一下sizeof在msdn上的定義:
The sizeof keyword gives the amount of storage, in bytes, associated
with a variable or a type (including aggregate types). This keyword
returns a value of type size_t.
看到return這個字眼,是不是想到了函數?錯了,sizeof
不是一個函數,你見過給一個函數傳參數,而不加括號的嗎?sizeof可以,所以sizeof不是函數。網上有人說sizeof是一元操作符,但是我並不
這麼認為,因為sizeof更像一個特殊的宏,它是在編譯階段求值的。舉個例子:
在編譯階段已經被翻譯為:
這裡有個陷阱,看下面的程序:
輸出為什麼是4,0而不是期望中的4,3???就在於sizeof在編譯階段處理的特性。由於sizeof不能被編譯成機器碼,所以sizeof作用范
圍內,也就是()裡面的內容也不能被編譯,而是被替換成類型。=操作符返回左操作數的類型,所以a=3相當於int,而代碼也被替換為:
所以,sizeof是不可能支持鏈式表達式的,這也是和一元操作符不一樣的地方。
結論:不要把sizeof當成函數,也不要看作一元操作符,把他當成一個特殊的編譯預處理。
2、sizeof的用法
sizeof有兩種用法:
(1)sizeof(object)
也就是對對象使用sizeof,也可以寫成sizeof object 的形式。
(2)sizeof(typename)
也就是對類型使用sizeof,注意這種情況下寫成sizeof typename是非法的。下面舉幾個例子說明一下:
可以看出,加()是永遠正確的選擇。
結論:不論sizeof要對誰取值,最好都加上()。
3、數據類型的sizeof
(1)C++固有數據類型
32位C++中的基本數據類型,也就char,short int(short),int,long int(long),float,double, long double
大小分別是:1,2,4,4,4,8, 10。
考慮下面的代碼:
unsigned影響的只是最高位bit的意義,數據長度不會被改變的。
結論:unsigned不能影響sizeof的取值。
(2)自定義數據類型
typedef可以用來定義C++自定義類型。考慮下面的問題:
結論:自定義類型的sizeof取值等同於它的類型原形。
(3)函數類型
考慮下面的問題:
結論:對函數使用sizeof,在編譯階段會被函數返回值的類型取代,
4、指針問題
考慮下面問題:
可以看到,不管是什麼類型的指針,大小都是4的,因為指針就是32位的物理地址。
結論:只要是指針,大小就是4。(64位機上要變成8也不一定)。
順便唧唧歪歪幾句,C++中的指針表示實際內存的地址。和C不一樣的是,C++中取消了模式之分,也就是不再有small,middle,big,取而
代之的是統一的flat。flat模式采用32位實地址尋址,而不再是c中的 segment:offset模式。舉個例子,假如有一個指向地址
f000:8888的指針,如果是C類型則是8888(16位,
只存儲位移,省略段),far類型的C指針是f0008888(32位,高位保留段地址,地位保留位移),C++類型的指針是f8888(32位,相當於
段地址*16 + 位移,但尋址范圍要更大)。
5、數組問題
考慮下面問題:
數組a的大小在定義時未指定,編譯時給它分配的空間是按照初始化的值確定的,也就是7。c是多維數組,占用的空間大小是各維數的乘積,也就是6。可以看出,數組的大小就是他在編譯時被分配的空間,也就是各維數的乘積*數組元素的大小。
結論:數組的大小是各維數的乘積*數組元素的大小。
這裡有一個陷阱:
d是我們常說的動態數組,但是他實質上還是一個指針,所以sizeof(d)的值是4。
再考慮下面的問題:
a是一個很奇怪的定義,他表示一個指向 double*[3][6]類型數組的指針。既然是指針,所以sizeof(a)就是4。
既然a是執行double*[3][6]類型的指針,*a就表示一個double*[3][6]的多維數組類型,因此
sizeof(*a)=3*6*sizeof(double*)=72。同樣的,**a表示一個double*[6]類型的數組,所以
sizeof(**a)=6*sizeof(double*)=24。***a就表示其中的一個元素,也就是double*了,所以
sizeof(***a)=4。至於****a,就是一個double了,所以sizeof(****a)=sizeof(double)=8。
6、向函數傳遞數組的問題
考慮下面的問題:
c語言中判斷數據類型長度符
用法
sizeof(類型說明符,數組名或表達式);
或
sizeof 變量名
1. 定義:
sizeof是C/C++中的一個操作符(operator)是也,簡單的說其作用就是返回一個對象或者類型所占的內存字節數。
MSDN上的解釋為:
The
sizeof keyword gives the amount of storage, in bytes, associated with a
variable or a type (including aggregate types). This keyword returns a
value of type size_t.
其返回值類型為size_t,在頭文件stddef.h中定義。這是一個依賴於編譯系統的值,一般定義為
typedef unsigned int size_t;
世上編譯器林林總總,但作為一個規范,它們都會保證char、signed char和unsigned
char的sizeof值為1,畢竟char是我們編程能用的最小數據類型。
2. 語法:
sizeof有三種語法形式,如下:
1) sizeof( object ); // sizeof( 對象 );
2) sizeof( type_name ); // sizeof( 類型 );
3) sizeof object; // sizeof 對象;
所以,
int i;
sizeof( i ); // ok
sizeof i; // ok
sizeof( int ); // ok
sizeof int; // error
既
然寫法3可以用寫法1代替,為求形式統一以及減少我們大腦的負擔,第3種寫法,忘掉它吧!實際上,sizeof計算對象的大小也是轉換成對對象類型的計
算,也就是說,同種類型的不同對象其sizeof值都是一致的。這裡,對象可以進一步延伸至表達式,即sizeof可以對一個表達式求值,編譯器根據表達
式的最終結果類型來確定大小,一般不會對表達式進行計算。如:
sizeof( 2 ); // 2的類型為int,所以等價於 sizeof( int );
sizeof( 2 + 3.14 ); // 3.14的類型為double,2也會被提升成double類型,所以等價於 sizeof( double );
sizeof也可以對一個函數調用求值,其結果是函數返回類型的大小,函數並不會被調用,我們來看一個完整的例子:
char foo()
{
printf("foo() has been called./n");
return 'a';
}
int main()
{
size_t sz = sizeof( foo() ); // foo() 的返回值類型為char,所以sz = sizeof(char ),foo()並不會被調用
printf("sizeof( foo() ) = %d/n", sz);
}
C99標准規定,函數、不能確定類型的表達式以及位域(bit-field)成員不能被計算sizeof值,即下面這些寫法都是錯誤的:
sizeof( foo );// error
void foo2() { }
sizeof( foo2() );// error
struct S
{
unsigned int f1 : 1;
unsigned int f2 : 5;
unsigned int f3 : 12;
};
sizeof( S.f1 );// error
3. sizeof的常量性
sizeof的計算發生在編譯時刻,所以它可以被當作常量表達式使用,如:
char ary[ sizeof( int ) * 10 ]; // ok
最新的C99標准規定sizeof也可以在運行時刻進行計算,如下面的程序在Dev-C++中可以正確執行:
int n;
n = 10; // n動態賦值
char ary[n]; // C99也支持數組的動態定義
printf("%d/n", sizeof(ary)); // ok. 輸出10
但在沒有完全實現C99標准的編譯器中就行不通了,上面的代碼在VC6中就通不過編譯。所以我們最好還是認為sizeof是在編譯期執行的,這樣不會帶來錯誤,讓程序的可移植性強些。
4. 基本數據類型的sizeof
這裡的基本數據類型指short、int、long、float、double這樣的簡單內置數據類型,由於它們都是和系統相關的,所以在不同的系統下取值可能不同,這務必引起我們的注意,盡量不要在這方面給自己程序的移植造成麻煩。
一般的,在32位編譯環境中,sizeof(int)的取值為4。
5. 指針變量的sizeof
學
過數據結構的你應該知道指針是一個很重要的概念,它記錄了另一個對象的地址。既然是來存放地址的,那麼它當然等於計算機內部地址總線的寬度。所以在32位
計算機中,一個指針變量的返回值必定是4(注意結果是以字節為單位),可以預計,在將來的64位系統中指針變量的sizeof結果為8。
char* pc = "abc";
int* pi;
string* ps;
char** ppc = &pc;
void (*pf)();// 函數指針
sizeof( pc ); // 結果為4
sizeof( pi ); // 結果為4
sizeof( ps ); // 結果為4
sizeof( ppc ); // 結果為4
sizeof( pf );// 結果為4
指針變量的sizeof值與指針所指的對象沒有任何關系,正是由於所有的指針變量所占內存大小相等,所以MFC消息處理函數使用兩個參數WPARAM、LPARAM就能傳遞各種復雜的消息結構(使用指向結構體的指針)。
6. 數組的sizeof
數組的sizeof值等於數組所占用的內存字節數,如:
char a1[] = "abc";
int a2[3];
sizeof( a1 ); // 結果為4,字符 末尾還存在一個NULL終止符
sizeof( a2 ); // 結果為3*4=12(依賴於int)
一些朋友剛開始時把sizeof當作了求數組元素的個數,現在,你應該知道這是不對的,那麼應該怎麼求數組元素的個數呢Easy,通常有下面兩種寫法:
int c1 = sizeof( a1 ) / sizeof( char ); // 總長度/單個元素的長度
int c2 = sizeof( a1 ) / sizeof( a1[0] ); // 總長度/第一個元素的長度
寫到這裡,提一問,下面的c3,c4值應該是多少呢
void foo3(char a3[3])
{
int c3 = sizeof( a3 ); // c3 ==
}
void foo4(char a4[])
{
int c4 = sizeof( a4 ); // c4 ==
}
也
許當你試圖回答c4的值時已經意識到c3答錯了,是的,c3!=3。這裡函數參數a3已不再是數組類型,而是蛻變成指針,相當於char*
a3,為什麼仔細想想就不難明白,我們調用函數foo1時,程序會在棧上分配一個大小為3的數組嗎不會!數組是“傳址”的,調用者只需將實參的地址傳遞過
去,所以a3自然為指針類型(char*),c3的值也就為4。
7. 結構體的sizeof
這是初學者問得最多的一個問題,所以這裡有必要多費點筆墨。讓我們先看一個結構體:
struct S1
{
char c;
int i;
};
問sizeof(s1)等於多少聰明的你開始思考了,char占1個字節,int占4個字節,那麼加起來就應該是5。是這樣嗎你在你機器上試過了嗎也許你是對的,但很可能你是錯的!VC6中按默認設置得到的結果為8。
Why為什麼受傷的總是我
請不要沮喪,我們來好好琢磨一下sizeof的定義——sizeof的結果等於對象或者類型所占的內存字節數,好吧,那就讓我們來看看S1的內存分配情況:
S1 s1 = { 'a', 0xFFFFFFFF };
定義上面的變量後,加上斷點,運行程序,觀察s1所在的內存,你發現了什麼
以我的VC6.0為例,s1的地址為0x0012FF78,其數據內容如下:
0012FF78: 61 CC CC CC FF FF FF FF
發現了什麼怎麼中間夾雜了3個字節的CC看看MSDN上的說明:
When
applied to a structure type or variable, sizeof returns the actual
size, which may include padding bytes inserted for alignment.
原來如此,這就是傳說中的字節對齊啊!一個重要的話題出現了。
為
什麼需要字節對齊計算機組成原理教導我們這樣有助於加快計算機的取數速度,否則就得多花指令周期了。為此,編譯器默認會對結構體進行處理(實際上其它地方
的數據變量也是如此),讓寬度為2的基本數據類型(short等)都位於能被2整除的地址上,讓寬度為4的基本數據類型(int等)都位於能被4整除的地
址上,以此類推。這樣,兩個數中間就可能需要加入填充字節,所以整個結構體的sizeof值就增長了。
讓我們交換一下S1中char與int的位置:
struct S2
{
int i;
char c;
};
看看sizeof(S2)的結果為多少,怎麼還是8再看看內存,原來成員c後面仍然有3個填充字節,這又是為什麼啊別著急,下面總結規律。
字節對齊的細節和編譯器實現相關,但一般而言,滿足三個准則:
1) 結構體變量的首地址能夠被其最寬基本類型成員的大小所整除;
2) 結構體每個成員相對於結構體首地址的偏移量(offset)都是成員大小的整數倍,如有需要編譯器會在成員之間加上填充字節(internal adding);
3) 結構體的總大小為結構體最寬基本類型成員大小的整數倍,如有需要編譯器會在最末一個成員之後加上填充字節(trailing padding)。
對於上面的准則,有幾點需要說明:
1) 前面不是說結構體成員的地址是其大小的整數倍,怎麼又說到偏移量了呢因為有了第1點存在,所以我們就可以只考慮成員的偏移量,這樣思考起來簡單。想想為什麼。
結構體某個成員相對於結構體首地址的偏移量可以通過宏offsetof()來獲得,這個宏也在stddef.h中定義,如下:
#define offsetof(s,m) (size_t)&(((s *)0)->m)
例如,想要獲得S2中c的偏移量,方法為
size_t pos = offsetof(S2, c);// pos等於4
2)
基本類型是指前面提到的像char、short、int、float、double這樣的內置數據類型,這裡所說的“數據寬度”就是指其sizeof的大
小。由於結構體的成員可以是復合類型,比如另外一個結構體,所以在尋找最寬基本類型成員時,應當包括復合類型成員的子成員,而不是把復合成員看成是一個整
體。但在確定復合類型成員的偏移位置時則是將復合類型作為整體看待。
這裡敘述起來有點拗口,思考起來也有點撓頭,還是讓我們看看例子吧(具體數值仍以VC6為例,以後不再說明):
struct S3
{
char c1;
S1 s;
char c2;
};
S1的最寬簡單成員的類型為int,S3在考慮最寬簡單類型成員時是將S1“打散”看的,所以S3的最寬簡單類型為int,這樣,通過S3定義的變量,其存儲空間首地址需要被4整除,整個sizeof(S3)的值也應該被4整除。
c1
的偏移量為0,s的偏移量呢這時s是一個整體,它作為結構體變量也滿足前面三個准則,所以其大小為8,偏移量為4,c1與s之間便需要3個填充字節,而
c2與s之間就不需要了,所以c2的偏移量為12,算上c2的大小為13,13是不能被4整除的,這樣末尾還得補上3個填充字節。最後得到
sizeof(S3)的值為16。
通過上面的敘述,我們可以得到一個公式:
結構體的大小等於最後一個成員的偏移量加上其大小再加上末尾的填充字節數目,即:
sizeof( struct ) = offsetof( last item ) + sizeof( last item ) + sizeof( trailing padding )
到
這裡,朋友們應該對結構體的sizeof有了一個全新的認識,但不要高興得太早,有一個影響sizeof的重要參量還未被提及,那便是編譯器的pack指
令。它是用來調整結構體對齊方式的,不同編譯器名稱和用法略有不同,VC6中通過#pragma
pack實現,也可以直接修改/Zp編譯開關。#pragma pack的基本用法為:#pragma pack( n
),n為字節對齊數,其取值為1、2、4、8、16,默認是8,如果這個值比結構體成員的sizeof值小,那麼
該成員的偏移量應該以此值為准,即是說,結構體成員的偏移量應該取二者的最小值,
公式如下:
offsetof( item ) = min( n, sizeof( item ) )
再看示例:
#pragma pack(push) // 將當前pack設置壓棧保存
#pragma pack(2) // 必須在結構體定義之前使用
struct S1
{
char c;
int i;
};
struct S3
{
char c1;
S1 s;
char c2;
};
#pragma pack(pop) // 恢復先前的pack設置
計算sizeof(S1)時,min(2, sizeof(i))的值為2,所以i的偏移量為2,加上sizeof(i)等於6,能夠被2整除,所以整個S1的大小為6。
同樣,對於sizeof(S3),s的偏移量為2,c2的偏移量為8,加上sizeof(c2)等於9,不能被2整除,添加一個填充字節,所以sizeof(S3)等於10。
現在,朋友們可以輕松的出一口氣了,:)
還有一點要注意,“空結構體”(不含數據成員)的大小不為0,而是1。試想一個“不占空間”的變量如何被取地址、兩個不同的“空結構體”變量又如何得以區分呢於是,“空結構體”變量也得被存儲,這樣編譯器也就只能為其分配一個字節的空間用於占位了。如下:
struct S5 { };
sizeof( S5 ); // 結果為1
8. 含位域結構體的sizeof
前面已經說過,位域成員不能單獨被取sizeof值,我們這裡要討論的是含有位域的結構體的sizeof,只是考慮到其特殊性而將其專門列了出來。
C99規定int、unsigned int和bool可以作為位域類型,但編譯器幾乎都對此作了擴展,允許其它類型類型的存在。使用位域的主要目的是壓縮存儲,其大致規則為:
1) 如果相鄰位域字段的類型相同,且其位寬之和小於類型的sizeof大小,則後面的字段將緊鄰前一個字段存儲,直到不能容納為止;
2) 如果相鄰位域字段的類型相同,但其位寬之和大於類型的sizeof大小,則後面的字段將從新的存儲單元開始,其偏移量為其類型大小的整數倍;
3) 如果相鄰的位域字段的類型不同,則各編譯器的具體實現有差異,VC6采取不壓縮方式,Dev-C++采取壓縮方式;
4) 如果位域字段之間穿插著非位域字段,則不進行壓縮;
5) 整個結構體的總大小為最寬基本類型成員大小的整數倍。
還是讓我們來看看例子。
示例1:
struct BF1
{
char f1 : 3;
char f2 : 4;
char f3 : 5;
};
其內存布局為:
|_f1__|__f2__|_|____f3___|____|
|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|
0 3 7 8 1316
位域類型為char,第1個字節僅能容納下f1和f2,所以f2被壓縮到第1個字節中,而f3只
能從下一個字節開始。因此sizeof(BF1)的結果為2。
示例2:
struct BF2
{
char f1 : 3;
short f2 : 4;
char f3 : 5;
};
由於相鄰位域類型不同,在VC6中其sizeof為6,在Dev-C++中為2。
示例3:
struct BF3
{
char f1 : 3;
char f2;
char f3 : 5;
};
非位域字段穿插在其中,不會產生壓縮,在VC6和Dev-C++中得到的大小均為3。
9. 聯合體的sizeof
結構體在內存組織上是順序式的,聯合體則是重疊式,各成員共享一段內存,所以整個聯合體的sizeof也就是每個成員sizeof的最大值。結構體的成員也可以是復合類型,這裡,復合類型成員是被作為整體考慮的。
所以,下面例子中,U的sizeof值等於sizeof(s)。
union U
{
int i;
char c;
S1 s;
};
1.逗號操作符
逗號表達式是一組由逗號分割的表達式,這些表達式從左向右計算。逗號表達式的結果是其最右邊表達式的值。如果最右邊的操作數
是左值,則逗號表達式的值也是左值。此類表達式通常用於for循環:
int cnt = ivec.size();
for(vector<int>::size_type ix = 0; ix != ivec.size(); ++size, --cnt)
{
ivec[ix] = cnt;
}
上述的for語句在循環表達式中使ix自增1而cnt自減1.每次循環均要修改ix和cnt的值。當檢驗ix的條件判斷成立時,程序將下一個元素
重新設置為出cnt的當前值。
2.三目(元)運算符 ( ? : )
max = (a > b) ? a: b
if(a>b) max = a;
else max = b;
x>y ? 1:1.5 將1轉化為雙精度型
3.函數
(1) 內置函數:
調用函數需要一定的時間和空間開銷。C++提供一種提高效率的方法,即在編譯時講鎖調用函數代碼直接鑲入到主函數中,這種嵌入
到主函數中的函數稱為內置函數。
注:那些規模較小而又被頻繁調用的簡單函數,才適合於聲明為inine函數。
(2) 函數的重載
重載函數的函數名相同,參數個數,參數類型,參數順序至少有一個不同
(3) 函數模板
函數模板適用於函數體相同,函數的參數個數相同而類型不同的情況
template <typename T> //模板聲明,其中T為類型參數 也可以用template <class T>
T max(T a ,T b, T c) //定義一個通用函數,用T做虛擬的函數名
{
if(b>a) a=b;
if(c>a) a=c;
return a;
}
類型參數可以不只一個,可以根據需要確定個數