大小寫轉換和性能
前言
本文主要討論最基本的一些大小寫轉換函數和API,不討論一些常見的字符串程序庫裡面的大小寫轉換接口,另外本文的落腳點是這些轉換函數的性能和日常開發中遇到的一些問題。
不考慮范圍
其實ctype.h裡面有定義一套宏,就是不考慮字符是否落在A-Z,a-z范圍,直接計算(直接用加減法或者使用位與或計算,差別不是很大)。顯然這樣的效率是最高的,但是使用可能是有問題的,遇到中文或者其他友邦的一些字符,可能就轉換錯了,當然如果已經提前確認過輸入會落在A-Z,a-z范圍,則是可以使用這種方法計算的。
#define _tolower(_Char) ( (_Char)-'A'+'a' )
#define _toupper(_Char) ( (_Char)-'a'+'A' )
C庫(MS)
轉小寫
tolower
towlower
_tolower_l
_towlower_l
轉大寫
toupper
towupper
_toupper_l
_towupper_l
C庫沒有提供直接轉換整個字符串的函數,都只能轉換單個字符。另外要注意的是提供的towlower和towupper這兩個函數效率出奇的低,為什麼效率低沒有去深究,反正tolower和toupper的參數是int,也可以用於寬字符版本,不知道為什麼還提供towlower和towupper這兩個函數。
C++庫(MS)
轉小寫
errno_t _strlwr_s(char* str, size_t numberOfElements);
errno_t _wcslwr_s(wchar_t* str, size_t numberOfElements);
轉大寫
errno_t _strupr_s(char* str, size_t numberOfElements);
errno_t _wcsupr_s(wchar_t* str, size_t numberOfElements);
同時還提供了一套同名的模版函數,可以直接只傳遞字符數組名進行轉換,原理是利用數組引用推導出了數組大小,再調用原始轉換函數,微軟在字符串處理函數裡面,使用了很多類似的小技巧(crtdefs.h)。
注:帶_s後綴的表示是安全轉換。
__DEFINE_CPP_OVERLOAD_SECURE_FUNC_0_0(errno_t, _wcslwr_s, __inout_ecount(_Size)wchar_t, _String)
#define __DEFINE_CPP_OVERLOAD_SECURE_FUNC_0_0(_ReturnType, _FuncName,_DstType, _Dst) \
extern "C++" \
{ \
template
inline \
_ReturnType __CRTDECL _FuncName(_DstType (&_Dst)[_Size])\
{ \
return _FuncName(_Dst, _Size);\
} \
}
Windows API
轉小寫
CharLower
CharLowerBuff
轉大寫
CharUpper
CharUpperBuff
WindowsAPI大部分都是一些宏,對應的多字節版本和寬字符版本在上面的API後面加上A和W。
STL庫
STL裡面的string沒有提供專門的轉換接口,但是借助STL裡面的算法用類似下面的方法實現(轉換函數可以自定義,也可以使用系統提供的函數),這個不多說。
transform(strCostInfo2.begin(), strCostInfo2.end(), strCostInfo2.begin(),::tolower);
transform(strCostInfo2.begin(), strCostInfo2.end(), strCostInfo2.begin(),::toupper);
自己實現(考慮范圍)
//////////////////////////////////////////////////////////////////////////
static const char s_ch_a_minus_A = 'a' - 'A';
inline char ConvToUpperA(char chConv)
{
return (chConv >= 'a' && chConv <= 'z')? (chConv & 0xdf) : chConv;
}
inline wchar_t ConvToUpperW(wchar_t wchConv)
{
return (wchConv >= L'a' && wchConv<= L'z') ? (wchConv & 0x00df) : wchConv;
}
inline char ConvToLowerA(char chConv)
{
return (chConv >= 'A' && chConv <= 'Z')? (chConv | 0x20) : chConv;
}
inline wchar_t ConvToLowerW(wchar_t wchConv)
{
return (wchConv >= L'A' && wchConv<= L'Z') ? (wchConv | 0x0020) : wchConv;
}
inline void ConvStrToUpperA(char* strConv)
{
for (size_t i = 0; strConv[i] != '\0'; ++i)
{
//if(strConv[i] >= 'a'&& strConv[i] <= 'z')
// strConv[i] &= 0xdf;
strConv[i] = ConvToUpperA(strConv[i]);
}
}
inline void ConvStrToUpperW(wchar_t* strConv)
{
for (size_t i = 0; strConv[i] != L'\0'; ++i)
{
//if(strConv[i] >=L'a' && strConv[i] <= L'z')
// strConv[i] &= 0x00df;
strConv[i] = ConvToUpperW(strConv[i]);
}
}
inline void ConvStrToLowerA(char* strConv)
{
for (size_t i = 0; strConv[i] != '\0'; ++i)
{
//if(strConv[i] >= 'A'&& strConv[i] <= 'Z')
// strConv[i]|= 0x20;
strConv[i] = ConvToLowerA(strConv[i]);
}
}
inline void ConvStrToLowerW(wchar_t* strConv)
{
for (size_t i = 0; strConv[i] != L'\0'; ++i)
{
//if(strConv[i] >=L'A' && strConv[i] <= L'Z')
// strConv[i] |= 0x0020;
strConv[i] = ConvToLowerW(strConv[i]);
}
}
和直接轉換的區別就在於只對A-Z,a-z范圍的字符進行轉換,有一定局限性,但是在大部分場景下是可用的,而且效率夠好。
性能
說了這麼多轉換方法,其實我最關心的那種方法的效率最高,直接上測試程序和測試環境吧,讓數據說話。
測試環境
Windows7 x64 SP1
AMD Phenom(tm) II X4 840T(4核)
10G內存
測試基本方法
對長度1024字節(不包括結尾0)的字符串進行大小寫輪換轉換,循環百萬次,統計時間。
測試結果
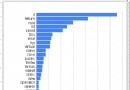
====>大小寫轉換函數時間消耗(循環1000000次)<====
直接計算(不考慮范圍):[1077] 毫秒
C庫函數:[6193]毫秒
C++庫函數:[5912]毫秒
STL算法庫模版函數(自定義轉換):[3557] 毫秒
STL算法庫模版函數(系統轉換):[6146] 毫秒
自定義的函數:[3791] 毫秒
Windows API:[13884] 毫秒
====>大小寫轉換函數時間消耗(循環1000000次)<====
直接計算(不考慮范圍):[1076] 毫秒
C庫函數:[6272]毫秒
C++庫函數:[5865]毫秒
STL算法庫模版函數(自定義轉換):[3292] 毫秒
STL算法庫模版函數(系統轉換):[6053] 毫秒
自定義的函數:[3666] 毫秒
Windows API:[13790] 毫秒
多次測試結果表明,顯然不考慮范圍是最快的,但是可用場景太少,其次就是自定義的大小寫轉換函數了(像中文之類也沒有大小寫之說,只需要考慮有限的ascii字符),配合STL的容器和算法可以最大化效率。WindowsAPI的效率則比較低,當然效率低的原因並不是算法的問題,而是考慮的情況比較多,譬如要考慮本地化,考慮一些語種特殊的大小寫轉換問題等等。
在合適的場景下,使用自定義的大小寫轉換是完全足夠,研究這個花了大約半天時間,問題源於一個URL處理函數的性能問題,經過統計發現,這個函數的大量計算消耗在了URL轉小寫上面,經過改造之後,性能輕松提升60%。