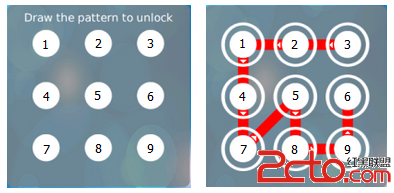
這幾天在看面試題目,與以前做acm的題目有不同的感覺。從題目題材上說acm由於不同客戶機的系統等有差異,所以一般都會選擇通用性的算法很少涉及本地的API之類的東西,同時acm很少對代碼內容做限制,更多的是要求時間復雜度和空間復雜度。而面試題目是在專用機器上做的,同時沒有標准化的輸入輸出,只要你能跑通即可,但是面試官可以對你的代碼做更多的要求,比如說只用一個變量,不能用庫函數,用某種系統的底層API等。這些使得平時我們的面試與acm有較大的差別,我看了leetcode上面的題目感覺跟面試題目的口味有點像,不過不知道他們是怎麼判正誤的,感覺是個不錯的平台。
下面的做法是把一個char變量(8位)分成上四位和下四位,上四位表示A的位置,下四位表示B的位置,明顯發現這裡的輸出都是用戶自定義的,在面試的時候沒有要求輸出,只需提供合理的一種思路即可。
#include <stdio.h>
#define HALF_BITS_LENGTH 4
//這個值是記憶存儲單元長度的一般,在這道題裡是4bit;
#define FULLMASK 255
//這個數字表示一個全部bit的mask,在二進制表示中,它是11111111
#define LMASK (FULLMASK<<HALF_BITS_LENGTH)
//這個宏表示一個左bit的mask,在二進制表示中,它是11110000、
//用宏的時候如果裡面有運算符,記得加括號
#define RMASK (FULLMASK>>HALF_BITS_LENGTH)
//這個宏表示一個左bit的mask,在二進制表示中,它是00001111、
#define RSET(b,n) (b=((LMASK&b)^n))
//這個宏將b的右邊設置成n;
#define LSET(b,n) (b=((RMASK&b)^(n<<HALF_BITS_LENGTH)))
//這個宏,將b的左邊設置成n;
#define RGET(b) (RMASK&b)
//這個宏得到b右邊的值;
#define LGET(b) ((LMASK&b)>>HALF_BITS_LENGTH)
//這個宏得到b左邊的值;
#define GRIDW 3
//grid的寬度,
//以上的作為給我們封裝數據結構提供了另外一種思路——使用宏定義
//以上的宏定義設置了一個數據結構,這個數據結構的變量為一個BITE,
//操作為對左半部分賦值和右半部分賦值,以及分別獲得左右兩部分的值;
//這裡用了抽象和分層設計其中RSET LSET RGET LGET GRIDW直接作為應用宏供調用
//LMASK RMASK 為抽象出來的第二層宏,FULLMASK和HASL_BITS_LENGTH 為底層調用。
//這個設計思路肯定是自上向下的,而不是自下向上。
int main()
{
unsigned char b;//使用unsigned可以獲取一個8位數字;
for(LSET(b,1);LGET(b)<=GRIDW*GRIDW;LSET(b,(LGET(b)+1)))
for(RSET(b,1);RGET(b)<=GRIDW*GRIDW;RSET(b,(RGET(b)+1)))
if(LGET(b)%GRIDW!=RGET(b)%GRIDW)
printf("A=%d,B=%d\n",LGET(b),RGET(b));
return 0;
}
posA*9+posB取遍(0-80) 並且每對位置與唯一的一個值一一對應,這個是個很重要的思路,把兩個值的關系映射到一個坐標軸上。
C語言中可以使用unsigned char 來表示一個字節的整數,所以char型本質上也是整數類型。看吧,這裡是倒序輸出了數據對 依然沒有什麼大礙。
#include <stdio.h>
int main()
{
unsigned char b = 81;
while(b--)
{
if(b/9%3!=b%9%3)
printf("A=%d,B=%d\n",b/9%3+1,b%9%3+1);
}
return 0;
}
這裡使用了結構體共用字節的特點。
#include <stdio.h>
int main()
{
struct{
unsigned char a:4;
unsigned char b:4;
}i;
for(i.a = 1;i.a<=9;i.a++)
{
for(i.b=1;i.b<=9;i.b++)
if(i.a%3 != i.b%3)
printf("A = %d,B=%d\n",i.a,i.b);
//printf("A:%c%d B:%c%d\n",'d'+i/3,i%3+1);
}
return 0;
}