一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(一)——地:起因
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(二)——月:自旋鎖
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(三)——地:q3.h 與 RingBuffer
第一篇文章末尾我們提到的《無鎖隊列的實現》(陳皓(hào)),該文末尾提到的“用數組實現無鎖隊列”,即用 RingBuffer 實現的無鎖隊列:

RingBuffer 是一個很好的東西,用在無鎖/有鎖隊列實在是太棒了,如該文提到的一樣,RingBuffer由於使用的是序號(或可稱為索引),且用數組存儲的隊列,跟使用鏈表存儲隊列相比,優點是可以避免ABA問題(關於ABA問題可以參考該文,或Google、百度自己搜),使用鏈表和指針來構造FIFO Queue(先進先出隊列),只有使用Double CAS(Double Compare And Swap)才能避免ABA問題,這裡不做討論。《無鎖隊列的實現》一文雖有提到,但是其描述是亂七八糟的,足見其只是大自然的搬運工,自己其實完全不懂。不過,東西是點到了。
包括上面截圖中的 RingBuffer 的描述,很多地方也是錯漏百出,RingBuffer 更新 head 和 tail 根本不需要使用Double CAS,我們也並不需要把(TAIL, EMPTY) 更新成 (x, TAIL),只需要使用CAS更新HEAD或TAIL即可。不過對於我們還是有幫助的,至少你知道了這個東西,還有個好處,就是你看這個東西需要自己腦補一下,也算是一個功德吧,不然一點腦子都不動也不好玩。哈哈。
Compare and Swap 或 Compare and Set(CAS)是 lock-free(無鎖編程) 中常見的技術,可以參考 wikipedia 的 Compare-and-swap,用C語言的實現就是:
int val_compare_and_swap(volatile int *dest_ptr,
int old_value, int new_value)
{
int orig_value = *dest_ptr;
if (*dest_ptr == old_value)
*dest_ptr = new_value;
return orig_value;
}
意思就是,先保存*dest_ptr的值(dest_ptr是一個指針),再檢查 *dest_ptr 的值是否等於舊址 old_value,如果等於的話,就把新值 new_value 寫入*dest_ptr,否則什麼都不做,最後返回值是 *dest_ptr 的原始值。CAS操作在CPU裡是能保證原子性的,即整個CAS操作不會被CPU的中斷或別的原因打斷。在x86下對應的匯編指令是 CMPXCHG 。
Compare and Swap 還有一種形式,即:
bool bool_compare_and_swap(volatile int *dest_ptr,
int old_value, int new_value)
{
if (*dest_ptr == old_value) {
*dest_ptr = new_value;
return true;
}
return false;
}
這其實是 val_compare_and_swap() 的變種,即如果 *dest_ptr 跟 old_value 相等則寫入新值 new_value,並返回 true,不相等則返回 false。
下面我們來看看什麼叫做 RingBuffer,先忘掉前面那篇文章,我們以 q3.h 的實現為范例:
文件地址:https://github.com/shines77/RingQueue/blob/master/douban/q3.h
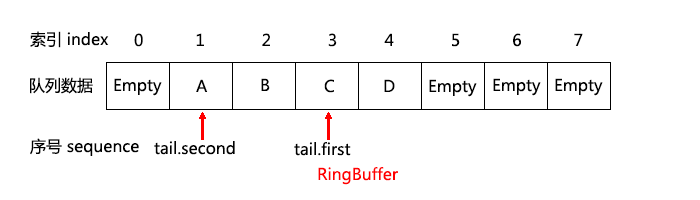
我們把 RingBuffer 這麼定義:
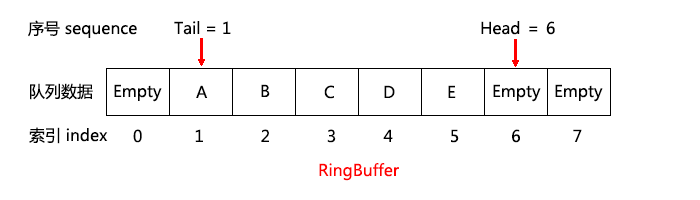
上面定義的是一個容量(Capacity)為8的RingBuffer,一般RingBuffer的容量取為2的N次冪,這樣計算索引時可以使用 index = sequence & mask; (其中mask = capacity - 1;) 以提高代碼效率。其中索引表示數組的下標,數組中保存的數據是A, B, C, D, Empty等。Head 表示隊列的頭指針(即首個可以壓入數據的位置),Tail 表示隊列的尾指針(即首個可以彈出數據的位置),Head、Tail都是以序號的形式存在,且是單調遞增的,且可以大於等於Capacity(8),如果Head = 8 時表示數組的第一個元素(因為回轉回來了,即 index = 8 & (8 - 1) = 8 & 7 = 0;),Head = 9 表示的其實是存儲在數組的第二個元素。
隊列內元素的實際長度為:Length = Head - Tail,其中 (Head - Tail) 必須 <= Capacity(最大容量),因為這個時候表示隊列已經滿了,如果(Head - Tail) = 0,則代表隊列為空。為什麼叫 RingBuffer,就是因為它是一個環,游標到了數組的尾部又回轉到數組的頭部。
至於定義哪邊是頭,哪邊是尾,這不是很重要,邏輯上更換一下即可。但是這樣定義比較直觀,你試想一下,如果把上面那個圖豎起來,你覺得哪邊是頭哪邊是尾?還有個原因是因為 q3.h 也是這麼定義的,而雲風自己寫的 mq.c 裡則是剛好反過來定義的。不過如何定義的確不重要,只是不方便討論而已。
這裡討論一下邊界的問題,q3.h 的邊界判定不是很准確,if ((mask + tail - head) < 1U) return -1; 這樣的寫法會導致隊列的實際最大長度為 Capacity - 1,而不是 Capacity。這還不是最大的問題,我們從上面得知 RingBuffer 的實際長度為:Length = Head - Tail,只要 Head, Tail 是無符號整型,即使 Head 從 4294967295 回繞到 0 的時候,這個公式依然成立。例如:Head = 2, Tail = 4294967295,Length = 2 - 4294967295 = -4294967293,而 4294967293 = 0xFFFFFFFD,一個數的負數計算機裡是用補碼,即取反再加1,0xFFFFFFFD 取反等於 0x00000002,再加1,就是3,所以實際長度為3,正確。所以只要RingQueue的定義一旦確定,只要Head,Tail使用無符號整型表示,實際元素長度公式 Length = Head - Tail 是永遠成立的。
那麼我們來看看 (mask + tail - head) < 1U 意味著什麼,tail - head其實等於-length,則有:(mask - length) < 1U,因為兩邊都是無符號整型,所以只有 (mask - length) = 0 的時候才能成立,其他時候都不會成立,即 length = mask 的時候條件才會成立,而 mask = capacity - 1; 所以 length = capacity - 1 的時候,q3.h 就認為隊列已經滿了,所以 q3.h 最大的實際長度只能為 capacity - 1 個元素。
而且他還有一個問題,可能你也看到了,因為只有 length = mask 這一種情況是被認為隊列滿了,當 length < mask 還好一點,一旦 length > (mask + 1) 的時候,實際上隊列已經滿了,但 q3.h 不知道,它依舊認為是可以push()的,為什麼它沒出錯呢?原因是這樣的,你分析過 q3.h 的push()代碼後,可以得知,由於head,tail都是單調遞增的,由於線程可能隨時被中斷,所以head,tail只會比當前實際的head,tail值小,而head不等於當前實際值時,是通不過CAS的原子性檢驗的,所以我們可以認為head永遠等於實際當前值,那麼只考慮一種情況,就是tail可能比當前實際的tail值小,由於length = head - tail,那麼意味著我們計算的length值,要比實際的length要大,也就是說隊列實際沒滿,而 q3.h 可能會認為滿了,從而導致push()失敗。沒有滿卻push()失敗沒有什麼壞處,大不了再繼續push()就是了,所以它並沒有出現問題。但從邏輯上講是不嚴密的。
所以通過上面的分析,我們得知判斷隊列是否已滿的邏輯為:隊列實際長度 >= 隊列最大容量,即:if ((head - tail) >= capacity) return -1; 由於 mask = capacity - 1,還可以簡化為:if ((head - tail) > mask) return -1; 。
同樣的道理,q3.h 裡判斷隊列為空的邏輯:if ((tail - head) < 1U) return NULL; 也是存在問題的,由於都是無符號整型,所以其等價於:if ((tail - head) == 0) return NULL; 同理,它在 q3.h 裡也不會出現問題,不過更嚴密的判斷邏輯應該為:if ((tail == head) || (tail > head && (head - tail) > mask)) return NULL; 。
我們再來看一下 q3.h,地址是:
https://github.com/shines77/RingQueue/blob/master/douban/q3.h
q3.h 裡 struct queue 是這麼定義的:
struct queue {
struct {
uint32_t mask;
uint32_t size;
volatile uint32_t head;
volatile uint32_t tail;
} p;
char pad[CACHE_LINE_SIZE - 4 * sizeof(uint32_t)];
struct {
uint32_t mask;
uint32_t size;
volatile uint32_t head;
volatile uint32_t tail;
} c;
char pad2[CACHE_LINE_SIZE - 4 * sizeof(uint32_t)];
void *msgs[0];
};
說實話,這樣寫並不是很准確,而且難於理解,其所定義的 struct p 和 struct c,嚴格意義來講,p 應該叫 head,c 應該叫 tail,而p,c裡面定義的 head,tail 應該叫 first,second,他們其實是一個pair,有點類似於std::pair,所以你也就知道我為什麼叫它們 first,second 了。(注:在 disruptor 裡面,first, second 被稱之為 next,cursor(next是首個可壓入數據的位置,cursor(游標)是最新一個已經成功提交(publish)數據的位置,這裡我們還是使用我的叫法)。
disruptor 裡next,cursor的示意圖如下:
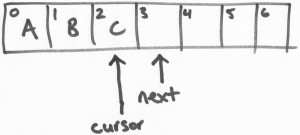
所以 struct queue 更准確的定義應該是這樣:
struct queue {
struct {
uint32_t mask;
uint32_t size;
volatile uint32_t first;
volatile uint32_t second;
} head;
char pad1[CACHE_LINE_SIZE - 4 * sizeof(uint32_t)];
struct {
uint32_t mask;
uint32_t size;
volatile uint32_t first;
volatile uint32_t second;
} tail;
char pad2[CACHE_LINE_SIZE - 4 * sizeof(uint32_t)];
void *msgs[0];
};
這裡面mask,size其實都是常量,完全可以不用放進來,不過這個不算太重要,暫時忽略。
所以 q3.h 裡的 push() 和 pop() 可以改寫為,同時我們把邊界判斷也修改了:
static inline int
push(struct queue *q, void *m)
{
uint32_t head, tail, mask, next;
int ok;
mask = q->head.mask;
do {
head = q->head.first;
tail = q->tail.second;
if ((head - tail) > mask)
return -1;
next = head + 1;
ok = __sync_bool_compare_and_swap(&q->head.first, head, next);
} while (!ok);
q->msgs[head & mask] = m;
asm volatile ("":::"memory");
while (unlikely((q->head.second != head)))
_mm_pause();
q->head.second = next;
return 0;
}
static inline void *
pop(struct queue *q)
{
uint32_t tail, head, mask, next;
int ok;
void *ret;
mask = q->tail.mask;
do {
tail = q->tail.first;
head = q->head.second;
if ((tail == head) || (tail > head && (head - tail) > mask))
return NULL;
next = tail + 1;
ok = __sync_bool_compare_and_swap(&q->tail.first, tail, next);
} while (!ok);
ret = q->msgs[tail & mask];
asm volatile ("":::"memory");
while (unlikely((q->tail.second != tail)))
_mm_pause();
q->tail.second = next;
return ret;
}
這樣應該比原來要清晰明了,容易理解了吧。其中“asm volatile ("":::"memory");”是編譯器內存屏障,如果你不理解的話,可以忽略它,大意就是編譯器做優化的時候,所有該屏障之前的寫入或讀入操作都不能越過該屏障,反之屏障之後的也類似。
該文件已上傳至:https://github.com/shines77/RingQueue/blob/master/douban/q3_new.h
下面我們來分析一下push()是怎麼工作的?代碼如下:
static inline int
push(struct queue *q, void *m)
{
uint32_t head, tail, mask, next;
int ok;
mask = q->head.mask;
do {
head = q->head.first;
tail = q->tail.second;
if ((head - tail) > mask)
return -1;
next = head + 1;
ok = __sync_bool_compare_and_swap(&q->head.first, head, next);
} while (!ok);
q->msgs[head & mask] = m;
asm volatile ("":::"memory");
while (unlikely((q->head.second != head)))
_mm_pause();
q->head.second = next;
return 0;
}
先來看看 head 裡的 head.first,head.second 的示意圖:
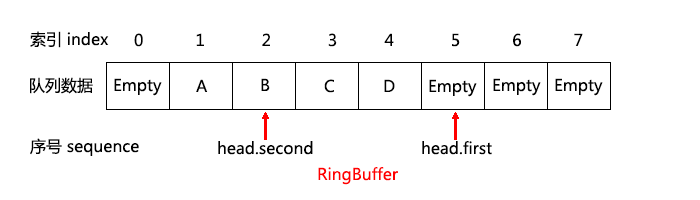
根據前面也提到過的 disruptor 的 next 與 cursor,類似的,這裡 head.first 是首個可以壓入數據的位置,head.second 是最新一個已經成功提交數據的位置。head.first 通過do while() 和 CAS 操作的保證,讓每個線程取得一個唯一的序號(sequence),因為CAS的原子性,即可保證每次只有一個線程有令 head.first 增一的機會。這有點類似你去銀行取錢的時候,一進門先得去一台機器上領個號碼,然後銀行再按照這個號碼的先後順序為客戶服務。我們稱這個號碼為序號(sequence),比如你領到的是5號,如上圖,但是銀行目前只處理完了2號客戶之前的客戶(包括2號客戶,即上圖中的 head.second),3, 4號客服都是正在辦理中的,而5號是你新領到的。跟現實銀行不太一樣地方是,這裡只要你一領到序號,窗口就立刻開始為你服務了,而各個窗口(各個線程)辦理完成的時間是不定的,可能4號窗口先辦理完,然後再是3號窗口,最後5號窗口,也就是你領到的號碼。還有一點跟現實銀行不一樣的地方,就是不管3, 4, 5窗口誰先辦理完成,都必須按照序號的大小來結束辦理過程,即4號窗口即使完成了,也要等3號窗口完成了以後才算完成,否則只能等3號窗口完成。如果5號窗口先辦理完畢,也必須等4號窗口完成,才能算最終完成。因為只有這麼依次完成,我們才好挪動 head.second 到最新成功提交數據的那個位置,如果不按照這個順序,跳著挪動 head.second,那麼 head.second 就亂套了。
這個按順序提交數據是通過 while (unlikely((q->head.second != head))) _mm_pause(); 實現的。只要最後成功提交數據的位置跟你領的序號(sequence)不一樣的話,就必須一直等,直到等於你的序號為止。這樣就實現了按順序提交數據(按領到的序號的順序)。這裡再提一下邊界判斷時講過的,這裡的 tail 可以認為小於等於實時的 tail.first 值(tail = tail.second,而 tail.second <= tail.first,而且 tail 也可以小於實時的 tail.second值),而 head 可以認為永遠等於 head.first 值(因為如果不等於,則CAS是通不過的,必須重來),因此 (head - tail) 是比實時的 (head - tail) 值大的,所有 push() 可能會在隊列未滿的時候就可能認為隊列滿了,因而提前退出,這樣是無害的,大不了重新push()。
另外,提交數據是由 q->msgs[head & mask] = m; 這句實現的,即按照你領到的序號寫入數據即可,因為這個序號是唯一的,只要保證隊列不溢出或負溢出,每一個獨立的序號都會在數組中有唯一的一個存儲位置。
我們再來分析一下Cache Line(緩存行)的占用,我們看到,前面那個do while() + CAS裡,CAS操作會鎖住 head.first 所在的緩存行(即讓其失效)。而後面的確認提交的循環中,while (unlikely((q->head.second != head))) 有對 head.second 的內存引用,而根據 q3.h 和 q3_new.h 的定義,兩者是在同一條Cache Line(內存行)上的(雖然不一定是100%在一條Cache Line上,但由於現在大部分編譯器內存對齊默認都是8字節,所以在一行上的機率幾乎接近100%)。而再後面的那句:q->head.second = next; 對 head.second 的寫入操作也將時其他線程的 do while() + CAS 循環裡的 head.first 的緩存失效。所以這是 q3.h 設計上的一個失誤,雖然考慮了Cache Line Padding(緩存行填充),但是沒有考慮周全,還是存在 False Sharing (偽共享)。這些問題在 disruptor 裡都很好的規避了,因為它給每一個序號變量都運用了Cache Line Padding,即 Sequence 類。其實 False Sharing 也不是很嚴重的事情,只不過線程越多,被鎖區域的運行時間越短,False Sharing造成的不利影響將越明顯。
從循環的角度來看,前面那個do while() + CAS,可以認為是一個自旋計數為0的自旋鎖,而後面那個確認提交的循環,則是一個真正意義的自旋,只有條件滿足了才能退出,兩個循環中都要依賴或等待別的線程才能確保退出循環,所以我們大致認為他們是兩個自旋在運作,這個我在“第二篇:自旋鎖”裡也有提到。
q3.h 還有一個問題就是,有可能會活鎖(livelock),雖然沒有完全死鎖(deadlock),但是 push() 和 pop() 執行得很慢很慢,超出常規的效率,原因還不太明白,有空再好好想想。出現這種情況的條件是(以下兩種描述因為有點忘記了,如果說得不對我會及時糾正):如果不開CPU親緣性的話,且當PUSH_CNT + POP_CNT 大於CPU的實際核心數的時候,會很慢;如果開啟了CPU親緣性的話,當PUSH_CNT + POP_CNT 大於CPU的實際核心數的時候,會非常慢,比前者還要慢。除了這些情況以外,執行效率還算正常。
我們再來看看pop(),代碼如下:
static inline void *
pop(struct queue *q)
{
uint32_t tail, head, mask, next;
int ok;
void *ret;
mask = q->tail.mask;
do {
tail = q->tail.first;
head = q->head.second;
if ((tail == head) || (tail > head && (head - tail) > mask))
return NULL;
next = tail + 1;
ok = __sync_bool_compare_and_swap(&q->tail.first, tail, next);
} while (!ok);
ret = q->msgs[tail & mask];
asm volatile ("":::"memory");
while (unlikely((q->tail.second != tail)))
_mm_pause();
q->tail.second = next;
return ret;
}
tail 裡的 tail.first,tail.second 的示意圖:
同上可知,這裡 tail.first 是首個可以彈出數據的位置,tail.second 是最新一個已經成功彈出數據的位置。彈出數據的語句是:ret = q->msgs[tail & mask]; 最終確認彈出的語句是:q->tail.second = next; 其他分析同 push() 類似。
縱觀 push() 和 pop(),你會發現 head.first,head.second,tail.first,tail.second 這四個變量環環相扣,互相影響,push() 一開始引用了 head.first 和 tail.second,而 pop() 一開始引用了 tail.first 和 head.second,但 head.first 和 head.second 是一條Cache Line上的,而 tail.first 和 tail.second 也是在一條Cache Line上的,無論誰的值更新或進入CAS操作,都會造成 False Sharing(偽共享) 讓緩存失效而互相影響。十足有當年赤壁之戰曹軍水軍連環船的風范……(火燒連環船)。這是 q3.h 設計上的一個大失誤,如果想提高一點效率,可以把這四個變量分別放到不同的 Cache Line 上,會好很多,而 disruptor 在這方面考慮得比較周全。
前面提到的關於 disruptor 的那篇原理文章是:http://blog.codeaholics.org/2011/the-disruptor-lock-free-publishing/ ,這不是我唯一看過的 disruptor 文章,我看了很多,不過這篇文章讓我能更好的來寫本文。關於 disruptor 的一些原理介紹,請自行 Google 或 百度,因為 disruptor 版本升級很快,而各篇文章描述所用的代碼或結構不一定跟最新版的相同,但原理上大致是一樣的,我也是看到了各種版本,各種說話,需要自己綜合起來。
暫時寫到這了,先休息,晚安,地球……。
RingQueue 的GitHub地址是:https://github.com/shines77/RingQueue,也可以下載UTF-8編碼版:https://github.com/shines77/RingQueue-utf8。 我敢說是一個不錯的混合自旋鎖,你可以自己去下載回來看看,支持Makefile,支持CodeBlocks, 支持Visual Studio 2008, 2010, 2013等,還支持CMake,支持Windows, MinGW, cygwin, Linux, Mac OSX等等,當然可能不支持ARM,沒測試環境。
(未完待續……敬請期待……)
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(一)——地:起因
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(二)——月:自旋鎖
一個無鎖消息隊列引發的血案:怎樣做一個真正的程序員?(三)——地:q3.h 與 RingBuffer