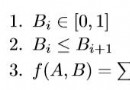Apache zookeeper Overview翻譯
名字由來
zookeeper:中文翻譯動物園管理員,是用來協調分布式程序的服務框架。之所以起名zookeeper,是因為作者把這些分散的、分布式的系統協調任務看成是一個動物園管理員做的事情。
設計目標
操作簡單:zookeeper主要用來協調處理分布式任務通過一個叫多層次的命名空間的東東,這個東東很類似文件系統。一個命名空間就是一個數據寄存器 - 稱為znode,按照zookeeper的說法,多層次的命名空間就是文件與目錄的關系。但zookeeper的數據是保存在內存中自我復制:像下面的這個分布式系統,zookeeper主要是在各個server間復制數據,zookeeper 服務必須彼此知道對方的存在。它們將維持同一個內存鏡像,通過事務控制。只要大多數的zookeeper機器可以運行,zookeeper就可以提供正常的服務。當一個client需要服務是可通過tcp鏈接到一個server,如果這個server掛掉了,它就會自動鏈接另一個server有序:zookeeper通過更新一個計數器,來反映zookeeper的事務順序,子操作可以通過這個這個計數器來實現更高層次的抽象,例如原語同步。快速:zookeeper尤其在讀取時表現的性能更為強悍,因為zookeeper service可以同時有很多機器提供且讀是寫的速度的10倍;
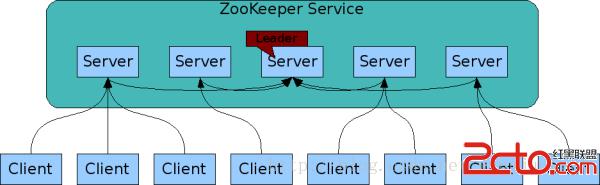
數據模型和多層次命名空間
ZooKeeper 的多層次命名空間:zookeeper的命名空間就像常見的文件系統,每個節點的路徑是唯一的,如下
vcTEzKi3/s7xxve/tLW9tcS94bn7trzKx9K70fm1xL/Jv7/Q1CAtINK7tam4/NDCsbvUy9PDo6zL/L2rs9bQ+LiyuMe/zbuntsuho7ywyrEgLSC/zbuntsu8sMqxytW1vc/7z6IKCrzytaW1xEFQSb3Tv9oKCnpvb2tlZXBlciDJ6LzG0qq077W9tcTEv7Hq1q7Su8rHzOG5qdK7uPa63LzytaW1xLPM0PK907/aoaPV/cjnz8LD5rXEveG5+6Osy/y99tans9bPwsPm1eLQqbLZ1/cKCmNyZWF0ZTxicj4KY3JlYXRlcyBhIG5vZGUgYXQgYSBsb2NhdGlvbiBpbiB0aGUgdHJlZTxicj4KZGVsZXRlPGJyPgpkZWxldGVzIGEgbm9kZTxicj4KZXhpc3RzPGJyPgp0ZXN0cyBpZiBhIG5vZGUgZXhpc3RzIGF0IGEgbG9jYXRpb248YnI+CmdldCBkYXRhPGJyPgpyZWFkcyB0aGUgZGF0YSBmcm9tIGEgbm9kZTxicj4Kc2V0IGRhdGE8YnI+CndyaXRlcyBkYXRhIHRvIGEgbm9kZTxicj4KZ2V0IGNoaWxkcmVuPGJyPgpyZXRyaWV2ZXMgYSBsaXN0IG9mIGNoaWxkcmVuIG9mIGEgbm9kZTxicj4Kc3luYzxicj4Kd2FpdHMgZm9yIGRhdGEgdG8gYmUgcHJvcGFnYXRlZAoKCgrKtbz5Cnpvb2tlZXBlciDVuc/WwcvX1Ly6uN/Lrsa9tcTX6bz+t/7O8aOs1NrUytDt0rvQqcfrx/PS7LOjzeKjrNfps8l6b29rZWVwZXK3/s7xtcTDv8yot/7O8cb3try74dTascu0y9auvOS4tNbGoaMKPGJyPgoKWm9vS2VlcGVyIENvbXBvbmVudHMKPGJyPgoKPGltZyBzcmM9"http://www.2cto.com/uploadfile/Collfiles/20140930/20140930092407285.jpg" alt="\">
復制數據是在內存中維持整個數據樹,更新的log被記錄子啊磁盤上以便為了恢復,在它們更新的內存中數據庫之前先被序列化到磁盤上,每個zookeeper服務器為好幾個客戶端提供服務,客戶端連接到一台服務器上提交請求,提供服務的是本地服務的數據庫,對於狀態改變的數據請求和寫入請求是按照一種叫做統一意見的協議。
統一意見協議是這樣的,所有寫入的請求都被送到一個統一的服務器,可以叫這台服務器為老大,其余的zookeeper服務器可以叫做小弟。老大發布信息,小弟們收到信息進行同步,信息傳送層值關心小弟們是否成功更新,和數據是否和老大保持了一致。
zookeeper使用了常用的原子信息傳送協議,正因為原子性,zookeeper才能保證各個小弟上得數據是無誤的,當老大收到一條寫入的數據的請求,它會計算整個系統的狀態當數據被復制在各個小弟上,它把它作為一種事物並且捕獲各個狀態
使用
zookeeper接口故意設計的很簡單,但是你也可以實現更高水平的操作,例如,異步原語,分組等等,一些分布式程序已經開始這樣這樣干了
性能
zookeeper設計特點是高性能。下面是雅虎開發團隊研究的結果,特別是在讀和寫做對比時,zookeeper表現出了更高的性能,因為寫操作是在所有的zookeeper服務器上同步數據狀態
ZooKeeper Throughput as the Read-Write Ratio Varies
可靠測試
下面是zookeeper運行在7台服務器上發生錯誤時的行為記錄,我們運行飽和測試,寫入的速讀的30%,下面是保守的數據測試
Reliability in the Presence of Errors
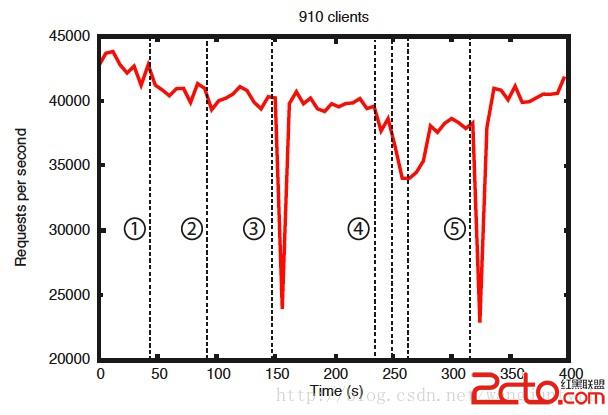
從上面這個圖表中可以看到幾點重要的觀測,假如同步失敗並且立馬恢復,zookeeper也是能保持在一個非常高的吞吐量。更重要的是,老大選擇的算法允許整個系統快速的恢復並在不影響吞吐量的情況下。zookeeper不在選出一個新老大時耗時超過200ms。第三,zookeeper在恢復後可以立馬處理請求。
使用zookeeper的項目
zookeeper已經成功的運行在很多商業項目中。在雅虎中,用來協調和失敗恢復