ConcurrentHashMap是線程安全且高效的HashMap,在多線程情況下,由於HashMap是非線程安全的,容易引起死循環,具體的原因可以自己google一下,這裡不做解釋,這裡只從大的方向和幾個關鍵的方法做解釋。
這裡簡單說一句,HashTable雖然解決了線程安全問題,但是由於其低效性,所以不推薦使用,並且它已經是一個過時的家伙了,所以干脆就不要考慮了,其之所以低效,就是鎖的粒度太大了。
下面開始分析關鍵方法和一些參數的含義。
首先看一下ConcurrentHashMap的大體框架,我大概畫了一個簡易的關系類圖,如下圖所示。
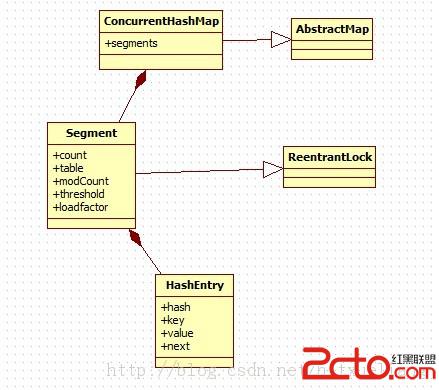
可以先不負責任的說ConcurrentHashMap之所以高效是因為它更好的降低了鎖的粒度。這個圖可以這樣理解,ConcurrentHashMap用於存儲東西的倉儲是Segment數組: final Segment
首先來解決比較難懂的哈希問題,這裡從初始化說起吧,這樣覺得更容易懂。
既然知道ConcurrentHashMap的優點是鎖的粒度減小了,那麼鎖加在哪裡了呢?從圖上就可以顯然的看出,鎖加在了每個Segment上,Segment數組是大的倉儲,那麼對於添加一個key-value來說,要先找到要添加到的segment.,那麼問題就都應該圍繞著這個來展開。
看源碼中的構造方法:
這裡給出解釋:
參數concurrencyLevel是用戶估計的並發級別,就是說你覺得最多有多少線程共同修改這個map,根據這個來確定Segment數組的大小
concurrencyLevel默認是DEFAULT_CONCURRENCY_LEVEL = 16;
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) "| initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment
new Segment
(HashEntry
Segment
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
在這裡來認識兩個重要的域:segmentShift和segmentMask分別表示段偏移量和段掩碼,這兩個和segment的定位比較相關。
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;//表示偏移位數
int ssize = 1;//表示segments數組的長度
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
從這裡可以看出segments數組的長度是由concurrencyLevel決定的,由於要通過按位與的方法來定位segment的位置,那麼必須保證segments的大小是2的整數次冪(power-of -two size),concurrencyLevel默認是16,那麼sshift默認就是4即左移的次數,ssize為16。再啰嗦一點,默認有16個線程同時修改,那麼我就默認的將segments大小設置為16,最理想情況下每個線程對應一個segment這樣就不沖突了。再啰嗦就是用戶如果指定concurrencyLevel為13,14,ssize都會是16,就是一定要保證大小是不小於concurrencyLevel的最小的2的整數次冪。
注意: static final int MAX_SEGMENTS = 1 << 16; // slightly conservative 這就是說concurrencyLevel最大值是65535,對應二進制是16位
再看下面這段:
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)//不滿的情況
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
initialCapacity是總容量,ssize知道了是segments數組的大小,那麼c顯然就是每個segment的大小了(這不嚴謹),實際上cap才是每個segment的容量大小,每個容量都是2的整數次冪。最少也是2
下面看這個比較難懂的hash函數:
private int hash(Object k) {
int h = hashSeed;
if ((0 != h) && (k instanceof String)) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();//首先先得到初始的hash
//利用h進行再哈希
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
那麼為什麼要這麼做呢,就是為了減小沖突,使得元素能夠均勻的分布在不同的segment上,知道了上面的就可以很好的進行解釋了。
當調用put方法時
public V put(K key, V value) {
Segment
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;//這裡就是在找下標啊
if ((s = (Segment
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
這裡給舉例解釋一下(都是在默認情況下,concurrencyLevel=16,ssize=16,sshift=4)那麼 this.segmentShift = 32 - sshift=28 而this.segmentMask = ssize - 1=15二進制就是1111;
如果對於給定的object原來的值分別是15,31,63,127(即 h ^= k.hashCode();//首先先得到初始的hash)
如果不采用再hash操作,那麼經過 int j = (hash >>> segmentShift) & segmentMask操作,得到的都是15
經過再hash後得到的hash值分別是:
源碼吧。
對於put方法來說,也是先定位,再判斷是否需要擴充容量,最後插入。這裡可以看看和HashMap的不同(提示,二者何時擴充不同,一前一後)
對於size方法來說,這裡有些東西還是很值得借鑒的。雖然每個segment都有一個count值表示個個大小,僅僅累加count是不能解決問題的。雖然當時獲得的count是最新的但在加的過程中又可能有變化,而僅僅為了得到size就把每個segment的put、remove,clean方法都鎖上,代價未免也太大了。因為在累加的過程中count發生變化的幾率比較小,那麼這裡就有一個小的trick,先通過嘗試2次不通過鎖住segment的方法獲取每個大小,如果在統計過程中,count發生變化了,那麼再通過加鎖的方式進行統計。
那麼如何判斷是否發生變化了呢,這裡modcount就是關鍵了,每次如put,remove操作都會對modcount進行加1操作,那麼只需比較調用size方法之前和之後的modconut大小就知道了。這裡值得借鑒啊。
關於ConcurrentHashMap就介紹到這裡,有點混亂,說的不是很清晰,但覺得關鍵的部分說出來了,可以自己再看看源碼分析一下,之所以分析一下,是因為在看Ehcache源碼的時候,它就是采用和這個類似的類作為倉庫的。個人分析可能有誤,如有錯誤請指正。