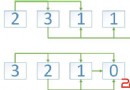
UTF-8是Unicode的一種實現方式,也就是它的字節結構有特殊要求,所以我們說一個漢字的范圍是0X4E00到0x9FA5,是指unicode值,至於放在utf-8的編碼裡去就是由三個字節來組織,所以可以看出unicode是給出一個字符的范圍,定義了這個字是碼值是多少,至於具體的實現方式可以有多種多樣來實現。
UTF-8是一種變長字節編碼方式。對於某一個字符的UTF-8編碼,如果只有一個字節則其最高二進制位為0;如果是多字節,其第一個字節從最高位開始,連續的二進制位值為1的個數決定了其編碼的位數,其余各字節均以10開頭。UTF-8最多可用到6個字節。
如表:
[cpp]
view plaincopyprint?1字節 0xxxxxxx
2字節 110xxxxx 10xxxxxx
3字節 1110xxxx 10xxxxxx 10xxxxxx
4字節 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字節 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字節 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
1字節 0xxxxxxx
2字節 110xxxxx 10xxxxxx
3字節 1110xxxx 10xxxxxx 10xxxxxx
4字節 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字節 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字節 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
因此UTF-8中可以用來表示字符編碼的實際位數最多有31位,即上表中x所表示的位。除去那些控制位(每字節開頭的10等),這些x表示的位與UNICODE編碼是一一對應的,位高低順序也相同。
實際將UNICODE轉換為UTF-8編碼時應先去除高位0,然後根據所剩編碼的位數決定所需最小的UTF-8編碼位數。
因此那些基本ASCII字符集中的字符(UNICODE兼容ASCII)只需要一個字節的UTF-8編碼(7個二進制位)便可以表示。
對於上面的問題,代碼中給出的兩個字節是
十六進制:C0 B1
二進制:11000000 10110001
對比兩個字節編碼的表示方式:
110xxxxx 10xxxxxx
提取出對應的UNICODE編碼:
00000 110001
可以看出此編碼並非“標准”的UTF-8編碼,因為其第一個字節的“有效編碼”全為0,去除高位0後的編碼僅有6位。由前面所述,此字符僅用一個字節的UTF-8編碼表示就夠了。
JAVA在把字符還原為UTF-8編碼時,是按照“標准”的方式處理的,因此我們得到的是僅有1個字節的編碼。
大家可以試試運行這段代碼:
[java]
public class TestUTF8 {
public static void main(String[] args) throws Exception {
byte[][] bytes = {
// 00110001
{(byte)0x31},
// 11000000 10110001
{(byte)0xC0,(byte)0xB1},
// 11100000 10000000 10110001
{(byte)0xE0,(byte)0x80,(byte)0xB1},
// 11110000 10000000 10000000 10110001
{(byte)0xF0,(byte)0x80,(byte)0x80,(byte)0xB1},
// 11111000 10000000 10000000 10000000 10110001
{(byte)0xF8,(byte)0x80,(byte)0x80,(byte)0x80,(byte)0xB1},
// 11111100 10000000 10000000 10000000 10000000 10110001
{(byte)0xFC,(byte)0x80,(byte)0x80,(byte)0x80,(byte)0x80,(byte)0xB1},
};
for (int i = 0; i < 6; i++) {
String str = new String(bytes[i], "UTF-8");
System.out.println("原數組長度:" + bytes[i].length +
"/t轉換為字符串:" + str +
"/t轉回後數組長度:" + str.getBytes("UTF-8").length);
}
}
}
public class TestUTF8 {
public static void main(String[] args) throws Exception {
byte[][] bytes = {
// 00110001
{(byte)0x31},
// 11000000 10110001
{(byte)0xC0,(byte)0xB1},
// 11100000 10000000 10110001
{(byte)0xE0,(byte)0x80,(byte)0xB1},
// 11110000 10000000 10000000 10110001
{(byte)0xF0,(byte)0x80,(byte)0x80,(byte)0xB1},
// 11111000 10000000 10000000 10000000 10110001
{(byte)0xF8,(byte)0x80,(byte)0x80,(byte)0x80,(byte)0xB1},
// 11111100 10000000 10000000 10000000 10000000 10110001
{(byte)0xFC,(byte)0x80,(byte)0x80,(byte)0x80,(byte)0x80,(byte)0xB1},
};
for (int i = 0; i < 6; i++) {
String str = new String(bytes[i], "UTF-8");
System.out.println("原數組長度:" + bytes[i].length +
"/t轉換為字符串:" + str +
"/t轉回後數組長度:" + str.getBytes("UTF-8").length);
}
}
}
運行結果為:
[java]
<SPAN style="BACKGROUND-COLOR: rgb(255,255,255)">原數組長度:1 轉換為字符串:1 轉回後數組長度:1
原數組長度:2 轉換為字符串:1 轉回後數組長度:1
原數組長度:3 轉換為字符串:1 轉回後數組長度:1
原數組長度:4 轉換為字符串:1 轉回後數組長度:1
原數組長度:5 轉換為字符串:1 轉回後數組長度:1
原數組長度:6 轉換為字符串:1 轉回後數組長度:1 </SPAN>
原數組長度:1 轉換為字符串:1 轉回後數組長度:1
原數組長度:2 轉換為字符串:1 轉回後數組長度:1
原數組長度:3 轉換為字符串:1 轉回後數組長度:1
原數組長度:4 轉換為字符串:1 轉回後數組長度:1
原數組長度:5 轉換為字符串:1 轉回後數組長度:1
原數組長度:6 轉換為字符串:1 轉回後數組長度:1