年夜數據情形下桶排序算法的應用與C++代碼完成示例。本站提示廣大學習愛好者:(年夜數據情形下桶排序算法的應用與C++代碼完成示例)文章只能為提供參考,不一定能成為您想要的結果。以下是年夜數據情形下桶排序算法的應用與C++代碼完成示例正文
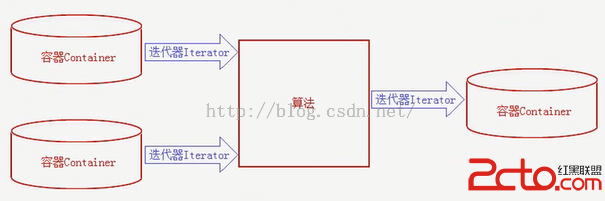
箱排序的變種。為了差別於上述的箱排序,權且稱它為桶排序(現實上箱排序和桶排序是同義詞)。
桶排序的思惟是把[0,1)劃分為n個年夜小雷同的子區間,每子區間是一個桶。然後將n個記載分派到各個桶中。由於症結字序列是平均散布在[0,1)上的,所以普通不會有許多個記載落入統一個桶中。因為統一桶中的記載其症結字不盡雷同,所以必需采取症結字比擬的排序辦法(平日用拔出排序)對各個桶停止排序,然後順次將各非空桶中的記載銜接(搜集)起來便可。
留意:
這類排序思惟基於以下假定:假定輸出的n個症結字序列是隨機散布在區間[0,1)之上。若症結字序列的取值規模不是該區間,只需其取值均非負,我們總能將一切症結字除以某一適合的數,將症結字映照到該區間上。但要包管映照後的症結字是平均散布在[0,1)上的。
桶排序的均勻時光龐雜度是線性的,即O(n)。
箱排序只實用於症結字取值規模較小的情形,不然所需箱子的數量m太多招致糟蹋存儲空間和盤算時光。
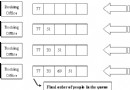
例如n=10,被排序的記載症結字ki取值規模是0到99之間的整數(36,5,16,98,95,47, 32,36,48)時,要用100個箱子來做一趟箱排序。(即若m=n2時,箱排序的時光O(m+n)=O(n2))。
例子
一年的全國高考考生人數為500 萬,分數應用尺度分,最低100 ,最高900 ,沒有小數,你把這500 萬元素的數組排個序。
剖析:對500W數據排序,假如基於比擬的先輩排序,均勻比擬次數為O(5000000*log5000000)≈1.112億。然則我們發明,這些數據都有特別的前提: 100=<score<=900。那末我們便可以斟酌桶排序如許一個“投契取巧”的方法、讓其在毫秒級別就完成500萬排序。
辦法:創立801(900-100)個桶。將每一個考生的分數丟進f(score)=score-100的桶中。這個進程從頭至尾遍歷一遍數據只須要500W次。然後依據桶號年夜小順次將桶中數值輸入,便可以獲得一個有序的序列。並且可以很輕易的獲得100分有***人,501分有***人。
現實上,桶排序對數據的前提有特別請求,假如下面的分數不是從100-900,而是從0-2億,那末分派2億個桶明顯是弗成能的。所以桶排序有其局限性,合適元素值聚集其實不年夜的情形。
代碼:
#include<iostream.h>
#include<malloc.h>
typedef struct node{
int key;
struct node * next;
}KeyNode;
void inc_sort(int keys[],int size,int bucket_size){
KeyNode **bucket_table=(KeyNode **)malloc(bucket_size*sizeof(KeyNode *));
for(int i=0;i<bucket_size;i++){
bucket_table[i]=(KeyNode *)malloc(sizeof(KeyNode));
bucket_table[i]->key=0; //記載以後桶中的數據量
bucket_table[i]->next=NULL;
}
for(int j=0;j<size;j++){
KeyNode *node=(KeyNode *)malloc(sizeof(KeyNode));
node->key=keys[j];
node->next=NULL;
//映照函數盤算桶號
int index=keys[j]/10;
//初始化P成為桶中數據鏈表的頭指針
KeyNode *p=bucket_table[index];
//該桶中還沒稀有據
if(p->key==0){
bucket_table[index]->next=node;
(bucket_table[index]->key)++;
}else{
//鏈表構造的拔出排序
while(p->next!=NULL&&p->next->key<=node->key)
p=p->next;
node->next=p->next;
p->next=node;
(bucket_table[index]->key)++;
}
}
//打印成果
for(int b=0;b<bucket_size;b++)
for(KeyNode *k=bucket_table[b]->next; k!=NULL; k=k->next)
cout<<k->key<<" ";
cout<<endl;
}
void main(){
int raw[]={49,38,65,97,76,13,27,49};
int size=sizeof(raw)/sizeof(int);
inc_sort(raw,size,10);
}
下面源代碼的桶內數據排序,我們應用了基於單鏈表的直接拔出排序算法。可使用基於雙向鏈表的快排算法進步效力。