排序算法是一種基本並且常用的算法。由於實際工作中處理的數量巨大,所以排序算法對算法本身的速度要求很高。
而一般我們所謂的算法的性能主要是指算法的復雜度,一般用O方法來表示。在後面我將
給出詳細的說明。
我將按照算法的復雜度,從簡單到難來分析算法。
第一部分是簡單排序算法,後面你將看到他們的共同點是算法復雜度為O(N*N)
第二部分是高級排序算法,復雜度為O(Log2(N))。這裡我們只介紹一種算法。另外還有幾種
算法因為涉及樹與堆的概念,所以這裡不於討論。
第三部分類似動腦筋。這裡的兩種算法並不是最好的(甚至有最慢的),但是算法本身比較
奇特,值得參考(編程的角度)。同時也可以讓我們從另外的角度來認識這個問題。
現在,讓我們開始吧:
一、簡單排序算法
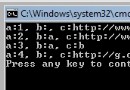
由於程序比較簡單,所以沒有加什麼注釋。所有的程序都給出了完整的運行代碼,並在我的VC環境
下運行通過。在代碼的後面給出了運行過程示意,希望對理解有幫助。
1.冒泡法
這是最原始,也是眾所周知的最慢的算法了。
#include <iostream.h>
void BubbleSort(int* pData,int Count)
{
int iTemp;
for(int i=1;i<Count;i++)
{
for(int j=Count-1;j>=i;j--)
{
if(pData[j]<pData[j-1])
{
iTemp = pData[j-1];
pData[j-1] = pData[j];
pData[j] = iTemp;
}
}
}
}
void main()
{
int data[] = {10,9,8,7,6,5,4};
BubbleSort(data,7);
for (int i=0;i<7;i++)
cout<<data[i]<<" ";
cout<<"\n";
}
倒序(最糟情況)
第一輪:10,9,8,7->10,9,7,8->10,7,9,8->7,10,9,8(交換3次)
第二輪:7,10,9,8->7,10,8,9->7,8,10,9(交換2次)
第一輪:7,8,10,9->7,8,9,10(交換1次)
循環次數:6次
交換次數:6次
其他:
第一輪:8,10,7,9->8,10,7,9->8,7,10,9->7,8,10,9(交換2次)
第二輪:7,8,10,9->7,8,10,9->7,8,10,9(交換0次)
第一輪:7,8,10,9->7,8,9,10(交換1次)
循環次數:6次
交換次數:3次
上面我們給出了程序段,現在我們分析它:這裡,影響我們算法性能的主要部分是循環和交換,
顯然,次數越多,性能就越差。從上面的程序我們可以看出循環的次數是固定的,為1+2+...+n-1。
寫成公式就是1/2*(n-1)*n。
現在注意,我們給出O方法的定義:
若存在一常量K和起點n0,使當n>=n0時,有f(n)<=K*g(n),則f(n) = O(g(n))。(呵呵,不要說沒
學好數學呀,對於編程數學是非常重要的!!!)
現在我們來看1/2*(n-1)*n,當K=1/2,n0=1,g(n)=n*n時,1/2*(n-1)*n<=1/2*n*n=K*g(n)。所以f(n)
=O(g(n))=O(n*n)。所以我們程序循環的復雜度為O(n*n)。
再看交換。從程序後面所跟的表可以看到,兩種情況的循環相同,交換不同。其實交換本身同數據源的
有序程度有極大的關系,當數據處於倒序的情況時,交換次數同循環一樣(每次循環判斷都會交換),
復雜度為O(n*n)。當數據為正序,將不會有交換。復雜度為O(0)。亂序時處於中間狀態。正是由於這樣的
原因,我們通常都是通過循環次數來對比算法。
2.交換法
交換法的程序最清晰簡單,每次用當前的元素一一的同其後的元素比較並交換。
#include <iostream.h>
void ExchangeSort(int* pData,int Count)
{
int iTemp;
for(int i=0;i<Count-1;i++)
{
for(int j=i+1;j<Count;j++)
{
if(pData[j]<pData[i])
{
iTemp = pData[i];
pData[i] = pData[j];
pData[j] = iTemp;
}
}
}
}
void main()
{
int data[] = {10,9,8,7,6,5,4};
ExchangeSort(data,7);
for (int i=0;i<7;i++)
cout<<data[i]<<" ";
cout<<"\n";
}
倒序(最糟情況)
第一輪:10,9,8,7->9,10,8,7->8,10,9,7->7,10,9,8(交換3次)
第二輪:7,10,9,8->7,9,10,8->7,8,10,9(交換2次)
第一輪:7,8,10,9->7,8,9,10(交換1次)
循環次數:6次
交換次數:6次
其他:
第一輪:8,10,7,9->8,10,7,9->7,10,8,9->7,10,8,9(交換1次)
第二輪:7,10,8,9->7,8,10,9->7,8,10,9(交換1次)
第一輪:7,8,10,9->7,8,9,10(交換1次)
循環次數:6次
交換次數:3次
從運行的表格來看,交換幾乎和冒泡一樣糟。事實確實如此。循環次數和冒泡一樣
也是1/2*(n-1)*n,所以算法的復雜度仍然是O(n*n)。由於我們無法給出所有的情況,所以
只能直接告訴大家他們在交換上面也是一樣的糟糕(在某些情況下稍好,在某些情況下稍差)。
3.選擇法
現在我們終於可以看到一點希望:選擇法,這種方法提高了一點性能(某些情況下)
這種方法類似我們人為的排序習慣:從數據中選擇最小的同第一個值交換,在從省下的部分中