在將各種類型的數據構造成字符串時,sprintf 的強大功能很少會讓你失望。由於sprintf 跟printf 在用法上幾乎一樣,只是打印的目的地不同而已,前者打印到字符串中,後者則直接在命令行上輸出。這也導致sprintf 比printf 有用得多。
int sprintf( char *buffer, const char *format [, argument] ... );
除了前兩個參數類型固定外,後面可以接任意多個參數。而它的精華,顯然就在第二個參數:
格式化字符串上。
printf 和sprintf 都使用格式化字符串來指定串的格式,在格式串內部使用一些以“%”開頭的格式說明符(format specifications)來占據一個位置,在後邊的變參列表中提供相應的變量,最終函數就會用相應位置的變量來替代那個說明符,產生一個調用者想要 的字符串。
sprintf 最常見的應用之一莫過於把整數打印到字符串中,所以,spritnf 在大多數場合可以替代itoa。
如:
//把整數123 打印成一個字符串保存在s中。 sprintf(s, "%d", 123); //產生"123"
可以指定寬度,不足的左邊補空格:
sprintf(s, "%8d%8d", 123, 4567); //產生:" 123 4567"
當然也可以左對齊:
sprintf(s, "%-8d%8d", 123, 4567); //產生:"123 4567"
也可以按照16 進制打印:
sprintf(s, "%8x", 4567); //小寫16 進制,寬度占8 個位置,右對齊 sprintf(s, "%-8X", 4568); //大寫16 進制,寬度占8 個位置,左對齊
這樣,一個整數的16 進制字符串就很容易得到,但我們在打印16 進制內容時,通常想要一種左邊補0 的等寬格式,那該怎麼做呢?很簡單,在表示寬度的數字前面加個0 就可以了。
sprintf(s, "%08X", 4567); //產生:"000011D7"
上面以”%d”進行的10 進制打印同樣也可以使用這種左邊補0 的方式。
這裡要注意一個符號擴展的問題:
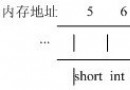
比如,假如我們想打印短整數(short)-1 的內存16 進制表示形式,在Win32 平台上,一個short 型占2 個字節,所以我們自然希望用4 個16 進制數字來打印它:short si = -1; sprintf(s, "%04X", si);產 生“FFFFFFFF”,怎麼回事?因為spritnf 是個變參函數,除了前面兩個參數之外,後面的參數都不是類型安全的,函數更沒有辦法僅僅通過一個“%X”就能得知當初函數調用前參數壓棧時被壓進來的到底 是個4 字節的整數還是個2 字節的短整數,所以采取了統一4 字節的處理方式,導致參數壓棧時做了符號擴展,擴展成了32 位的整數-1,打印時4 個位置不夠了,就把32 位整數-1 的8 位16 進制都打印出來了。
如果你想看si 的本來面目,那麼就應該讓編譯器做0 擴展而不是符號擴展(擴展時二進制左邊補0 而不是補符號位):
sprintf(s, "%04X", (unsigned short)si);
就可以了。或者:
unsigned short si = -1; sprintf(s, "%04X", si);
sprintf 和printf 還可以按8 進制打印整數字符串,使用”%o”。注意:8 進制和16 進制都不會打印出負數,都是無符號的,實際上也就是變量的內部編碼的直接的16 進制或8 進制表示。
浮點數的打印和格式控制是sprintf 的又一大常用功能,浮點數使用格式符”%f”控制,默認保留小數點後6 位數字,比如:
sprintf(s, "%f", 3.1415926); //產生"3.141593"
但有時我們希望自己控制打印的寬度和小數位數,這時就應該使用:”%m.nf”格式,其中m 表示打印的寬度,n 表示小數點後的位數。比如:
sprintf(s, "%10.3f", 3.1415626); //產生:" 3.142" sprintf(s, "%-10.3f", 3.1415626); //產生:"3.142 " sprintf(s, "%.3f", 3.1415626); //不指定總寬度,產生:"3.142"
注意一個問題,你猜
int i = 100; sprintf(s, "%.2f", i);
會打出什麼東東來?“100.00”?對嗎?自己試試就知道了,同時也試試下面這個:
sprintf(s, "%.2f", (double)i);
第 一個打出來的肯定不是正確結果,原因跟前面提到的一樣,參數壓棧時調用者並不知道跟i相對應的格式控制符是個”%f”。而函數執行時函數本身則並不知道當“年”被壓入棧裡的是個整數,於是可憐的保存整數i 的那4個字節就被不由分說地強行作為浮點數格式來解釋了,整個亂套了。不過,如果有人有興趣使用手工編碼一個浮點數,那麼倒可以使用這種方法來檢驗一下你手工編 排的結果是否正確。
我們知道,在C/C++語言中,char 也是一種普通的scalable 類型,除了字長之外,它與short,int,long 這些類型沒有本質區別,只不過被大家習慣用來表示字符和字符串而已。(或許當年該把這個類型叫做“byte”,然後現在就可以根據實際情況,使用byte 或short 來把char 通過typedef 定義出來,這樣更合適些)於是,使用”%d”或者”%x”打印一個字符,便能得出它的10 進制或16 進制的ASCII 碼;反過來,使用”%c”打印一個整數,便可以看到它所對應的ASCII 字符。以下程序段把所有可見字符的ASCII 碼對照表打印到屏幕上(這裡采用printf,注意”#”與”%X”合用時自動為16 進制數增加”0X”前綴):
for(int i = 32; i < 127; i++) {
printf("[ %c ]: %3d 0x%#04X/n", i, i, i);
}
sprintf 的格式控制串中既然可以插入各種東西,並最終把它們“連成一串”,自然也就能夠連接字符串,從而在許多場合可以替代strcat,但sprintf 能夠一次連接多個字符串(自然也可以同時在它們中間插入別的內容,總之非常靈活)。比如:
char* who = "I"; char* whom = "亂頓"; sprintf(s, "%s love %s.", who, whom); //產生:"I love 亂頓. "
strcat 只能連接字符串(一段以’/0’結尾的字符數組或叫做字符緩沖,null-terminated-string),但有時我們有兩段字符緩沖區,他們並不 是以’/0’結尾。比如許多從第三方庫函數中返回的字符數組,從硬件或者網絡傳輸中讀進來的字符流,它們未必每一段字符序列後面都有個相應的’/0’來結 尾。如果直接連接,不管是sprintf 還是strcat 肯定會導致非法內存操作,而strncat 也至少要求第一個參數是個null-terminated-string,那該怎麼辦呢?我們自然會想起前面介紹打印整數和浮點數時可以指定寬度,字符串 也一樣的。比如:
char a1[] = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
char a2[] = {'H', 'I', 'J', 'K', 'L', 'M', 'N'};
如果:
sprintf(s, "%s%s", a1, a2); //Don't do that!
十有八九要出問題了。是否可以改成:
sprintf(s, "%7s%7s", a1, a2);
也沒好到哪兒去,正確的應該是:
sprintf(s, "%.7s%.7s", a1, a2); //產生:"ABCDEFGHIJKLMN"
這 可以類比打印浮點數的”%m.nf”,在”%m.ns”中
通常在打印字符串時m 沒什麼大用,還是點號後面的n 用的多。自然,也可以前後都只取部分字符:
sprintf(s, "%.6s%.5s", a1, a2); //產生:"ABCDEFHIJKL"
在許多時候,我們或許還希望這些格式控制符中用以指定長度信息的數字是動態的,而不是靜態指定的,因為許多時候,程序要到運行時才會清楚到底需要取字符數組 中的幾個字符,這種動態的寬度/精度設置功能在sprintf 的實現中也被考慮到了,sprintf 采用”*”來占用一個本來需要一個指定寬度或精度的常數數字的位置,同樣,而實際的寬度或精度就可以和其它被打印的變量一樣被提供出來,於是,上面的例子 可以變成:
sprintf(s, "%.*s%.*s", 7, a1, 7, a2);
或者:
sprintf(s, "%.*s%.*s", sizeof(a1), a1, sizeof(a2), a2);
實際上,前面介紹的打印字符、整數、浮點數等都可以動態指定那些常量值,比如:
sprintf(s, "%-*d", 4, 'A'); //產生"65 " sprintf(s, "%#0*X", 8, 128); //產生"0X000080","#"產生0X sprintf(s, "%*.*f", 10, 2, 3.1415926); //產生" 3.14"
有時調試程序時,我們可能想查看某些變量或者成員的地址,由於地址或者指針也不過是個32 位的數,你完全可以使用打印無符號整數的”%u”把他們打印出來:
sprintf(s, "%u", &i);
不過通常人們還是喜歡使用16 進制而不是10 進制來顯示一個地址:
sprintf(s, "%08X", &i);
然而,這些都是間接的方法,對於地址打印,sprintf 提供了專門的”%p”:
sprintf(s, "%p", &i);
我覺得它實際上就相當於:
sprintf(s, "%0*x", 2 * sizeof(void *), &i);
較少有人注意printf/sprintf 函數的返回值,但有時它卻是有用的,spritnf 返回了本次函數調用最終打印到字符緩沖區中的字符數目。也就是說每當一次sprinf 調用結束以後,你無須再調用一次strlen 便已經知道了結果字符串的長度。如:
int len = sprintf(s, "%d", i);
對於正整數來說,len 便等於整數i 的10 進制位數。
下面的是個完整的例子,產生10 個[0, 100)之間的隨機數,並將他們打印到一個字符數組s 中,以逗號分隔開。
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
int main() {
srand((unsigned)time(NULL));
char s[64];
int offset = 0;
for(int i = 0; i < 10; i++) {
offset += sprintf(s + offset, "%d,", rand() % 100);
}
s[offset - 1] = '/n';//將最後一個逗號換成換行符。
printf(s);
return 0;
}
設想當你從數據庫中取出一條記錄,然後希望把他們的各個字段按照某種規則連接成一個字符串時,就可以使用這種方法,從理論上講,他應該比不斷的 strcat 效率高,因為strcat 每次調用都需要先找到最後的那個’/0’的位置,而在上面給出的例子中,我們每次都利用sprintf 返回值把這個位置直接記下來了。
sprintf 是個變參函數,使用時經常出問題,而且只要出問題通常就是能導致程序崩潰的內存訪問錯誤,但好在由sprintf 誤用導致的問題雖然嚴重,卻很容易找出,無非就是那麼幾種情況,通常用眼睛再把出錯的代碼多看幾眼就看出來了。
沒的說,給個大點的地方吧。當然也可能是後面的參數的問題,建議變參對應一定要細心,而打印字符串時,盡量使用”%.ns”的形式指定最大字符數。
低級得不能再低級問題,用printf 用得太慣了。//偶就常犯。:(
通常是忘記了提供對應某個格式符的變參,導致以後的參數統統錯位,檢查檢查吧。尤
其是對應”*”的那些參數,都提供了嗎?不要把一個整數對應一個”%s”,編譯器會覺得你
欺她太甚了(編譯器是obj 和exe 的媽媽,應該是個女的,:P)。
sprnitf 還有個不錯的表妹:strftime,專門用於格式化時間字符串的,用法跟她表哥很像,也是一大堆格式控制符,只是畢竟小姑娘家心細,她還要調用者指定緩沖區的最大長度,可能是為了在出現問題時可以推卸責任吧。這裡舉個例子:
time_t t = time(0); //產生"YYYY-MM-DD hh:mm:ss"格式的字符串。 char s[32]; strftime(s, sizeof(s), "%Y-%m-%d %H:%M:%S", localtime(&t));
sprintf 在MFC 中也能找到他的知音:CString::Format,strftime 在MFC 中自然也有她的同道:
CTime::Format,這一對由於從面向對象哪裡得到了贊助,用以寫出的代碼更覺優雅
我兩年前就知道不應該用 == 號來判斷浮點數的相等了,因為存在一個精度的問題,但是一直以來,都沒怎麼在乎這些東西,而實際上,我對於浮點數的結構,雖然 了解,但並不清晰. 作為一個C++愛好者,應該盡量搞清楚每一個問題,所以我搞清楚了浮點數的內在表示及實現.在沒有大問題的情況下,一切以易於理解和記憶為標准.
移碼其實就等於補碼,只是符號相反. 對於正數而言,原, 反, 補碼都一樣, 對負數而言,反碼除符號位外,在原碼的基礎上按位取反,補碼則在反碼的基礎之上,在其最低位上加1,要求移碼時,仍然是先求補碼,再改符號.
浮點數分為float和double,分別占4,8個字節,即32,64位. 我僅以32位的float為例,並附帶說double.
在IEEE754標准中,規定,float的32位這樣分:
符號位(S) 1 階碼(E) 8 尾數(M) 23
這裡應該注意三點:
接下來只要說明幾個問題就明白了,以123.456為例,表示為二進制就是:N (2) = 1111011. 01110100101111001 ,這裡,會右移6位,得到N (2) = 1.111011 01110100101111001*2^6; 這種形式就可以用於上圖中的表示格式了.
符號位(S) 0 階碼(E) 00000110 尾數(M) 11101101110100101111001
注意到,上面的階碼第一位為0表正,尾數比N(2)表示的第一位少了個1,這就是上面說的默認為第一位為1. 由於在將十進制轉為二進制的過程中,常常不能正好轉得相等, (當然,像4.0這樣的就不會有損失,而1.0/3.0這樣的必然損失),所以就產生了浮點數的精度問題, 實際上,小數點後的23位二進制數,能影響的十進制數的前8位,這是為什麼呢?一般人在這時往往迷迷胡胡了,其實很簡單,在上面表示的尾數中,是二進制 的,小數點後有23位,最後一位的值為1時,它就是1/2^22=0.000000238實際取的時候肯定是0.0000002,也就是說,對於一個 float型的浮點數,其有效的位數是從左到右數7位(包括缺省的1才是7位),當到達上面這個第8位時,就不可靠了,但我們的VC6可以輸出最長的 1.0/3.0為0.33333333333333331,這主要是編譯器的問題了, 而並不是說浮點數小數點後的16位都有效. 如果不信的話,可以去試一下double類型的1.0/3.0, 得到的也將是小數點後17 位. ..另外,編譯器或電路板一般都有”去噪聲”的”修正”能力,它能夠使得超過7位的十進制數即使無效了也不會變得離譜,這也是上面為什麼一直都是輸出 333而不是345之類的,. 可以這樣試一下:
float f = 123456789; cout<<f<<endl; //這裡肯定得到123456789.
這裡有一個被人遺忘的問題,就是10進制小數怎麼變為2進制小數,其實很簡單,就是將10進的小數部分不斷乘以2,進位時就將對應的2進制位寫入1. 因此將上面的N (2) = 1.111011 01110100101111001*2^6;再轉回十進制數時,很可能已經不再是123.456了. 好,精度問題應該說清楚了.
階碼的示數位數是8位移碼, 最大為127最小為-127,這裡的127用來作為2的指數,因此為2^127,約等於 1.7014*10^38, 而我們知道,float的示數范圍約為-3.4*10^38——-3.4*10^38, 這是因為尾數的24位(默認第一位為1)全為1是,非常接近2, 1.11..11很明顯約為2,因此浮點數的范圍就出來了.
double的情況與float完全相似,只是它的內在形式是
符號位(S) 1 階碼(E) 11 尾數(M) 52
主要的區別在於它的階碼有11位了, 這就有2^1023約等於 0.8572*10^308, 尾數53位約為2,故double的示數范圍約為 -1.7*10^308.——1.7*10^308. 至於其精度,同樣,1.0/2^51=4.4*10^(-16).小數點後15位有效,加上缺省的那一位,因此對於double浮點數,從左到右的16位 數都是可靠的.
有時,我們會聽到”定點小數”這個詞,單片機(如手機等)一般只使用定點數,迷糊的時候,我們會以為 float a=23.4; 這種是定點小數, float a=2.34E1這種為浮點數,其實這是錯誤的, 上面只是同一個浮點數的不同表示,都是浮點數. 定點小數是有這種提法,認為整就是定點小數,小數點定在個位後面,小數部分為0.也可認為純小數是定點小數,但它只能表示小於1的純小數.
C++中默認輸出小數點後的5位小數,但可以設置,有兩種方法:調用setpression或者使用cout.pression,但效果是不同的:
float mm=123.456789f; cout<<mm<<endl; //123.457 雖說默認為不數點後5位,但只是整數部分只有一位才這樣. setprecision(10); //設置小數點後的位數,但當整數部分有兩位時,與默認情況沒什麼兩樣,不起作用. cout<<mm<<endl; //123.457 cout.precision(4); //設置總的位數. cout<<mm<<endl; //123.4 總之效果是比較怪的,個人認為雖然這樣顯得不夠確定,但實為硬件系統所限.無可厚非.
對於0的實際表示,有人認為+0一般能絕對為0,而-0則可能表示一個極小的數. 為此,本人想到了一種很好的驗證辦法,證明了不管+0還是-0,它都是2^(-127),代碼如下:
float fDigital = 0.0f; unsigned long nMem; // 臨時變量,用於存儲浮點數的內存數據 // 將內存按位復制到臨時變中,以便取用,此時的nMem並不等於fDigital了,它是按位復制的。 nMem = *(unsigned long*)&fDigital; cout<<nMem<<endl; //一般得到一個很大的整數. bitset<32>mybit(nMem); //妙在此處,這裡的輸出就是32float的內存表示了.終於完全直觀地看到了. cout<<mybit<<endl; //00000000000000000000000000000000 用-0.0來試,也是如此.
如果你還認為上面那一長串的0表示的是絕對的0,那麼請重新看本文. 事實上,本人的這種做法是比較巧妙的,將上面的fDigital用任何其它浮點數表示,這個bitset數都可以反映出它的內存表示.
有移碼表示階碼有是有原因的,主要是移碼便於對階操作,從而比較兩個浮點數的大小. 這裡要注意的是,階碼不能達到11111111的形式,IEEE規定,當編譯器遇到階碼為0XFF時,即調用溢出指令. 總之,階碼化為整數時,范圍是:-127~127.
最後,有一個往往高手也汗顏的地方,一定要記住,浮點數沒有無符號型的usinged float/double是錯誤的.
本人才疏學淺,歡迎批評指正.