大部分device一開始從global Memory獲取數據,而且,大部分GPU應用表現會被帶寬限制。因此最大化應用對global Memory帶寬的使用時獲取高性能的第一步。也就是說,global Memory的使用就沒調節好,其它的優化方案也獲取不到什麼大效果。
如下圖所示,global Memory的load/store要經由cache,所有的數據會初始化在DRAM,也就是物理的device Memory上,而kernel能夠獲取的global Memory實際上是一塊邏輯內存空間。Kernel對Memory的請求都是由DRAM和SM的片上內存以128-byte和32-byte傳輸解決的。
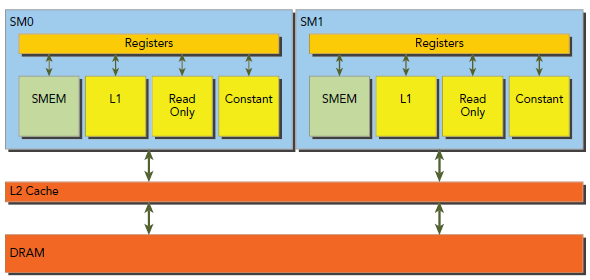
所有獲取global Memory都要經過L2 cache,也有許多還要經過L1 cache,主要由GPU的架構和獲取模式決定的。如果L1和L2都被使用,那麼Memory的獲取是以128-byte為單位傳輸的,如果只使用L2,則以32-byte為單位傳輸,在允許使用L1的GPU中(好像Maxwell已經徹底不使用L1,原本走L1都換成走texture cache),L1是可以在編譯期被顯示使用或禁止的。
由上文可知,L1 cache中每一行是128bytes,這些數據映射到device Memory上的128位對齊的塊。如果warp中每個thread請求一個4-byte的值,那麼每次請求會要求獲取128 bytes值,正好契合cache line大小和device Memory segment大小。
因此,我們在設計代碼的時候,有兩個特征需要注意:
當要獲取的Memory首地址是cache line的倍數時,就是Aligned Memory Access,如果是非對齊的,就會導致浪費帶寬。至於Coalesced Memory Access則是warp的32個thread請求的是連續的內存塊。
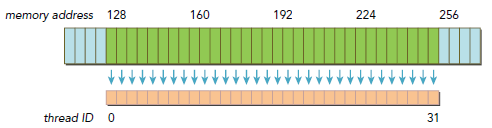
下圖就是很好的符合了連續和對齊原則,只有128-byte Memory傳輸的消耗:
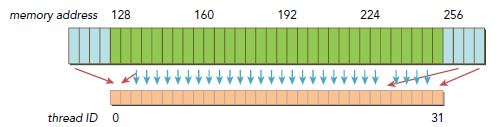
下圖則沒有遵守連續和對齊原則,有三次傳輸消耗發生,一次是從偏移地址0開始,一次是從偏移地址256開始,還有一次是從偏移128開始,而這次包含了大部分需要的數據,另外兩次則有很多數據並不是需要的,而導致帶寬浪費。
一般來講,我們應該這樣優化傳輸效率:使用最少的傳輸次數來滿足最大的獲取內存請求。當然,需要多少傳輸,多大的吞吐都是跟CC有關的。
在SM中,數據運送是要經過下面三種cache/buffer的,主要依賴於要獲取的device Memory種類:
L1/L2是默認路徑,另外兩條路需要應用顯示的說明,一般這樣做都是為了提升性能(寫CUDA代碼的時候,可以先都使用global Memory,然後根據需要慢慢調節,使用一些特殊的內存來提升性能)。Global Memory的load操作是否經過L1cache可以有下面兩個因素決定:
默認情況下,L1是被開啟的,-Xptxas -dlcm=cg可以用來禁用L1。L1被禁用後,所有去L1的都直接去L2了。當L2未命中時,就直接去DRAM。所有Memory transaction可能請求一個,兩個或者四個segment,每個segment是32 bytes。當然L1也可以被顯式的開啟-Xptxas -dlcm=ca,此時,所有Memory請求都先走L1,未命中則去L2。在Kepler K10,K20和K20x系列GPU,L1不在用來cache global Memory,L1的唯一用途就是來cache由於register spill放到local Memory的那部分register。
我們以默認開啟L1為例,說明下對齊和連續,下圖是理想的情況,連續且對齊,warp中所有thread的Memory請求都落在同一塊cache line(128 bytes),只有一次傳輸消耗,沒有任何多余的數據被傳輸,bus使用效率百分百。

下圖是對齊但線程ID和地址不是連續一一對應的情況,不過由於所有數據仍然在一個連續對齊的塊中,所有依然沒有額外的傳輸消耗,我們仍然只需要一次128 bytes的傳輸就能完成。

下圖則是非連續未對齊的情況,數據落在了兩個128-byte的塊中,所以就有兩個128-byte的傳輸消耗,而其中有一半是無效數據,bus使用是百分之五十。

下圖是最壞的情況,同樣是請求32個4 bytes數據,但是每個地址分布的相當不規律,我們只想要需要的那128 bytes數據,但是,實際上下圖這樣的分布,卻需要N∈(0,32)個cache line,也就是N次數據傳輸消耗。

CPU的L1 cache是根據時間和空間局部性做出的優化,但是GPU的L1僅僅被設計成針對空間局部性而不包括時間局部性。頻繁的獲取L1不會導致某些數據駐留在cache中,只要下次用不到,直接刪。
這裡就是指不走L1但是還是要走L2,也就是cache line從128-byte變為32-byte了。依然以上文warp 32個thread每個4 bytes請求,總計128 bytes為例,下圖是理想的對齊且連續情形,所有的128 bytes都落在四塊32 bytes的塊中。

下圖請求沒有對齊,請求落在了160-byte范圍內,bus有效使用率是百分之八十,相對使用L1,性能要好不少。

下圖是所有thread都請求同一塊數據的情形,bus有效使用率為4bytes/32bytes=12.5%,依然要比L1表現好。

下圖是情況最糟糕的,數據非常分散,但是由於所請求的128 bytes落在了多個以32 bytes為單位的segment中,因此無效的數據傳輸要少的多。

內存獲取模式一般都是有應用的實現和算法來決定的,一些情況下,要滿足連續內存是非常難的。但是對於對齊來說,是有一些方法來幫助應用實現的。
下面以代碼來檢驗上述知識,kernel中多了一個k索引,是用來配置偏移地址的,通過他就可以配置對齊情況,只有在load兩個數組A和B時才會使用k。對C的寫操作則繼續使用原來的代碼,從而保證寫操作 保持很好的對齊。
__global__ void readOffset(float *A, float *B, float *C, const int n,int offset) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int k = i + offset;
if (k < n) C[i] = A[k] + B[k];
}
下面是main代碼,offset默認是零:

編譯運行:
$ nvcc -O3 -arch=sm_20 readSegment.cu -o readSegment $ ./readSegment 0 readOffset <<< 32768, 512 >>> offset 0 elapsed 0.001820 sec $ ./readSegment 11 readOffset <<< 32768, 512 >>> offset 11 elapsed 0.001949 sec $ ./readSegment 128 readOffset <<< 32768, 512 >>> offset 128 elapsed 0.001821 sec
當offset=11時,會導致從A和B load數據時不對齊。其運行時間消耗也是最大的,我們可以使用nvcc的gld_efficiency來檢驗一下:
$ nvprof --devices 0 --metrics gld_transactions ./readSegment 0 $ nvprof --devices 0 --metrics gld_transactions ./readSegment 11 $ nvprof --devices 0 --metrics gld_transactions ./readSegment 128
輸出:
Offset 0: gld_efficiency 100.00% Offset 11: gld_efficiency 49.81% Offset 128: gld_efficiency 100.00%
可以看到offset=11時,效率減半,可以預見其吞吐必然很高,也可以使用gld_transactions來檢驗:
$ nvprof --devices 0 --metrics gld_transactions ./readSegment $OFFSET
輸出為:
Offset 0: gld_transactions 65184 Offset 11: gld_transactions 131039 Offset 128: gld_transactions 65744
然後我們使用-Xptxas -dlcm=cg來禁用L1,看一下直接使用L2的表現:
$ ./readSegment 0 readOffset <<< 32768, 512 >>> offset 0 elapsed 0.001825 sec $ ./readSegment 11 readOffset <<< 32768, 512 >>> offset 11 elapsed 0.002309 sec $ ./readSegment 128 readOffset <<< 32768, 512 >>> offset 128 elapsed 0.001823 sec
從該結果看出,未對齊的情況更糟糕了,然後看下gld_efficiency:
Offset 0: gld_efficiency 100.00% Offset 11: gld_efficiency 80.00% Offset 128: gld_efficiency 100.00%
因為L1被禁用後,每次load操作都是以32-byte為單位而不是128,所以無用數據會減少非常多。
這裡未對齊反而情況變糟是一種特例,高Occupancy情況下,uncached會幫助提升bus有效使用率,而對於未對齊的情況,無用數據的傳輸將明顯減少。
最開始,read-only cache是用來為texture Memory load服務的,對於CC3.5以上,該cache可以替換L1。Read-only cache的單位是32 bytes,一般來講是比L1要好用得多。
有兩種方式來使用read-only cache:
例如:
__global__ void copyKernel(int *out, int *in) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
out[idx] = in[idx];
}
改寫後:
__global__ void copyKernel(int *out, int *in) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
out[idx] = __ldg(&in[idx]);
}
或者使用 const __restrict__來修飾指針。該修飾符幫助nvcc編譯器識別non-aliased指針,nvcc會自動使用該non-alias 指針從read-cache讀出數據。
__global__ void copyKernel(int * __restrict__ out,const int * __restrict__ in) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
out[idx] = in[idx];
}
寫操作相對要簡單的多,L1壓根就不使用了。數據只會cache在L2中,所以寫操作也是以32bytes為單位的。Memory transaction一次可以是一個、兩個或四個segment。例如,如果兩個地址落在了同一個128-byte的區域內,但是在不同的兩個64-byte對齊的區域,一個四個segment的transaction就會被執行(也就是說,一個單獨的4-segment的傳輸要比兩次1-segment的傳輸性能好)。
下圖是一個理想的情況,連續且對齊,只需要一次4 segment的傳輸:

下圖是離散的情況,會由三次1-segment傳輸完成。

下圖是對齊且地址在一個連續的64-byte范圍內的情況,由一次2-segment傳輸完成:

再次修改代碼,load變回使用i,而對C的寫則使用k:
__global__ void writeOffset(float *A, float *B, float *C,const int n, int offset) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int k = i + offset;
if (k < n) C[k] = A[i] + B[i];
}
修改host的計算函數;
void sumArraysOnHost(float *A, float *B, float *C, const int n,int offset) {
for (int idx = offset, k = 0; idx < n; idx++, k++) {
C[idx] = A[k] + B[k];
}
}
編譯運行:
$ nvcc -O3 -arch=sm_20 writeSegment.cu -o writeSegment $ ./writeSegment 0 writeOffset <<< 2048, 512 >>> offset 0 elapsed 0.000134 sec $ ./writeSegment 11 writeOffset <<< 2048, 512 >>> offset 11 elapsed 0.000184 sec $ ./writeSegment 128 writeOffset <<< 2048, 512 >>> offset 128 elapsed 0.000134 sec
顯而易見,Misaligned表現最差,然後查看gld_efficiency:
$ nvprof --devices 0 --metrics gld_efficiency --metrics gst_efficiency ./writeSegment $OFFSET writeOffset Offset 0: gld_efficiency 100.00% writeOffset Offset 0: gst_efficiency 100.00% writeOffset Offset 11: gld_efficiency 100.00% writeOffset Offset 11: gst_efficiency 80.00% writeOffset Offset 128: gld_efficiency 100.00% writeOffset Offset 128: gst_efficiency 100.00%
除了offset=11的store外,所有load和store都是百分百。當offset=11時,128-bytes的寫請求會被一個4-segment和一個1-segment的傳輸服務,因此,我們雖然需要寫128bytes但是卻有160bytes數據被load,從而導致百分之八十的效率。
作為C程序員,我們應該熟悉兩種組織數據的方式:array of structures(AoS)和structure of arrays(SoA)。二者的使用是一個有趣的話題,主要是數據排列組織。
觀察下面代碼,首先考慮該數據結構集合在使用AoS組織時,是怎樣存儲的:
struct innerStruct {
float x;
float y;
};
struct innerStruct myAoS[N]; //每一對x和y的存儲,空間上是連續的
然後是SoA:
struct innerArray {
float x[N];
float y[N];
};
struct innerArray moa; //x和y是分別存儲的,所有x和y是分別存儲在兩段不同的連續地址裡。
下圖顯示了AoS和SoA在內存中的存儲格式,當對x進行操作時,會導致一般的帶寬浪費,因為在操作x時,y也會隱式的被load,而SoA的表現就要好得多,因為所有x都是相鄰的。
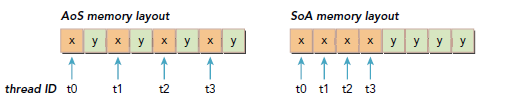
許多並行編程規范裡,特別是SIMD-style風格的規范,都更傾向於使用SoA,在CUDA C裡,SoA也是非常建議使用的,因為數據已經預先排序連續了。
__global__ void testInnerStruct(innerStruct *data,innerStruct *result, const int n) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
innerStruct tmp = data[i];
tmp.x += 10.f;
tmp.y += 20.f;
result[i] = tmp;
}
}
輸入長度是1M,#define LEN 1<<20。
初始化數據:
void initialInnerStruct(innerStruct *ip, int size) {
for (int i = 0; i < size; i++) {
ip[i].x = (float)(rand() & 0xFF) / 100.0f;
ip[i].y = (float)(rand() & 0xFF) / 100.0f;
}
return;
}
Main代碼:
編譯運行(Fermi M2070):
$ nvcc -O3 -arch=sm_20 simpleMathAoS.cu -o simpleMathAoS $ ./simpleMathAoS innerStruct <<< 8192, 128 >>> elapsed 0.000286 sec
查看load和store性能:
$ nvprof --devices 0 --metrics gld_efficiency,gst_efficiency ./simpleMathAoS gld_efficiency 50.00% gst_efficiency 50.00%
正如預期那樣,都只達到了一般,因為額外那部分消耗都用來load/store 另一個元素了,而這部分不是我們需要的。
__global__ void testInnerArray(InnerArray *data,InnerArray *result, const int n) {
unsigned int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i<n) {
float tmpx = data->x[i];
float tmpy = data->y[i];
tmpx += 10.f;
tmpy += 20.f;
result->x[i] = tmpx;
result->y[i] = tmpy;
}
}
分配global Memory:
int nElem = LEN; size_t nBytes = sizeof(InnerArray); InnerArray *d_A,*d_C; cudaMalloc((InnerArray **)&d_A, nBytes); cudaMalloc((InnerArray **)&d_C, nBytes);
編譯運行:
$ nvcc -O3 -arch=sm_20 simpleMathSoA.cu -o simpleSoA $ ./simpleSoA innerArray <<< 8192, 128 >>> elapsed 0.000200 sec
查看load/store性能:
$ nvprof --devices 0 --metrics gld_efficiency,gst_efficiency ./simpleMathSoA gld_efficiency 100.00% gst_efficiency 100.00%
調節device Memory帶寬利用性能時,主要是力求達到下面兩個目標:
展開循環可以增加更多的獨立的Memory操作,我們在之前博文有詳細介紹如何展開loop,考慮之前的redSegment的例子,我們修改下readOffset來使每個thread執行四個獨立Memory操作,就像下面那樣:
__global__ void readOffsetUnroll4(float *A, float *B, float *C,const int n, int offset) {
unsigned int i = blockIdx.x * blockDim.x * 4 + threadIdx.x;
unsigned int k = i + offset;
if (k + 3 * blockDim.x < n) {
C[i] = A[k]
C[i + blockDim.x] = A[k + blockDim.x] + B[k + blockDim.x];
C[i + 2 * blockDim.x] = A[k + 2 * blockDim.x] + B[k + 2 * blockDim.x];
C[i + 3 * blockDim.x] = A[k + 3 * blockDim.x] + B[k + 3 * blockDim.x];
}
}
編譯運行(可能需要使用-Xptxas -dlcm=ca來啟用L1):
$ ./readSegmentUnroll 0 warmup <<< 32768, 512 >>> offset 0 elapsed 0.001990 sec unroll4 <<< 8192, 512 >>> offset 0 elapsed 0.000599 sec $ ./readSegmentUnroll 11 warmup <<< 32768, 512 >>> offset 11 elapsed 0.002114 sec unroll4 <<< 8192, 512 >>> offset 11 elapsed 0.000615 sec $ ./readSegmentUnroll 128 warmup <<< 32768, 512 >>> offset 128 elapsed 0.001989 sec unroll4 <<< 8192, 512 >>> offset 128 elapsed 0.000598 sec
我們看到,unrolling技術會對性能有巨大影響,比地址對齊影響還大。對於這類I/O-bound的kernel,提高內存獲取的並行性對性能提升的影響,有更高的優先級。不過,我們應該看到,對齊的test比未對齊的test表現依然要好。
Unrolling並不能影響內存操作的總數目(只是影響並行的操作數目),我們可以查看下相關屬性:
$ nvprof --devices 0 --metrics gld_efficiency,gst_efficiency ./readSegmentUnroll 11 readOffset gld_efficiency 49.69% readOffset gst_efficiency 100.00% readOffsetUnroll4 gld_efficiency 50.79% readOffsetUnroll4 gst_efficiency 100.00% $ nvprof --devices 0 --metrics gld_transactions,gst_transactions ./readSegmentUnroll 11 readOffset gld_transactions 132384 readOffset gst_transactions 32928 readOffsetUnroll4 gld_transactions 33152 readOffsetUnroll4 gst_transactions 8064
這方面就是調整grid和block的配置,下面是加上unrolling後的結果:
$ ./readSegmentUnroll 0 1024 22 unroll4 <<< 1024, 1024 >>> offset 0 elapsed 0.000169 sec $ ./readSegmentUnroll 0 512 22 unroll4 <<< 2048, 512 >>> offset 0 elapsed 0.000159 sec $ ./readSegmentUnroll 0 256 22 unroll4 <<< 4096, 256 >>> offset 0 elapsed 0.000157 sec $ ./readSegmentUnroll 0 128 22 unroll4 <<< 8192, 128 >>> offset 0 elapsed 0.000158 sec
表現最好的是block配置256 thread的kernel,雖然128thread會增加並行性,但是依然比256少那麼一點點性能,這個主要是CC版本對應的資源限制決定的,以本代碼為例,Fermi每個SM最多有8個block,每個SM能夠並行的的warp是48個,當使用128個thread(per block)時,每個block中有4個warp,因為每個SM最多8個block能夠同時運行,因此該kernel每個SM最多只能有32個warp,還有16個warp的計算性能沒用上,所以性能差了就,可以使用Occupancy來驗證下。
參考書:《professional cuda c programming》