提高程序效率應該充分利用CPU的高速緩存。要想編寫出對CPU緩存友好的程序就得先明白CPU高速緩存的運行機制。
1、有三級緩存分別為 32k(數據、指令緩存分開,分為32k),256K,6144K(四個CPU之間共享);
2、主頻為2.5G,則一個時鐘周期為1/2.5x10^9=0.4ns(主頻=1/時鐘周期)。
CPU中每條指令執行所需的機器周期不同CPI:平均每條指令的平均時鐘周期個數,注:一個機器周期等於若干個時鐘周期,如一個機器周期等於5個時鐘周期
MIPS = 每秒執行百萬條指令數 = 1/(CPI×時鐘周期)= 主頻/CPI,通過 cat /proc/cpuinfo | grep bogomips 命令可以查看linux系統的mips,對於i5-2400s CPU 其mips=4988.85
從而我們可以算出平均執行一個指令所需時間 T = 1/(4988.85x10^6)=0.2ns,注意:每個CPU時鐘內可並行處理多條指令。
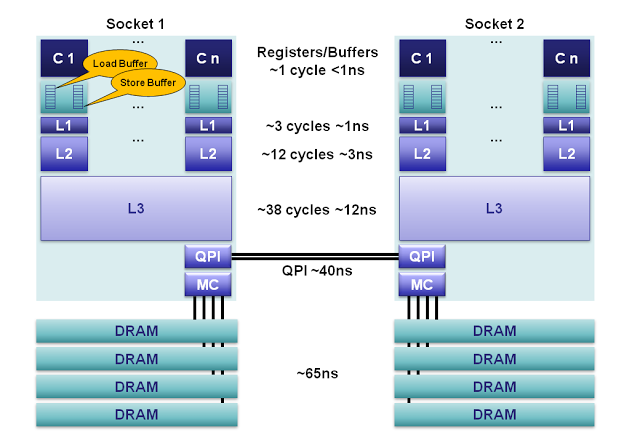
核心到主存的延遲變化范圍很大,大約在10-100納秒。在100ns內,一個2.5GH的CPU可以處理多達100/T=500條指令,所以CPU使用緩存子系統避免了處理核心訪問主存的時延,從而使CPU更加高效的處理指令。所以在程序設計中提供程序高速緩存的命中率對於程序性能的提高幫助很大。尤其是要著重考慮主要數據結構的設計。
1. cache概述
cache,中譯名高速緩沖存儲器,其作用是為了更好的利用局部性原理,減少CPU訪問主存的次數。簡單地說,CPU正在訪問的指令和數據,其可能會被以後多次訪問到,或者是該指令和數據附近的內存區域,也可能會被多次訪問。因此,第一次訪問這一塊區域時,將其復制到cache中,以後訪問該區域的指令或者數據時,就不用再從主存中取出。
2. cache結構
假設內存容量為M,內存地址為m位:那麼尋址范圍為000…00~FFF…F(m位)
倘若把內存地址分為以下三個區間:
 《深入理解計算機系統》p305 英文版 beta draft
《深入理解計算機系統》p305 英文版 beta draft
tag, set index, block offset三個區間有什麼用呢?再來看看Cache的邏輯結構吧:

將此圖與上圖做對比,可以得出各參數如下:
B = 2^b
S = 2^s
現在來解釋一下各個參數的意義:
一個cache被分為S個組,每個組有E個cacheline,而一個cacheline中,有B個存儲單元,現代處理器中,這個存儲單元一般是以字節(通常8個位)為單位的,也是最小的尋址單元。因此,在一個內存地址中,中間的s位決定了該單元被映射到哪一組,而最低的b位決定了該單元在cacheline中的偏移量。valid通常是一位,代表該cacheline是否是有效的(當該cacheline不存在內存映射時,當然是無效的)。tag就是內存地址的高t位,因為可能會有多個內存地址映射到同一個cacheline中,所以該位是用來校驗該cacheline是否是CPU要訪問的內存單元。
當tag和valid校驗成功是,我們稱為cache命中,這時只要將cache中的單元取出,放入CPU寄存器中即可。
當tag或valid校驗失敗的時候,就說明要訪問的內存單元(也可能是連續的一些單元,如int占4個字節,double占8個字節)並不在cache中,這時就需要去內存中取了,這就是cache不命中的情況(cache miss)。當不命中的情況發生時,系統就會從內存中取得該單元,將其裝入cache中,與此同時也放入CPU寄存器中,等待下一步處理。注意,以下這一點對理解linux cache機制非常重要:
下面看看cache的映射機制:
當E=1時, 每組只有一個cacheline。那麼相隔2^(s+b)個單元的2個內存單元,會被映射到同一個cacheline中。(好好想想為什麼?)
當1<E<C/B時,每組有E個cacheline,不同的地址,只要中間s位相同,那麼就會被映射到同一組中,同一組中被映射到哪個cacheline中是依賴於替換算法的。
當E=C/B,此時S=1,每個內存單元都能映射到任意的cacheline。帶有這樣cache的處理器幾乎沒有,因為這種映射機制需要昂貴復雜的硬件來支持。
不管哪種映射,只要發生了cache miss,那麼必定會有一個cacheline大小的內存區域,被取到cache中相應的cacheline。
現代處理器,一般將cache分為2~3級,L1, L2, L3。L1一般為CPU專有,不在多個CPU中共享。L2 cache一般是多個CPU共享的,也可能裝在主板上。L1 cache還可能分為instruction cache, data cache. 這樣CPU能同時取指令和數據。
下面來看看現實中cache的參數,以Intel Pentium處理器為例:
E B S C L1 i-cache 4 32B 128 16KB L1 d-cache 4 32B 128 16KB L2 4 32B 1024~16384 128KB~2MB3. cache miss的代價
cache可能被分為L1, L2, L3, 越往外,訪問時間也就越長,但同時也就越便宜。
L1 cache命中時,訪問時間為1~2個CPU周期。
L1 cache不命中,L2 cache命中,訪問時間為5~10個CPU周期
當要去內存中取單元時,訪問時間可能就到25~100個CPU周期了。
所以,我們總是希望cache的命中率盡可能的高。
4. False Sharing(偽共享)問題
到現在為止,我們似乎還沒有提到cache如何和內存保持一致的問題。
其實在cacheline中,還有其他的標志位,其中一個用於標記cacheline是否被寫過。我們稱為modified位。當modified=1時,表明cacheline被CPU寫過。這說明,該cacheline中的內容可能已經被CPU修改過了,這樣就與內存中相應的那些存儲單元不一致了。因此,如果cacheline被寫過,那麼我們就應該將該cacheline中的內容寫回到內存中,以保持數據的一致性。
現在問題來了,我們什麼時候寫回到內存中呢?當然不會是每當modified位被置1就寫,這樣會極大降低cache的性能,因為每次都要進行內存讀寫操作。事實上,大多數系統都會在這樣的情況下將cacheline中的內容寫回到內存:
現在大多數系統正從單處理器環境慢慢過渡到多處理器環境。一個機器中集成2個,4個,甚至是16個CPU。那麼新的問題來了。
以Intel處理器為典型代表,L1級cache是CPU專有的。
先看以下例子:
多CPU同時訪問同一塊內存區域就是“共享”,就會產生沖突,需要控制協議來協調訪問。會引起“共享”的最小內存區域大小就是一個cache line。因此,當兩個以上CPU都要訪問同一個cache line大小的內存區域時,就會引起沖突,這種情況就叫“共享”。但是,這種情況裡面又包含了“其實不是共享”的“偽共享”情況。比如,兩個處理器各要訪問一個word,這兩個word卻存在於同一個cache line大小的區域裡,這時,從應用邏輯層面說,這兩個處理器並沒有共享內存,因為他們訪問的是不同的內容(不同的word)。但是因為cache line的存在和限制,這兩個CPU要訪問這兩個不同的word時,卻一定要訪問同一個cache line塊,產生了事實上的“共享”。顯然,由於cache line大小限制帶來的這種“偽共享”是我們不想要的,會浪費系統資源(此段摘自如下網址:http://software.intel.com/zh-cn/blogs/2010/02/26/false-sharing/)
對於偽共享問題,有2種比較好的方法:
1. 增大數組元素的間隔使得由不同線程存取的元素位於不同的cache line上。典型的空間換時間
2. 在每個線程中創建全局數組各個元素的本地拷貝,然後結束後再寫回全局數組
而我們要說的linux cache機制,就與第1種方法有關。