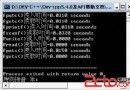
程序員在面試的時候經常會碰到一些題目,給出一個結構體,然後sizeof它一下,問值是多少?比如給出下面這樣一個結構體: [cpp] struct test{ char a; short b; char c; int d; }; 也許一些剛開始學習c語言的同學就會毫不猶豫的把struct當中每個變量所占用的空間相加,等到的結果是8。之後結果就錯了。為什麼呢,首先讓把他們的地址打印出來看個究竟,這是打印出來的結果:a=0x00000000,b=0x0000002,c=0x00000004,d=0x00000008. 很奇怪吧,不像我們預想的那樣,他們是按順序存儲的。這就涉及到一個內存排列的問題:內存對齊。 首先解釋一下,為什麼要內存對齊呢,這和我們的處理器的特性有關系,總線讀取內存總是從偶數字節開始的,如果按照順序進行排列的話,short b 排列的內存地址應該是:0x00000001,但是它需要占用兩個字節的內存空間,如果它要在這個內存地址開始存放的話,需要被讀取兩次,而且讀取完成之後還要進行內存內容拼接,才能完整的得到這個short型的變量。如果它在b=0x0000002這個地址開始存放,那麼只需要讀取一次而且不需要進行內存內容的拼接。然後變量c開始從b之後存放,地址是0x00000004,但是它只占了一個字節,同樣的道理,剩余的空間不能用來存放,但是既然處理器是從偶數字節開始讀取的,那麼為什麼d的開始地址是0x00000008呢。別著急,還有一個規定,就是一個字也就是16bits,雙字(32bits)操作數如果跨越了4字節邊界,或者一個四字操作數跨越了8字節邊界被認為是未對齊的。也就是說,如果d從0x00000006開始存放的話,那他就要跨越0x00000008這個能整除4的邊界,故而需要兩次的內存讀寫。可以回頭看看short b,它是從0x00000002開始存放的,但是它並沒有跨越0x00000004這個邊界值。 還可以舉出這樣一個例子: [cpp] #include<iostream> using namespace std; struct test{ char a; char b; char c; short d; int e; }; int main() { struct test t; int x1 = (unsigned int)(void*)&t.a - (unsigned int)(void*)&t; int x2 = (unsigned int)(void*)&t.b - (unsigned int)(void*)&t; int x3 = (unsigned int)(void*)&t.c - (unsigned int)(void*)&t; int x4 = (unsigned int)(void*)&t.d - (unsigned int)(void*)&t; int x5 = (unsigned int)(void*)&t.e - (unsigned int)(void*)&t; printf("a=0x%p,b=0x%p,c=0x%p,d=0x%p,e=0x%p", x1, x2, x3, x4, x5); cin.get(); } 可以看看打印出來的結果, d的其實地址是0x00000004, 因為如果它從0x00000003開始存放的話,那就它跨越了邊界。 還有一個比較特殊的情況,那就是char類型的變量比較隨和,因為他在32位的處理器中就占有一個字節,因此把它放在哪裡它都不介意,也就是說,因為它只占一個字節,無論存放在哪裡,都只需要讀取一次。 看這樣一個例子: [cpp] struct test{ short a; char b; char c int d; } 打印出來的結果是:a=0x00000000,b=0x0000002,c=0x00000003,d=0x00000008. 缺省的情況下,編譯器默認把結構,棧中的成員數據進行內存對齊。這樣以浪費內存空間的方式節省總線運作的代價。 接下來說一下 #pragma pack(n)這個預處理,主要的功能是改變內存對齊方式的選項,按照給定的n字節進行內存對齊。但是結構體成員對齊的方式有一個很重要的特點,就是最小原則。結構體成員對齊的規則如下: 將自己的本身在內存中實際占用的字節和當前由#pragma pack(n)設定的n進行比較,取其中最下的那個作為結構體當前成員的對齊方式,但是不影響其他結構體成員的對齊方式。 舉個例子: [cpp] #pragma pack(8) struct test_st1{ char a; long b; }; struct test_st2{ char c; struct test_st1 st1; long long d; }; 上面這個例子設定的內存對齊方式是8字節對齊形式。那麼我們看看結構體test_st1,其中a所占內存大小為1,和規定的比較,取最小的,故對齊方式為1字節對齊,對於成員b,因為它占用4個字節,而規定的是8,所以取最小的,對齊方式為4字節對齊,就是從內存地址可以整除4緊挨a存放的地址開始存放b,可以得到結構體的大小為8字節。 之後再來看看結構體test_st2這個結構體,c是本身是一個字節,所以對齊方式是1,而st1是一個結構,那麼這個結構本身在其他結構體中,對齊的方式是什麼呢,是以結構體的大小和給定的對齊方式做比較嗎?不對,它的對齊方式是它成員變量中最大的那個成員變量所占的內存空間和給定的值進行比較,繼而,st1的對齊方式是4,它的起始地址是可以整除4的地方開始。 對於d,因為它占用8個字節的內存,所以它的對齊方式是8,c和st1用去了12個字節,所以d從內存地址可以整除8的地方開始存放,所以這個test_st2結構體的大小是24.給出一個完整的測試程序: [cpp] #include<iostream> using namespace std; #pragma pack(8) struct test_st1{ char a; long b; }; struct test_st2{ char c; struct test_st1 st1; long long d; }; int main() { struct test_st2 t; int x1 = (unsigned int)(void*)&t.c - (unsigned int)(void*)&t; int x2 = (unsigned int)(void*)&t.st1.a - (unsigned int)(void*)&t; int x3 = (unsigned int)(void*)&t.st1.b - (unsigned int)(void*)&t; int x4 = (unsigned int)(void*)&t.d - (unsigned int)(void*)&t; printf("a=0x%p,b=0x%p,c=0x%p,d=0x%p", x1, x2, x3, x4); cin.get(); } 可以自行調試一下,看看內存中他的內存排列。