網絡爬蟲在信息檢索與處理中有很大的作用,是收集網絡信息的重要工具。
接下來就介紹一下爬蟲的簡單實現。
爬蟲的工作流程如下
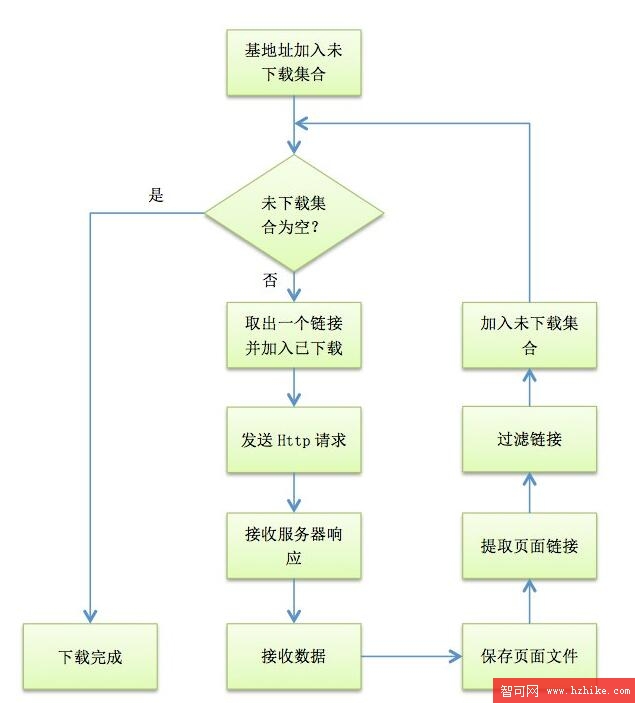
爬蟲自指定的URL地址開始下載網絡資源,直到該地址和所有子地址的指定資源都下載完畢為止。
下面開始逐步分析爬蟲的實現。
1. 待下載集合與已下載集合
為了保存需要下載的URL,同時防止重復下載,我們需要分別用了兩個集合來存放將要下載的URL和已經下載的URL。
因為在保存URL的同時需要保存與URL相關的一些其他信息,如深度,所以這裡我采用了Dictionary來存放這些URL。
具體類型是Dictionary<string, int> 其中string是Url字符串,int是該Url相對於基URL的深度。
每次開始時都檢查未下載的集合,如果已經為空,說明已經下載完畢;如果還有URL,那麼就取出第一個URL加入到已下載的集合中,並且下載這個URL的資源。
2. HTTP請求和響應
C#已經有封裝好的HTTP請求和響應的類HttpWebRequest和HttpWebResponse,所以實現起來方便不少。
為了提高下載的效率,我們可以用多個請求並發的方式同時下載多個URL的資源,一種簡單的做法是采用異步請求的方法。
控制並發的數量可以用如下方法實現
private void DispatchWork()
{
if (_stop) //判斷是否中止下載
{
return;
}
for (int i = 0; i < _reqCount; i++)
{
if (!_reqsBusy[i]) //判斷此編號的工作實例是否空閒
{
RequestResource(i); //讓此工作實例請求資源
}
}
}
由於沒有顯式開新線程,所以用一個工作實例來表示一個邏輯工作線程
? 1 2private bool[] _reqsBusy = null; //每個元素代表一個工作實例是否正在工作
private int _reqCount = 4; //工作實例的數量
每次一個工作實例完成工作,相應的_reqsBusy就設為false,並調用DispatchWork,那麼DispatchWork就能給空閒的實例分配新任務了。
接下來是發送請求
private void RequestResource(int index)
{
int depth;
string url = "";
try
{
lock (_locker)
{
if (_urlsUnload.Count <= 0) //判斷是否還有未下載的URL
{
_workingSignals.FinishWorking(index); //設置工作實例的狀態為Finished
return;
}
_reqsBusy[index] = true;
_workingSignals.StartWorking(index); //設置工作狀態為Working
depth = _urlsUnload.First().Value; //取出第一個未下載的URL
url = _urlsUnload.First().Key;
_urlsLoaded.Add(url, depth); //把該URL加入到已下載裡
_urlsUnload.Remove(url); //把該URL從未下載中移除
}
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(url);
req.Method = _method; //請求方法
req.Accept = _accept; //接受的內容
req.UserAgent = _userAgent; //用戶代理
RequestState rs = new RequestState(req, url, depth, index); //回調方法的參數
var result = req.BeginGetResponse(new AsyncCallback(ReceivedResource), rs); //異步請求
ThreadPool.RegisterWaitForSingleObject(result.AsyncWaitHandle, //注冊超時處理方法
TimeoutCallback, rs, _maxTime, true);
}
catch (WebException we)
{
MessageBox.Show("RequestResource " + we.Message + url + we.Status);
}
}
第7行為了保證多個任務並發時的同步,加上了互斥鎖。_locker是一個Object類型的成員變量。
第9行判斷未下載集合是否為空,如果為空就把當前工作實例狀態設為Finished;如果非空則設為Working並取出一個URL開始下載。當所有工作實例都為Finished的時候,說明下載已經完成。由於每次下載完一個URL後都調用DispatchWork,所以可能激活其他的Finished工作實例重新開始工作。
第26行的請求的額外信息在異步請求的回調方法作為參數傳入,之後還會提到。
第27行開始異步請求,這裡需要傳入一個回調方法作為響應請求時的處理,同時傳入回調方法的參數。
第28行給該異步請求注冊一個超時處理方法TimeoutCallback,最大等待時間是_maxTime,且只處理一次超時,並傳入請求的額外信息作為回調方法的參數。
RequestState的定義是
class RequestState
{
private const int BUFFER_SIZE = 131072; //接收數據包的空間大小
private byte[] _data = new byte[BUFFER_SIZE]; //接收數據包的buffer
private StringBuilder _sb = new StringBuilder(); //存放所有接收到的字符
public HttpWebRequest Req { get; private set; } //請求
public string Url { get; private set; } //請求的URL
public int Depth { get; private set; } //此次請求的相對深度
public int Index { get; private set; } //工作實例的編號
public Stream ResStream { get; set; } //接收數據流
public StringBuilder Html
{
get
{
return _sb;
}
}
public byte[] Data
{
get
{
return _data;
}
}
public int BufferSize
{
get
{
return BUFFER_SIZE;
}
}
public RequestState(HttpWebRequest req, string url, int depth, int index)
{
Req = req;
Url = url;
Depth = depth;
Index = index;
}
}
TimeoutCallback的定義是
private void TimeoutCallback(object state, bool timedOut)
{
if (timedOut) //判斷是否是超時
{
RequestState rs = state as RequestState;
if (rs != null)
{
rs.Req.Abort(); //撤銷請求
}
_reqsBusy[rs.Index] = false; //重置工作狀態
DispatchWork(); //分配新任務
}
}
接下來就是要處理請求的響應了
private void ReceivedResource(IAsyncResult ar)
{
RequestState rs = (RequestState)ar.AsyncState; //得到請求時傳入的參數
HttpWebRequest req = rs.Req;
string url = rs.Url;
try
{
HttpWebResponse res = (HttpWebResponse)req.EndGetResponse(ar); //獲取響應
if (_stop) //判斷是否中止下載
{
res.Close();
req.Abort();
return;
}
if (res != null && res.StatusCode == HttpStatusCode.OK) //判斷是否成功獲取響應
{
Stream resStream = res.GetResponseStream(); //得到資源流
rs.ResStream = resStream;
var result = resStream.BeginRead(rs.Data, 0, rs.BufferSize, //異步請求讀取數據
new AsyncCallback(ReceivedData), rs);
}
else //響應失敗
{
res.Close();
rs.Req.Abort();
_reqsBusy[rs.Index] = false; //重置工作狀態
DispatchWork(); //分配新任務
}
}
catch (WebException we)
{
MessageBox.Show("ReceivedResource " + we.Message + url + we.Status);
}
}
第19行這裡采用了異步的方法來讀數據流是因為我們之前采用了異步的方式請求,不然的話不能夠正常的接收數據。
該異步讀取的方式是按包來讀取的,所以一旦接收到一個包就會調用傳入的回調方法ReceivedData,然後在該方法中處理收到的數據。
該方法同時傳入了接收數據的空間rs.Data和空間的大小rs.BufferSize。
接下來是接收數據和處理
private void ReceivedData(IAsyncResult ar)
{
RequestState rs = (RequestState)ar.AsyncState; //獲取參數
HttpWebRequest req = rs.Req;
Stream resStream = rs.ResStream;
string url = rs.Url;
int depth = rs.Depth;
string Html = null;
int index = rs.Index;
int read = 0;
try
{
read = resStream.EndRead(ar); //獲得數據讀取結果
if (_stop)//判斷是否中止下載
{
rs.ResStream.Close();
req.Abort();
return;
}
if (read > 0)
{
MemoryStream ms = new MemoryStream(rs.Data, 0, read); //利用獲得的數據創建內存流
StreamReader reader = new StreamReader(ms, _encoding);
string str = reader.ReadToEnd(); //讀取所有字符
rs.Html.Append(str); // 添加到之前的末尾
var result = resStream.BeginRead(rs.Data, 0, rs.BufferSize, //再次異步請求讀取數據
new AsyncCallback(ReceivedData), rs);
return;
}
html = rs.Html.ToString();
SaveContents(Html, url); //保存到本地
string[] links = GetLinks(Html); //獲取頁面中的鏈接
AddUrls(links, depth + 1); //過濾鏈接並添加到未下載集合中
_reqsBusy[index] = false; //重置工作狀態
DispatchWork(); //分配新任務
}
catch (WebException we)
{
MessageBox.Show("ReceivedData Web " + we.Message + url + we.Status);
}
}
第14行獲得了讀取的數據大小read,如果read>0說明數據可能還沒有讀完,所以在27行繼續請求讀下一個數據包;
如果read<=0說明所有數據已經接收完畢,這時rs.Html中存放了完整的Html數據,就可以進行下一步的處理了。
第26行把這一次得到的字符串拼接在之前保存的字符串的後面,最後就能得到完整的Html字符串。
然後說一下判斷所有任務完成的處理
private void StartDownload()
{
_checkTimer = new Timer(new TimerCallback(CheckFinish), null, 0, 300);
DispatchWork();
}
private void CheckFinish(object param)
{
if (_workingSignals.IsFinished()) //檢查是否所有工作實例都為Finished
{
_checkTimer.Dispose(); //停止定時器
_checkTimer = null;
if (DownloadFinish != null && _ui != null) //判斷是否注冊了完成事件
{
_ui.Dispatcher.Invoke(DownloadFinish, _index); //調用事件
}
}
}
第3行創建了一個定時器,每過300ms調用一次CheckFinish來判斷是否完成任務。
第15行提供了一個完成任務時的事件,可以給客戶程序注冊。_index裡存放了當前下載URL的個數。
該事件的定義是
public delegate void DownloadFinishHandler(int count);
/// <summary>
/// 全部鏈接下載分析完畢後觸發
/// </summary>
public event DownloadFinishHandler DownloadFinish = null;
3. 保存頁面文件
這一部分可簡單可復雜,如果只要簡單地把Html代碼全部保存下來的話,直接存文件就行了。
private void SaveContents(string Html, string url)
{
if (string.IsNullOrEmpty(Html)) //判斷Html字符串是否有效
{
return;
}
string path = string.Format("{0}\\{1}.txt", _path, _index++); //生成文件名
try
{
using (StreamWriter fs = new StreamWriter(path))
{
fs.Write(Html); //寫文件
}
}
catch (IOException ioe)
{
MessageBox.Show("SaveContents IO" + ioe.Message + " path=" + path);
}
if (ContentsSaved != null)
{
_ui.Dispatcher.Invoke(ContentsSaved, path, url); //調用保存文件事件
}
}
第23行這裡又出現了一個事件,是保存文件之後觸發的,客戶程序可以之前進行注冊。
? 1 2 3 4 5 6public delegate void ContentsSavedHandler(string path, string url);
/// <summary>
/// 文件被保存到本地後觸發
/// </summary>
public event ContentsSavedHandler ContentsSaved = null;
4. 提取頁面鏈接
提取鏈接用正則表達式就能搞定了,不懂的可以上網搜。
下面的字符串就能匹配到頁面中的鏈接
http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
詳細見代碼
private string[] GetLinks(string Html)
{
const string pattern = @"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r = new Regex(pattern, RegexOptions.IgnoreCase); //新建正則模式
MatchCollection m = r.Matches(Html); //獲得匹配結果
string[] links = new string[m.Count];
for (int i = 0; i < m.Count; i++)
{
links[i] = m[i].ToString(); //提取出結果
}
return links;
}
5. 鏈接的過濾
不是所有的鏈接我們都需要下載,所以通過過濾,去掉我們不需要的鏈接
這些鏈接一般有:
1)、已經下載的鏈接
2)、深度過大的鏈接
3)、其他的不需要的資源,如圖片、CSS等
//判斷鏈接是否已經下載或者已經處於未下載集合中
private bool UrlExists(string url)
{
bool result = _urlsUnload.ContainsKey(url);
result |= _urlsLoaded.ContainsKey(url);
return result;
}
private bool UrlAvailable(string url)
{
if (UrlExists(url))
{
return false; //已經存在
}
if (url.Contains(".jpg") || url.Contains(".gif")
|| url.Contains(".png") || url.Contains(".CSS")
|| url.Contains(".JS"))
{
return false; //去掉一些圖片之類的資源
}
return true;
}
private void AddUrls(string[] urls, int depth)
{
if (depth >= _maxDepth)
{
return; //深度過大
}
foreach (string url in urls)
{
string cleanUrl = url.Trim(); //去掉前後空格
cleanUrl = cleanUrl.TrimEnd('/'); //統一去掉最後面的'/'
if (UrlAvailable(cleanUrl))
{
if (cleanUrl.Contains(_baseUrl))
{
_urlsUnload.Add(cleanUrl, depth); //是內鏈,直接加入未下載集合
}
else
{
// 外鏈處理
}
}
}
}
第34行的_baseUrl是爬取的基地址,如http://news.sina.com.cn/,將會保存為news.sina.com.cn,當一個URL包含此字符串時,說明是該基地址下的鏈接;否則為外鏈。
_baseUrl的處理如下,_rootUrl是第一個要下載的URL
? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24/// <summary>
/// 下載根Url
/// </summary>
public string RootUrl
{
get
{
return _rootUrl;
}
set
{
if (!value.Contains("http://"))
{
_rootUrl = "http://" + value;
}
else
{
_rootUrl = value;
}
_baseUrl = _rootUrl.Replace("www.", ""); //全站的話去掉www
_baseUrl = _baseUrl.Replace("http://", ""); //去掉協議名
_baseUrl = _baseUrl.TrimEnd('/'); //去掉末尾的'/'
}
}
至此,基本的爬蟲功能實現就介紹完了。