一、什麼是Unicode
先從ASCII說起,ASCII是用來表示英文字符的一種編碼規范。每個ASCII字符占用1個字節,因此,ASCII編碼可以表示的最大字符數是255(00H—FFH)。其實,英文字符並沒有那麼多,一般只用前128個(00H—7FH,最高位為0),其中包括了控制字符、數字、大小寫字母和其它一些符號。而最高位為1的另128個字符(80H—FFH)被稱為“擴展ASCII”,一般用來存放英文的制表符、部分音標字符等等的一些其它符號。
這種字符編碼規則顯然用來處理英文沒有什麼問題。但是面對中文、阿拉伯文等復雜的文字,255個字符顯然不夠用。
於是,各個國家紛紛制定了自己的文字編碼規范,其中中文的文字編碼規范叫做“GB2312—80”,它是和ASCII兼容的一種編碼規范,其實就是利用擴展ASCII沒有真正標准化這一點,把一個中文字符用兩個擴展ASCII字符來表示,以區分ASCII碼部分。
但是這個方法有問題,最大的問題就是中文的文字編碼和擴展ASCII碼有重疊。而很多軟件利用擴展ASCII碼的英文制表符來畫表格,這樣的軟件用到中文系統中,這些表格就會被誤認作中文字符,出現亂碼。
另外,由於各國和各地區都有自己的文字編碼規則,它們互相沖突,這給各國和各地區交換信息帶來了很大的麻煩。
要真正解決這個問題,不能從擴展ASCII的角度入手,而必須有一個全新的編碼系統,這個系統要可以將中文、法文、德文……等等所有的文字統一起來考慮,為每一個文字都分配一個單獨的編碼。
於是,Unicode誕生了。
Unicode也是一種字符編碼方法,它占用兩個字節(0000H—FFFFH),容納65536個字符,這完全可以容納全世界所有語言文字的編碼。
在Unicode裡,所有的字符被一視同仁,漢字不再使用“兩個擴展ASCII”,而是使用“1個Unicode”,也就是說,所有的文字都按一個字符來處理,它們都有一個唯一的Unicode碼。
二、使用Unicode編碼的好處
使用Unicode編碼可以使您的工程同時支持多種語言,使您的工程國際化。
另外,Windows NT是使用Unicode進行開發的,整個系統都是基於Unicode的。如果調用一個API函數並給它傳遞一個ANSI(ASCII字符集以及由此派生並兼容的字符集,如:GB2312,通常稱為ANSI字符集)字符串,那麼系統首先要將字符串轉換成Unicode,然後將Unicode字符串傳遞給操作系統。如果希望函數返回ANSI字符串,系統就會首先將Unicode字符串轉換成ANSI字符串,然後將結果返回給您的應用程序。進行這些字符串的轉換需要占用系統的時間和內存。如果用Unicode來開發應用程序,就能夠使您的應用程序更加有效地運行。
下面例舉幾個字符的編碼以簡單演示ANSI和Unicode的區別:
字符 A N 和 ANSI碼 41H 4eH cdbaH Unicode碼 0041H 004eH 548cH三、使用C++進行Unicode編程
對寬字符的支持其實是ANSI C標准的一部分,用以支持多字節表示一個字符。寬字符和Unicode並不完全等同,Unicode只是寬字符的一種編碼方式。
1、寬字符的定義
在ANSI中,一個字符(char)的長度為一個字節(Byte)。使用Unicode時,一個字符占據一個字,C++在wchar.h頭文件中定義了最基本的寬字符類型wchar_t:
typedef unsigned short wchar_t;
從這裡我們可以清楚地看到,所謂的寬字符就是無符號短整數。
2、常量寬字符串
對C++程序員而言,構造字符串常量是一項經常性的工作。那麼,如何構造寬字符字符串常量呢?很簡單,只要在字符串常量前加上一個大寫的L就可以了,比如:
wchar_t *str1=L" Hello";
這個L非常重要,只有帶上它,編譯器才知道你要將字符串存成一個字符一個字。還要注意,在L和字符串之間不能有空格。
3、寬字符串庫函數
為了操作寬字符串,C++專門定義了一套函數,比如求寬字符串長度的函數是
size_t __cdel wchlen(const wchar_t*);
為什麼要專門定義這些函數呢?最根本的原因是,ANSI下的字符串都是以’\0’來標識字符串尾的(Unicode字符串以“\0\0”結束),許多字符串函數的正確操作均是以此為基礎進行。而我們知道,在寬字符的情況下,一個字符在內存中要占據一個字的空間,這就會使操作ANSI字符的字符串函數無法正確操作。以”Hello”字符串為例,在寬字符下,它的五個字符是:
0x0048 0x0065 0x006c 0x006c 0x006f
在內存中,實際的排列是:
48 00 65 00 6c 00 6c 00 6f 00
於是,ANSI字符串函數,如strlen,在碰到第一個48後的00時,就會認為字符串到尾了,用strlen對寬字符串求長度的結果就永遠會是1!
4、用宏實現對ANSI和Unicode通用的編程
可見,C++有一整套的數據類型和函數實現Unicode編程,也就是說,您完全可以使用C++實現Unicode編程。
如果我們想要我們的程序有兩個版本:ANSI版本和Unicode版本。當然,編寫兩套代碼分別實現ANSI版本和Unicode版本完全是行得通的。但是,針對ANSI字符和Unicode字符維護兩套代碼是非常麻煩的事情。為了減輕編程的負擔,C++定義了一系列的宏,幫助您實現對ANSI和Unicode的通用編程。
C++宏實現ANSI和Unicode的通用編程的本質是根據”_UNICODE”(注意,有下劃線)定義與否,這些宏展開為ANSI或Unicode字符(字符串)。
如下是tchar.h頭文件中部分代碼摘抄:
#ifdef _UNICODE
typedef wchar_t TCHAR;
#define __T(x) L##x
#define _T(x) __T(x)
#else
#define __T(x) x
typedef char TCHAR;
#endif
可見,這些宏根據”_UNICODE” 定義與否,分別展開為ANSI或Unicode字符。 tchar.h頭文件中定義的宏可以分為兩類:
A、實現字符和常量字符串定義的宏我們只列出兩個最常用的宏:
宏 未定義_UNICODE(ANSI字符) 定義了_UNICODE(Unicode字符) TCHAR char wchar_t _T(x) x L##x注意:
“##”是ANSI C標准的預處理語法,它叫做“粘貼符號”,表示將前面的L添加到宏參數上。也就是說,如果我們寫_T(“Hello”),展開後即為L“Hello”
B、實現字符串函數調用的宏
C++為字符串函數也定義了一系列宏,同樣,我們只例舉幾個常用的宏:
宏 未定義_UNICODE(ANSI字符) 定義了_UNICODE(Unicode字符) _tcschr strchr wcschr _tcscmp strcmp wcscmp _tcslen strlen wcslen
四、使用Win32 API進行Unicode編程
Win32 API中定義了一些自己的字符數據類型。這些數據類型的定義在winnt.h頭文件中。例如:
typedef char CHAR;
typedef unsigned short WCHAR; // wc, 16-bit UNICODE character
typedef CONST CHAR *LPCSTR, *PCSTR;
Win32 API在winnt.h頭文件中定義了一些實現字符和常量字符串的宏進行ANSI/Unicode通用編程。同樣,只例舉幾個最常用的:#ifdef UNICODE
typedef WCHAR TCHAR, *PTCHAR;
typedef LPWSTR LPTCH, PTCH;
typedef LPWSTR PTSTR, LPTSTR;
typedef LPCWSTR LPCTSTR;
#define __TEXT(quote) L##quote // r_winnt
#else /* UNICODE */ // r_winnt
typedef char TCHAR, *PTCHAR;
typedef LPSTR LPTCH, PTCH;
typedef LPSTR PTSTR, LPTSTR;
typedef LPCSTR LPCTSTR;
#define __TEXT(quote) quote // r_winnt
#endif /* UNICODE */ // r_winnt
從以上頭文件可以看出,winnt.h根據是否定義了UNICODE(沒有下劃線),進行條件編譯。
Win32 API也定義了一套字符串函數,它們根據是否定義了“UNICODE”分別展開為ANSI和Unicode字符串函數。如:lstrlen。API的字符串操作函數和C++的操作函數可以實現相同的功能,所以,如果需要的話,建議您盡可能使用C++的字符串函數,沒必要去花太多精力再去學習API的這些東西。
也許您從來沒有注意到,Win32 API實際上有兩個版本。一個版本接受MBCS字符串,另一個接受Unicode字符串。例如:其實根本沒有SetWindowText()這個API函數,相反,有SetWindowTextA()和SetWindowTextW()。後綴A表明這是MBCS函數,後綴W表示這是Unicode版本的函數。這些API函數的頭文件在winuser.h中聲明,下面例舉winuser.h中的SetWindowText()函數的聲明部分:#ifdef UNICODE 可見,API函數根據定義UNICODE與否決定指向Unicode版本還是MBCS版本。
#define SetWindowText SetWindowTextW
#else
#define SetWindowText SetWindowTextA
#endif // !UNICODE
細心的讀者可能已經注意到了UNICODE和_UNICODE的區別,前者沒有下劃線,專門用於Windows頭文件;後者有一個前綴下劃線,專門用於C運行時頭文件。換句話說,也就是在ANSI C++語言裡面根據_UNICODE(有下劃線)定義與否,各宏分別展開為Unicode或ANSI字符,在Windows裡面根據UNICODE(無下劃線)定義與否,各宏分別展開為Unicode或ANSI字符。
在後面我們將會看到,實際使用中我們不加嚴格區分,同時定義_UNICODE和UNICODE,以實現UNICODE版本編程。
五、VC++6.0中編寫Unicode編碼的應用程序
VC++ 6.0支持Unicode編程,但默認的是ANSI,所以開發人員只需要稍微改變一下編寫代碼的習慣便可以輕松編寫支持UNICODE的應用程序。
使用VC++ 6.0進行Unicode編程主要做以下幾項工作:
1、為工程添加UNICODE和_UNICODE預處理選項。
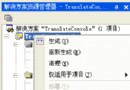
具體步驟:打開[工程]->[設置…]對話框,如圖1所示,在C/C++標簽對話框的“預處理程序定義”中去除_MBCS,加上_UNICODE,UNICODE。(注意中間用逗號隔開)改動後如圖2:
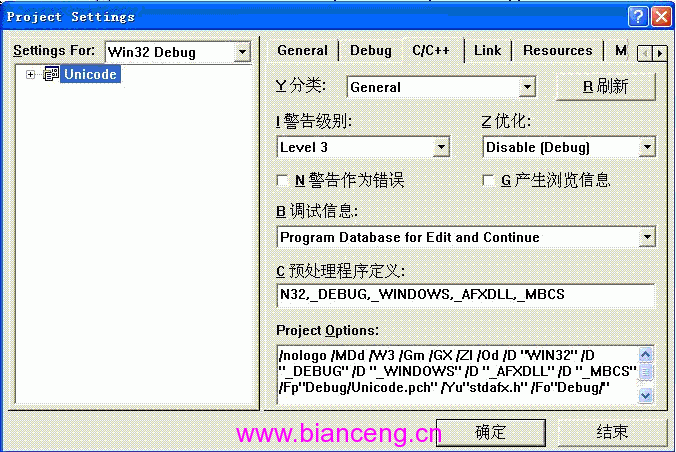
圖一
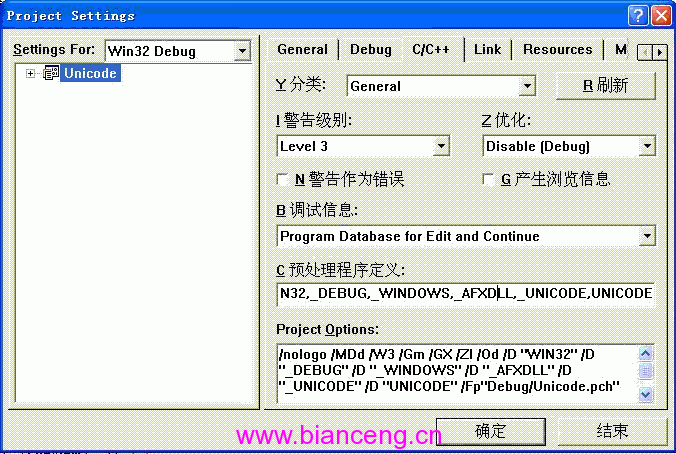
圖二
在沒有定義UNICODE和_UNICODE時,所有函數和類型都默認使用ANSI的版本;在定義了UNICODE和_UNICODE之後,所有的MFC類和Windows API都變成了寬字節版本了。
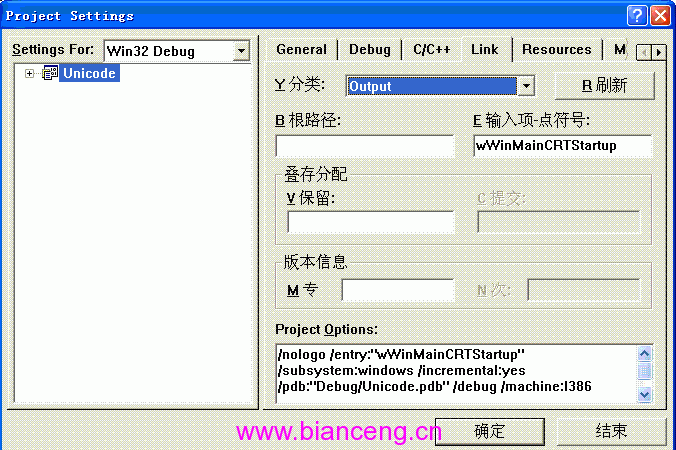
2、設置程序入口點
因為MFC應用程序有針對Unicode專用的程序入口點,我們要設置entry point。否則就會出現連接錯誤。
設置entry point的方法是:打開[工程]->[設置…]對話框,在Link頁的Output類別的Entry Point裡填上wWinMainCRTStartup。
圖三
3、使用ANSI/Unicode通用數據類型
微軟提供了一些ANSI和Unicode兼容的通用數據類型,我們最常用的數據類型有_T ,TCHAR,LPTSTR,LPCTSTR。
順便說一下,LPCTSTR和const TCHAR*是完全等同的。其中L表示long指針,這是為了兼容Windows 3.1等16位操作系統遺留下來的,在Win32 中以及其它的32位操作系統中,long指針和near指針及far修飾符都是為了兼容的作用,沒有實際意義。P(pointer)表示這是一個指針;C(const)表示是一個常量;T(_T宏)表示兼容ANSI和Unicode,STR(string)表示這個變量是一個字符串。綜上可以看出,LPCTSTR表示一個指向常固定地址的可以根據一些宏定義改變語義的字符串。比如:
TCHAR* szText=_T(“Hello!”);使用函數中的參數最好也要有變化,比如:
TCHAR szText[]=_T(“I Love You”);
LPCTSTR lpszText=_T(“大家好!”);MessageBox(_T(“你好”));
其實,在上面的語句中,即使您不加_T宏,MessageBox函數也會自動把“你好”字符串進行強制轉換。但我還是推薦您使用_T宏,以表示您有Unicode編碼意識。
4、修改字符串運算問題
一些字符串操作函數需要獲取字符串的字符數(sizeof(szBuffer)/sizeof(TCHAR)),而另一些函數可能需要獲取字符串的字節數sizeof(szBuffer)。您應該注意該問題並仔細分析字符串操作函數,以確定能夠得到正確的結果。
ANSI操作函數以str開頭,如strcpy(),strcat(),strlen();
Unicode操作函數以wcs開頭,如wcscpy,wcscpy(),wcslen();
ANSI/Unicode操作函數以_tcs開頭 _tcscpy(C運行期庫);
ANSI/Unicode操作函數以lstr開頭 lstrcpy(Windows函數);
考慮ANSI和Unicode的兼容,我們需要使用以_tcs開頭或lstr開頭的通用字符串操作函數。
六、舉個Unicode編程的例子
第一步:
打開VC++6.0,新建基於對話框的工程Unicode,主對話框IDD_UNICODE_DIALOG中加入一個按鈕控件,雙擊該控件並添加該控件的響應函數:
void CUnicodeDlg::OnButton1()
{
TCHAR* str1=_T("ANSI和UNICODE編碼試驗");
m_disp=str1;
UpdateData(FALSE);
}
添加靜態文本框IDC_DISP,使用ClassWizard給該控件添加CString類型變量m_disp。使用默認ANSI編碼環境編譯該工程,生成Unicode.exe。
第二步:
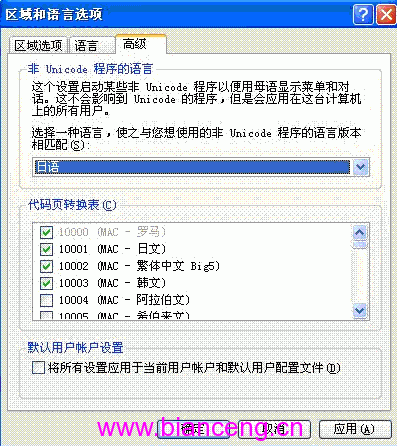
打開“控制面板”,單擊“日期、時間、語言和區域設置”選項,在“日期、時間、語言和區域設置”窗口中繼續單擊“區域和語言選項”選項,彈出“區域和語言選項”對話框。在該對話框中,單擊“高級”標簽,將“非Unicode的程序的語言”選項改為“日語”,單擊“應用”按鈕,如圖四:
圖四
彈出的對話框單擊“是”,重新啟動計算機使設置生效。
運行Unicode.exe程序並單擊“Button1”按鈕,看,靜態文本框出現了亂碼。
第三步:
改為Unicode編碼環境編譯該工程,生成Unicode.exe。再次運行Unicode.exe程序並單擊“Button1”按鈕。看到Unicode編碼的優勢了吧。
就說這些吧,祝您好運。
本文配套源碼