簡介
如果你編寫的程序是針對非英語國家的用戶,如中國、日本、東歐和中東地區,那麼你一 定要熟悉 UNICODE 字符集。尤其是用 Visual C++/MFC 編寫針對上述國家和地區的用戶的程 序時,如果你想讓自己的應用程序得到更廣泛的用戶,那麼必須考慮代碼 UNICODE 的兼容性 ,也就是說它既在 ASCII 模式下運行 ,也能在UNICODE 模式下運行。本文將介紹 UNICODE 的一些基本編程知識,澄清很多人(包括我自己)在這個問題上存在的模糊認識。對於任何 使用 Visual C++ 和/或 MFC 編程的人來說,這篇文章肯定值得一讀。
UNICODE到底是什麼?
UNICODE 是目前用來解決 ASCII 碼 256 個字符限制問題的一種比較流行的解決方案。大 家知道,ASCII 字符集只有256個字符,用 0-255 之間的數字來表示。包括大小寫字母、數 字以及少數特殊字符;如標點符號、貨幣符號等。對於大多數拉丁語言來說,這些字符已經 夠用。但是,許多亞洲和東方語言所用的字符遠遠不止256個字符。有些超過千個。人們為了 突破 ASCII 碼字符數的限制,試圖用一種簡單的方法來針對超過256個字符的語言編寫計算 機程序。於是 UNICODE 應運而生。UNICODE 通過用雙字節來表示一個字符,從而在更大范圍 內將數字代碼映射到多種語言的字符集。
Visual C++的解決方案
作為軟件開發人員,如何熟練有效地使用 UNICODE 呢?如果你正在用 Visual C++ 編寫 程序,UNICODE 兼容性意味著你的程序是否具有國際化特征,也就是說你的應用程序是針對 本地市場還是國際市場。一旦你作出了決定,那麼就得在代碼中實現具體細節。好在 Visual C++ 提供了很多內建功能來支持 UNICODE,在創建工程時就可以利用 Visual C++ 提供的這 些功能。在產生應用程序框架代碼之前,AppWizard 允許開發人員決定是否支持 UNICODE。 Win32 SDK 包含有一些數據類型遵循 UNICODE 編碼規則,MFC 以宏的形式提供了將一般文本 轉換成 UNICODE 數據類型的途徑。開發人員只需要稍微改變一下編寫代碼的習慣便可以輕松 編寫支持 UNICODE 的應用。
字符串
C 程序員一般是用 char 關鍵字象下面這樣來聲明一個字符串數組:
char str [100];
象下面這樣聲明函數原形:
void strcpy( char *out, char *in );
為了將上面的聲明改成支持雙字節的 UNICODE 字符集,可以用下面的方法:
wchar_t str[100];
或者
void wcscpy( wchar_t *out, wchar_t *in );
此外,微軟還提供一種通過預處理指令來實現 UNICODE。每當用 Visual C++ 創建新工程 時,只要確定是否支持另外一種字符集,則 AppWizard 將會在頭文件中插入預處理指令。這 些指令告訴編譯器程序想要支持何種字符集。這樣在使用VC++提供的通用數據類型時,編譯 器將用相應的數據類型把通用數據類型替換成所需要支持的字符集。這樣很容易將代碼重新 編譯成支持其它字符集的程序。
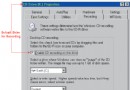
為了在 Visual C++ 6.0 中激活 UNICODE 標准,可以這樣做:打開工程文件後,從主菜 單中選擇“Project | Settings”打開工程設置對話框 => 然後選擇 “C/C++”標簽 => 在“Preprocessor definitions”編輯框中添 加 UNICODE 或者 _UNICODE 預處理宏指令。如圖一所示:
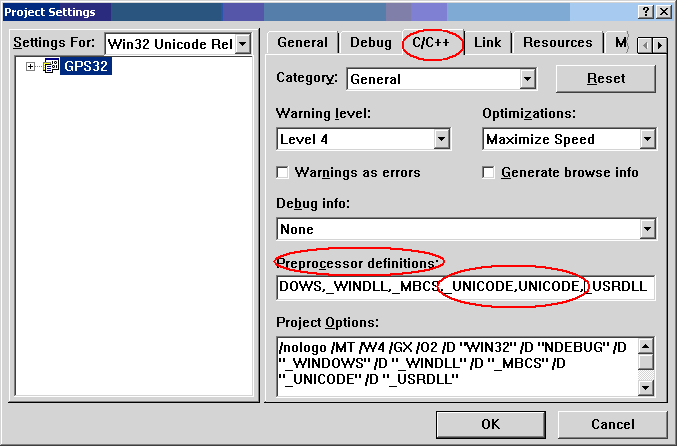
圖一 Project Settings 對話框
注意這裡的 UNICODE 和 _UNICODE 有什麼區別呢?前者沒有下劃線,專門用於 Windows 頭文件;後者有一個前綴下劃線,專門用於 C 運行時頭文件。
在代碼中,凡是用關鍵字 char 的地方都用 TCHAR 取代;凡是用 char * 的地方都用 LPTSTR 取代;凡是定義在雙引號中的字符串常量(如"VCKBASE Online Journal" )都用 TEXT 宏重寫:
TEXT("VCKBASE Online Journal");
TEXT 宏的主要作用是當 定義了 UNICODE/_UNICODE 預處理指令時,字符串被標志為雙字節字符串,否則字符串被標 示為 ANSI 字符串。TEXT 的定義如下:
TEXT(
LPTSTR string // ANSI 或者 Unicode 字符串
);
參數 string 為字符串指針,指向被解釋的 Unicode 或者 ANSI 字符串
在文檔中 微軟提供了包括通用類型在內的幾種數據類型都與 ASCII 和 UNICODE兼容。這一 點可以參考微軟在線文檔有關“通用數據類型和數據類型”的章節。
例子代碼
下面通過一些簡單的例子來進一步探討 UNICODE 編程。
使用 ASCII 字符集的“Hello, World”:
//*********************************
// 用 MFC 實現的"Hello World!" 代碼
//*********************************
//hello.cpp
#include <afxwin.h>
// Declare the application class
class CHelloApp : public CWinApp
{
public:
virtual BOOL InitInstance();
};
// Create an instance of the application class
CHelloApp HelloApp;
// Declare the main window class
class CHelloWindow : public CFrameWnd
{
CStatic* cs;
public:
CHelloWindow();
};
// The InitInstance function is called each
// time the application first executes.
BOOL CHelloApp::InitInstance()
{
m_pMainWnd = new CHelloWindow();
m_pMainWnd->ShowWindow(m_nCmdShow);
m_pMainWnd->UpdateWindow();
return TRUE;
}
// The constructor for the window class
CHelloWindow::CHelloWindow()
{
// Create the window itself
Create(NULL, "Hello World!", WS_OVERLAPPEDWINDOW,
CRect(0,0,200,200));
// Create a static label
cs = new CStatic();
cs->Create("hello world", WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(50,80,150,150), this);
}
修改上面的代碼使之支持 UNICODE 字符集,串常量必須要改成對應的 UNICODE 字符。方 法是對串常量使用TEXT 宏。這個宏將告訴預處理器檢查使用什麼樣的字符標准:
// The constructor for the window class
CHelloWindow::CHelloWindow()
{
// Create the window itself
Create(NULL, TEXT("Hello World!"), WS_OVERLAPPEDWINDOW,
CRect(0,0,200,200));
// Create a static label
cs = new CStatic();
cs->Create( TEXT("hello world!"), WS_CHILD|WS_VISIBLE|SS_CENTER,
CRect(50,80,150,150), this);
}
當預處理器碰到通用數據類型,它便檢查 AFXWIN.H 頭文件的 _UNICODE 定義。然後根據 UNICODE 定義插入相應的的數據類型。
下面的這個例子使用 Win32 API 函數和通用數據類型設置 C 盤的卷標。
//******************
// 設置 C 盤的卷標
//******************
// drvsvl.cpp
#include <windows.h>
#include <iostream.h>
void main()
{
BOOL success;
char volumeName[MAX_PATH];
cout << "輸入新的 C 盤卷標:";
cin >> volumeName;
success = SetVolumeLabel("c:\\", volumeName);
if (success)
cout << "成功\n";
else
cout << "錯誤代碼:" << GetLastError() << endl;
}
通過使用 TCHAR 數據類型,將這段代碼最上面的字符數組聲明為兩個字節的字符。TEXT 宏再次被用於字符串常量:
void main()
{
BOOL success;
TCHAR volumeName[MAX_PATH];
cout << TEXT("輸入新的 C 盤卷標: ");
cin >> volumeName;
success = SetVolumeLabel(TEXT("c:\\" ), volumeName);
if (success)
cout << TEXT("成功\n");
else
cout << TEXT("錯誤代碼:") << GetLastError() << endl;
}
Visual C++ 中的通用數據類型
Visual C++ 提供了幾種 MFC 專用的數據類型用於創建具有國際化特性的應用程序。這些 定義很通用,完全可以在 UNICODE、ASCII、DBCS (雙字節字符集) 和 MBCS (多字節字符集) 。由於篇幅所限,本文不打算涉及所有上面提到的這些字符集。有關它們的詳細資料請參考 相關資料。MFC 提供了一種透明的方式來實現這些字符集。通用數據類型的映射到哪個字符 集以及映射方式是根據工程的設置決定的,默認值為 ASCII 模式,其它幾個可選項是 MBCS 、DBCS 或者 UNICODE。本文主要討論 UNICODE,所以下表中只列出了 ASCII 與 UNICODE 字 符之間的映射關系:
表一:
通用 MFC 數據類型 映射到 ASCII 映射到 UNICODE 注釋 _TCHAR char wchar_t _TCHAR 是一個映射宏,當定義 UNICODE 時,該數據類型映射到 wchar_t ,如果沒有定義 UNICODE,那麼它映射到 char。 _T 或 _TEXT char 常量字符串 wchar_t 常量字符串 功能與宏相同,在 ASCII 模式下,它們被忽略,也就是說被預處理器刪除 掉,但是如果定義了UNICODE, 則它們會將常量字符串轉換成等價的 UNICODE 。 LPTSTR char*, LPSTR(Win32) wchar_t* 可移植的32位字符串指針。它將字符類型映射到工程設置的類型。 LPCTSTR const char*, LPCSTR(Win32) const wchar_t* 可移植的32位常量字符串指針。它將字符類型常量映射到工程設置的類型 。使用表一中列出的通用數據類型,開發人員可以保證所創建的工程始終是針對一種字符集 ,這些通用數據類型就相當於占位符,在編譯時被特定的字節所替代,使得應用程序在 ASCII 和 UNICODE 模式下都能運行。但是,有一點要特別注意,那就是上述的通用數據類型 為微軟專有,與 ANSI 標准並不兼容。有關微軟提供的這些通用數據類型詳細描述請參考 MSDN 庫文檔。
有關技術注釋
為了成功編譯支持 UNICODE 的 MFC 程序,必須使用 MFC 的 UNICODE 版本庫。該庫在定 制安裝Visual C++ 時是個可選安裝項。
有一點很重要:那就是不使用 UNICODE 標准在外觀上並不影響程序的執行。也就是說, 上面提到過的代碼不管設沒設置 _UNICODE 生成選項,最終都能生成正常運行的程序。當開 發人員使用多個版本的Win32 API函數時才會出現問題。
在使用多個版本的 Win32 API函數(任何有字符或字符串作為參數的 Win32 API函數)時 ,編譯器根據是否設置 _UNICODE 指令來決定調用正確的函數。如果沒有定義_UNICODE,那 麼編譯器將默認調用 ASCII 版本函數。
結束語
綜上所述可以看到,編譯 UNICODE 版本的程序並不難。只是在編寫代碼時記住函數調用 上些微的變化。微軟為此提供的擴展是開發人員能夠以透明的方式選擇所用的字符集,為應 用軟件的國際化打開了方便之門。
Jeffrey Richter 在他的《Windows 核心編程》(機械工業出版社-王建華、張煥生、侯 麗坤等譯)一書中專門用一章討論了 UNICODE。翻譯得也不錯。有興趣的朋友不妨找來看看 。