一、數組的指針、指針數組以及指向指針的指針
考慮數組的指針的時候我們要同時考慮類型和維數這兩個屬性。換一句話,就是說一個數組排除在其中存儲的數值,那麼可以用類型和維數來位置表示他的種類。
A)一維數組
在c和c++中數組的指針就是數組的起始地址(也就第一個元素的地址),而且標准文檔規定數組名代表數組的地址(這是地址數值層面的數組表示)。例如:
int a[10];
int *p;
p=&a[0]//和p=a是等價的:
因為a是數組名,所以他是該數組的地址,同時因為第一個元素為a[0],那麼&a[0]也代表了該數組的地址。但是我們是不是就說一個數組名和該數組的第一個元素的&運算是一回事呢?在一維的時候當時是的,但是在高維的時候,我們要考慮到維數給數組帶來的影響。
a[10]是一個數組,a是數組名,它是一個包含10個int類型的數組類型,不是一般的指針變量噢!(雖然標准文檔規定在c++中從int[]到int*直接轉換是可以的,在使用的時候似乎在函數的參數為指針的時候,我們將該數組名賦值沒有任何異樣),a代表數組的首地址,在數字層面和a[10]的地址一樣。這樣我們就可以使用指針變量以及a來操作這個數組了。
所以我們要注意以下問題:
(1) p[i]和a[i]都是代表該數組的第i+1個元素;
(2) p+i和a+i代表了第i+1個元素的地址,所以我們也可以使用 *(p+I)和*(a+I)來引用對象元素;
(3)p+1不是對於指針數量上加一,而是表示從當前的位置跳過當前指針指向類型長度的空間,對於win32的int為4byte;
B)多維數組
對於二維數組a[4][6];由於數組名代表數組的起始地址,所以a(第一層)和第一個元素a[0][0]地址的數字是相同的,但是意義卻是不同的。對於該數組我們可以理解為:a的一維數組(第一層),它有四個元素a[0]、a[1]、a[2]、a[3](第二層),而每個元素又含有6個元素a[0][0],a[0][1],a[0][2],a[0][3],a[0][4],a[0][5](第三層),…到此我們終於訪問到了每個元素了,這個過程我們經歷了:a->a[0]->a[0][0];
整體來講:a是一個4行5列的二維數組,a表示它指向的數組的首地址(第一個元素地址&a[0]),同時a[0]指向一行,它是這個行的名字(和該行的第一個元素的首地址相同(第一個元素為地址&a[0][0]))。所以從數字角度說:a、a[0]、&a[0][0]是相同的,但是他們所處的層次是不同的。
既然a代表二維數組,那麼a+i就表示它的第i+1個元素*(a+i)的地址,而在二維數組中
*(a+i)又指向一個數組,*(a+i)+j表示這個數組的第j+1個元素的地址,所以要訪問這個元素可以使用 *(*(a+i)+j)(也就是a[i][j])。
他們的示意圖為(虛線代表不是實際存在的):
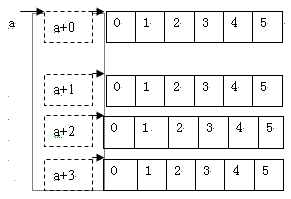
對照這個圖,如下的一些說法都是正確的(對於a[4][6]):
a是一個數組類型,*a指向一個數組;
a+i指向一個數組;
a、*a和&a[0][0]數值相同;
a[i]+j和*(a+i)+j是同一個概念;
總結一下就是:我們對於二維指針a,他指向數組a[0,1,2,3],使用*,可以使他降級到第二層次,這樣*a就指向了第一個真正的數組。對於其他的情況我們也可以采用相同的方式,對於其他維數和類型的數組我們可以采用相類似的思想。
說到指向數組的指針,我們還可以聲明一個指針變量讓它指向一個數組。例如:
int (*p)[5];
這時p就是一個指針,要指向一個含有5個int類型元素的數組,指向其他的就會出現問題。
這個時候我們可以使用上面的什麼東西來初始化呢?
我們可以使用*a,*(a+1),a[2]等。
原因很簡單:我們在一個二維的數組中,那麼表達方式有上面的相互類似的意義呢?只有 *a,*(a+1),a[2]等,
C)指針數組
一個指針數組是指一個數組中的每個元素都是一個指針,例如:
int *p[10];//而不能是int (*p)[10]
或者
char *p[10];
此時p是一個指針(數值上和&p[0]一樣);
在前面有int t[10];
int * pt=t;//使用pt指向t
那麼這裡我們用什麼指向int *t[10]中的t呢?我們要使用一個指針的指針:
int **pt=t;
這是因為:在int *t[10]中,每個元素是指針,那麼同時t又指向這個數組,數組上和&t[0]相同,也就是指向t[0],指向一個指針變量,可以說是一個指針的指針了,所以自然要用
int **pt;
D)指針的指針
一個指針變量內部可以存儲一個值,這個值是另外一個對象的地址,所以我們說一個指針變量可以指向一個普通變量,同樣這個指針變量也有一個地址,也就是說有一個東西可以指向這個指針變量,然後再通過這個指針變量指向這個對象。那麼如何來指向這個指針變量呢?由於指針變量本身已經是一個指針了(右值),那麼我們這裡就不能用一般的指針了,需要在指針上體現出來這些特點,我們需要定義指針的指針(二重指針)。
int *p1=&i;
int**p2=&p1;
綜合以上的所有點,下面是我們常常看到一些匹配(也是經常出錯的地方):
int a[3],b[2][3],c,*d[3];
void fun1(int *p);
void fun2(int (*p)[3]);
void fun3(int **p);
void fun4(int p[3]);
void fun5(int p[]);
void fun6(int p[2][3]);
void fun7(int (&p)[3]);
函數 不會產生編譯時刻的可能值(但邏輯上不一定都對)
函數 不會產生編譯時刻的可能值(但邏輯上不一定都對) fun1 a, &a[i], *b ,b[i],&b[i][j] ,&c ,d[i] fun2 b,b+i, fun3 d fun4 a, &a[i], *b ,b[i],&b[i][j] ,&c ,d[i] fun5 a, &a[i], *b ,b[i],&b[i][j] ,&c ,d[i] fun6 b fun7 a為什麼可以有這樣的搭配,原因如下:
對於fun1 fun4 fun 5: 在編譯器看來fun1,fun4,fun5的聲明是一樣,在編譯時候,編譯器把數組的大小捨去不考慮,只考慮它是一個指針,也就是說有沒有大小說明是一樣的,所以三者的形式都是fun1的形式(其實只要提供了int*指針就可以了);
對於fun7 :以上的解釋對於引用是不適用的,如果變量被聲明為數組的引用,那麼編譯器就要考慮數組的大小了,那麼必須和聲明一模一樣(所以fun7就只有a合適);
對於fun2:p是一個指向一個含有3個元素的數組,這樣b和b+i正好合適,而a卻不是(它是指向a[0]的,不是指向這個數組的);
對於fun3:p是一個指針的指針,而d指向d[0],同時d[0]又是一個指針,所以d就是一個指針的指針。但是b卻不是(它是一個2*3的矩陣也就是年int [2][3]類型);
對於fun6,p是一個2*3的數組類型,和b恰好完全匹配;
二、函數指針、函數的指針參數以及返回指針的函數
A) 函數指針
C++規定,一個函數的地址就是這個函數的名字。我們需要指出的就是一個指針需要指定類型是為了後來的指針解析時候使用,通過指針有效快速訪問對象。那麼對於函數的指針,它要表示出該函數的那些特性才能滿足解析的唯一性呢?答案就是一個函數的特性有它的參數列表和返回類型。
下面是一個函數指針的例子:
int (*p)(int I,int j);
不能是
int *p(int I,int j),
這樣就變成了返回指針的函數聲明了。
在C++中處於對安全性的考慮,指針和它指向的對象要類型一致,也就說上面的指針所指向的函數的特性要和它一模一樣:例如指向int min(int I,int j);是可以的。但是指向int min(double I ,double j);是不可以。函數指針也和其他的指針一樣,在使用的時候很怕發生"懸空",所以在使用的時候同樣要判斷有效性,或者在定義的時候就初始化。
int (*p)(int I,int j)=min;
int (*p)(int I,int j)=&min;
int (*p)(int I,int j)=0;
B) 函數的指針參數
函數指針可以作函數的參數:例如我們有一個積分的算法,對於不同的數學函數可以進行積分(我們這裡假設函數都是一元的);
那麼我們的算法接口可以定義為:
template<class T>
T integrate( T lower, T upper , T (*)(T)=0 )throw(integrated_exp);
這裡的最後的參數是一個函數的指針,並且被設定缺省值為0。這個函數返回一個值,同時需要一個參數。假如加入我們有這樣的一個函數:
double line(double x){ return a*x+b;}
那麼我就可以使用了。
函數指針還可以作為返回類型(注意不是函數!!,某個特定的函數是不可以作為返回類型的。)假設:
typedef int (*PF)(int );
PF getProcessMethod( );//true
C) 返回指針的函數
一個函數的返回是函數的重要接口之一,c++的一個重要的強大的功能就是能夠設計足夠復雜和好用的用戶自定義類型。而同時處理和傳遞這些類型也是很麻煩的一件事情,我們不想把我們的時間都花在這些對於我們的實際工作沒有很實質幫助的拷貝上,解決這個問題就要依賴我們的接口設計:c和c++都提供了相應的解決方案,在c++中我們可是使用引用,講他們作為函數的實際參數,或者我們在函數的實際參數中使用一個指針等。同樣我們還可以使用一個函數返回一個指針:但是這是一個很不好解決的問題!
我們首先容易出錯的是:將一個局部變量的地址傳出來!例如:
UserType * Process( )
{
UserType ut(param-list);
//process ut;
return &ut;//
}
這個變量在我們的函數結束的時候就被銷毀了,盡管地址可以傳出去,但是這個地址已經不存在了,已經不能使用的東西,在這個函數之外卻不知道,難免要出錯!
同時我還會有一個比較麻煩的問題:使用new,又容易造成內存洩露
UserType * Process ( )
{
UserTpye *put=new UserType(param-list );
//process put;
return put;
}
我們在函數內部使用了一個new,分配了一個空間,這樣傳出來也是可以!
就是說不會發生上面的問題了。但是用戶通常都會忘記在程序的外面在把這個借來的空間還回去!內存空間就這樣洩露了!
可能也是這些另人無奈的問題,所以很多程序員把函數的參數設定為指針或者引用,以此來代替這種向外傳輸吧!總之,使用這種返回指針的函數要小心!
三、類成員的指針
類成員和一般的外部變量相互比較,不同就是它所在的域不同,這個域很重要,它決定了該變量可以使用的范圍。那麼一個指針如果要指向類的成員函數或者成員變量,那麼除了要表達它的返回類型、參數列表或者類型之外,那麼還要說明它所指向的變量(或者函數)的域,為了說明該域我們要使用類域限定:
class NJUPT
{
static double money=20000000;
int num;
public:
NJUPT():num(10){};
int get(){return num;};
double getMoney(){reuturn money;}
}
我們定義成員的指針為
int NJUPT:: *p;//指向int型成員變量
int (NJUPt::*)p()//指向int f()型成員函數。
為了使用這些指針,我們需要使用該類型的變量或者指針。
NJUPT s,*ps;
那麼調用的方式為:
cout<<s.*p;
cout<<(s->*p)();
這個看起來似乎很奇怪!但是只要你想到我們定義的指針被限定在了類域中了(我們在開始定義的使用使用了NJUPT:: ),這麼使用也是很自然的。
如果一個類還有一些靜態成員變量和靜態成員函數,那麼我是否也想這樣使用呢?
答案是不用,靜態成員我們就可以象使用外部的普通成員一樣定義一個指針或者函數指針來訪問就可以了,究其原因主要是這個成員的類型性質決定的。
double *p=&NJUPT::money;
double (*p)()=&NJUPT::getMoney():