摘要 應用程序性能不僅僅與速度有關。在 Web 服務器環境中,卓越的性能還意味著確保可以並發地為最大數量的用戶服務。這可以通過高效地使用多處理器計算機和線程管理來達到。本文介紹了可以解決許多並發性問題的技術。一種方法是使用線程管理,在線程基礎上控制對數據庫的訪問 — 這可以保護數據的完整性。在本文中,生成並提供了可重用的線程類。然後,對這些類進行了測試,並在實際環境中分析了它們的性能。
服務器應用程序的成功與否遲早將歸結為性能。但是,服務器應用程序中的性能不完全等同於純粹的速度。您還必須考慮並發性 — 即您能夠同時為多少個客戶端提供服務。實際上,對於服務器而言,並發性通常要比純速度更為重要,尤其是對帶有許多 CPU 的高端硬件而言。具有低並發性的服務器應用程序只是無法利用多個 CPU(無論該應用程序有多麼快)。
我不知道是否有簡單明了的用於優化並發性的處方,但多年以來,我已經形成了大量能夠提供巨大幫助的竅門。其中一個竅門可以很好地同步對大型集合中的對象的訪問,而不會犧牲並發性。本文將演示我的技巧。首先,我將說明一個小型多線程示例程序,該程序演示了並發訪問大型集合中的對象的需要。然後,我將開發一個能夠解決該問題的可重用類,並且將比較得到的性能數值。作為一項附加的好處,該示例程序將包含一組便於使用的、用於創建和同步線程的類(當然是可重用的)。
示例代碼可在 Windows 98 Second Edition、帶有 Service Pack 6a 的 Windows NT 或帶有 Service Pack 1 的 Windows 2000 上運行(它或許可以在其他版本上運行,但以上版本是我測試過的全部版本。)而且,該代碼要求有帶有 Service Pack 4 的 Visual C++ 6.0。
請注意,我使用了與 Windows 編程界規范稍微不同的編碼風格。具體說來,我使用標識符前綴 k_ 表示常數和枚舉,使用 g_ 表示全局變量、靜態全局變量以及靜態類成員,使用 m_ 表示類成員。
構造塊
Figure 1 Exception Class
class Exception
{
public:
enum ErrId
{
// Keep these in the same order as the string table:
k_critSecInitFailure,
k_threadCreationFailure,
k_threadResumeFailure,
k_threadWaitFailure
};
Exception(ErrId errId, unsigned long osErrId = NOERROR) :
m_errId(errId), m_osErrId(osErrId) {}
~Exception()
{}
UINT getErrId() const
{ return m_errId; }
unsigned long getOsErrId() const
{ return m_osErrId; }
string getErrorMsg() const;
private:
static string getOSMsg(unsigned long osErrId);
static const char*const k_messages[];
UINT m_errId;
unsigned long m_osErrId;
};
代碼1
在分析該示例程序的實質內容之前,我將討論它包含的一些構造塊。第一個構造塊是 Exception 類(參見代碼1),它主要用於將 Win32 API 錯誤轉換為 C++ 異常。對於該類實在沒有太多好說的,所以我不會向您一一介紹它的所有細節。(如果您感興趣,請通過本文頂部的鏈接下載完整的示例源代碼。)Exception 的一項有趣的功能是:getErrorMsg 方法使用 Win32 API FormatMessage 獲取與 Win32 錯誤代碼對應的文本錯誤說明。這使得跟蹤 Win32 API 錯誤變得更為快速。例如,與只是看到錯誤代碼 120 不同,它將告訴您“This function is not supported on this system”(該系統不支持這一功能)。
Figure 2 Timer Class
class Timer
{
public:
Timer() : m_stop(0), m_start(0)
{
GetSystemTimeAsFileTime(
reinterpret_cast<FILETIME*>(&m_start));
}
void stop()
{
GetSystemTimeAsFileTime(
reinterpret_cast<FILETIME*>(&m_stop));
}
double getMicroSec() const
{ return diffAsDouble() / 10.0; }
double getMilliSec() const
{ return diffAsDouble() / 10000.0; }
double getSec() const
{ return diffAsDouble() / 10000000.0; }
private:
double diffAsDouble() const
{ return static_cast<double>(m_stop - m_start); }
LONGLONG m_stop;
LONGLONG m_start;
};
圖 2
Timer 類(參見圖 2)用於對示例程序測試運行進行計時。它同樣是一個極為簡單的類,甚至比 Exception 還要簡單。它完全是內聯的,因此它只有一個頭文件。Timer 在其構造函數中調用 Win32 API GetSystemTimeAsFileTime 以獲取開始時間,然後再次在 stop 方法中調用它來獲取結束時間。getXxx 方法將二者之間的差值轉換為多種容易感知的單位。
Figure 3 CritSec Class
class CritSec
{
public:
CritSec();
~CritSec()
{ DeleteCriticalSection(&m_critSec); }
void acquire()
{ EnterCriticalSection(&m_critSec); }
bool tryAcquire() // use only on Windows NT or Windows 2000
{ return !!TryEnterCriticalSection(&m_critSec); }
void release()
{ LeaveCriticalSection(&m_critSec); }
private:
enum { k_spinCount = 3000ul };
CRITICAL_SECTION m_critSec;
};
template<class T>
class LockKeeper
{
public:
LockKeeper(T& t) : m_t(t) { m_t.acquire(); }
~LockKeeper() { m_t.release(); }
private:
T& m_t;
};
圖 3
CritSec 類包裝了一個臨界區(參見圖 3)。首先,有些人發現該類是如此簡單,以至於他們不相信它有用。然而,第一印象可能是靠不住的。該類之所以重要,有以下三個原因。首先,它使臨界區成為面向對象的,從而使其在 C++ 程序中看起來非常合適。這是非常有用的,因為現代 C++ 使用與 C 極為不同的編程風格,因此直接使用 C 函數會強迫程序員頻繁改變編程風格,從而導致代碼難於閱讀和維護。關於這一點,沒有比圍繞線程同步對象進行的錯誤處理更為明顯的了。CritSec 將 Win32 API 錯誤轉換為異常(使用 Exception 類),從而產生了干淨得多的代碼。
其次,CritSec(與不久將討論的 LockKeeper 結合)使臨界區具有異常安全性。換句話說,您必須確保在引發異常後,沒有任何臨界區處於鎖定狀態。這對於在從錯誤狀態中恢復時避免死鎖是非常重要的。
第三,通過在類中包裝臨界區,您可以使其獨立於平台。跨平台的實現超出了本文的范圍,但是可以用 Unix 上的 POSIX 線程 API 實現這一相同的 CritSec 類接口。
LockKeeper 模板類(同樣參見圖 3)與 CritSec 結合使用。我通常不是直接調用 acquire 和 release 方法,而是在堆棧上實例化一個 LockKeeper 實例。構造函數為我調用 acquire 方法,而當 LockKeeper 離開作用域時,析構函數將自動調用 release 方法。這可以消除一個代碼行,但更為重要的是,它確保了在鎖被占有時引發的異常能夠在該異常傳播到 LockKeeper 實例的作用域以外時,自動釋放該鎖。
注意,因為 LockKeeper 是一個模板,所以可以在任何其 acquire 和 release 方法不帶參數的類上使用它。這非常方便,因為在真正的多線程應用程序中,將會有許多個這樣的類 — Mutex、Semaphore 以及其他類(您不久就將看到)。
Figure 4 Thread Class Definition
class Thread
{
public:
Thread();
virtual ~Thread();
virtual void start();
virtual bool wait(unsigned long timeout = INFINITE);
unsigned long getId() const
{ return m_id; }
HANDLE getHandle() const
{ return m_h; }
protected:
virtual void run() = 0;
private:
static unsigned __stdcall entryPoint(void* pArg);
unsigned long m_id;
HANDLE m_h;
};
圖 4
與前面的構造塊類不同,要向您解釋清楚 Thread 類有一點兒困難(參見圖 4)。對於那些了解 Java 的讀者而言,它非常像 Java Thread 類,不同之處在於它不支持單獨的 Run 接口 — 它要求直接從 Thread 派生。
對於那些不熟悉 Java 的線程機制的讀者而言,以下是您使用 Thread 類的方法。首先,從 Thread 派生一個類(假設為 MyThread),然後重寫純虛擬方法 run。在該方法中放入您希望新線程執行的代碼。然後,構建一個 MyThread 類型的對象,並調用 start。此時,新的線程將開始在您的 run 方法中執行。如果您希望另一個線程等待至 MyThread 線程退出,請調用 wait。(當然,您絕不能從 run 方法內部調用 wait 方法。)
以這種方式對線程進行建模的優點之一是:它使得與線程的通訊變得容易多了。要將信息傳遞給線程,您需要做的全部事情就是將這些信息存儲在您的 MyThread 類的數據成員中。我通常在構造函數中完成這一工作。要向您的線程外部傳遞信息,只須完成相反的工作 — 在您的 run 方法中,將信息存儲在您的 MyThread 類的數據成員中,然後實現 getter 方法以使其他線程可以獲取該數據。
很重要的一點是您的線程類的任何數據成員都是私有的,並帶有用於訪問它們的 getter 和/或 setter 方法。這是因為將很可能從多個線程中訪問這些數據成員,因此您需要使用封裝所提供的控制來保證正確的線程同步。
Figure 5 Thread Implementation
Thread::Thread() : m_id(0), m_h(0)
{
}
Thread::~Thread()
{
if (m_h != 0)
{
wait();
CloseHandle(m_h);
m_id = 0;
m_h = 0;
}
}
void Thread::start()
{
if (m_h != 0)
{
wait();
CloseHandle(m_h);
m_id = 0;
m_h = 0;
}
unsigned id;
unsigned long h = _beginthreadex(0, 0, entryPoint, this,
CREATE_SUSPENDED, &id);
if (h == 0)
{
throw Exception(Exception::k_threadCreationFailure);
}
m_id = id;
m_h = reinterpret_cast<HANDLE>(h);
if (ResumeThread(m_h) == static_cast<DWORD>(-1))
{
throw Exception(Exception::k_threadResumeFailure, GetLastError());
}
}
unsigned __stdcall Thread::entryPoint(void* pArg)
{
try
{
Thread* pThis = static_cast<Thread*>(pArg);
pThis->run();
}
catch (const Exception& e)
{
cout << "Thread " << e.getErrorMsg() << endl << endl;
}
catch (const exception& e)
{
cout << "std::exception in thread: " << e.what() << endl << endl;
}
return 0;
}
bool Thread::wait(unsigned long timeout)
{
bool result = true;
if (m_h != 0)
{
switch (WaitForSingleObject(m_h, timeout))
{
case WAIT_OBJECT_0:
break;
case WAIT_TIMEOUT:
result = false;
break;
default:
throw Exception(Exception::k_threadWaitFailure,
GetLastError());
break;
}
}
return result;
}
圖 5
Thread 類的實現有幾個難點(參見圖 5)。首先,請觀察私有和靜態 entryPoint 方法:
static unsigned __stdcall entryPoint(void* pArg);
該方法是傳遞給 _beginthreadex API 以啟動線程運行的函數。您不能傳遞一個非靜態方法(如 run),因為非靜態方法的調用約定與 _beginthreadex 預期的調用約定不同。(它不知道如何傳遞該指針。)但是,被聲明為 __stdcall 的靜態方法將完全適用。對 _beginthreadex API(它位於 start 方法中)的調用會傳遞一個指向 entryPoint 方法的指針和 this 指針。當新的線程開始在 entryPoint 中執行時,pArg 參數將是傳遞給 _beginthreadex 的 this 指針。然後,entryPoint 方法將它轉換為 Thread* 並調用 run。虛擬方法的魔力將接管工作,並將執行傳遞給您的 MyThread::run 方法。
entryPoint 方法還具有另外一個用途。它為最可能的異常類型提供最後的異常處理程序。這可以確保您在某個環節恰好出錯時,能夠獲得有用的錯誤消息。
Thread 類的另外一個微妙的方面值得提一下。在 start 方法中,您將注意到線程是在掛起狀態中創建的,然後線程 ID 和句柄被賦給類成員。最後,線程被恢復執行。這一掛起是必要的,可防止出現競爭情形。假設新線程是在運行狀態中創建的。如果新線程在 run 方法中比較早地調用了 getId 或 getHandle,則它可能在 start 方法已經進行賦值之前訪問這些成員。
示例服務器程序
有關示例程序的預備知識已經足夠了。既提供一個實際的服務器應用程序示例,同時又要使其足夠簡單以便在一篇短文中加以介紹,這是很困難的,因此此處顯示的示例有一點兒人為的痕跡。實際上,它根本不是一個真正的服務器應用程序。但是,我已經嘗試虛構了一個可信的服務器應用程序方案,以便您能夠參照實際方案來觀察該應用程序,而無須運用太多的想象力。
Figure 6 Database Class
class Database
{
public:
Database(unsigned long numEntries);
unsigned long getNumEntries() const
{ return m_entries.size(); }
DBEntry& getEntry(unsigned long entryId) const
{ return *m_entries.at(entryId).get(); }
private:
typedef vector<auto_ptr<DBEntry> > DBEntryList;
typedef DBEntryList::const_iterator DBEntryIter;
DBEntryList m_entries;
};
class DBEntry
{
public:
DBEntry(unsigned long id, const string& value) :
m_id(id), m_value(value) {}
unsigned long getId() const
{ return m_id; }
const char* getValue() const
{ return m_value.c_str(); } // use of c_str causes cloning
void setValue(const string& newValue)
{ m_value = newValue.c_str(); } // use of c_str causes cloning
static void critSecMode(bool useSingleCritSec)
{ g_useSingleCritSec = useSingleCritSec; }
void acquire();
void release();
private:
unsigned long m_id;
string m_value;
static bool g_useSingleCritSec;
static CritSec g_singleCritSec;
static CritSecTable g_critSecTable;
};
示例 ConcurrencyDemo(或簡稱為 CD)模擬了簡單的內存中數據庫。DBEntry 類(參見圖 6)代表該數據庫中的一個項,由一個數值鍵和一些文本組成。客戶端可以讀取與給定鍵關聯的文本,也可以更新特定鍵的文本。對象個數在啟動時確定。
CD 示例包含一個輔助線程池。在實際情況下,這些線程將通過某種遠程調用機制(如 TCP、DCOM、IIOP 或 SOAP — 如果您恰好正在使用尖端技術的話)獲得來自客戶端的請求。在該示例中,請求的生成經過了模擬,而不是真實的。
CD 示例采用了以下命令行參數:數據庫中的項數、要執行的測試迭代的次數以及要使用的輔助線程的數目。如果指定了多個線程數目,則該程序將用每個數目運行一次測試。
Figure 7 main
typedef vector<unsigned long> NumberList;
typedef NumberList::const_iterator NumberIter;
int main(int argc, char* argv[])
{
try
{
// Interpret command-line arguments:
unsigned long numEntries;
unsigned long numIterations;
NumberList numThreadsList;
interpretCommandLine(argc, argv, numEntries, numIterations,
numThreadsList);
// Initialize the in-memory database:
Database db(numEntries);
// Print output header:
cout <<
"
"
"# of DB entries:," << numEntries << "
"
"# of iterations:," << numIterations << "
"
"All times in milli-seconds
"
"
"
"# Threads,Time (Single CritSec),Time (CritSec Table)"
<< flush;
// Run a test for each number of threads:
for (NumberIter i = numThreadsList.begin();
i != numThreadsList.end(); i++)
{
cout << '
' << *i;
DBEntry::critSecMode(true); // single critical section
doTest(db, numIterations, *i);
DBEntry::critSecMode(false); // critical section table
doTest(db, numIterations, *i);
}
cout << endl << endl;
}
catch (const Exception& e)
{
cout << e.getErrorMsg() << endl << endl;
}
catch (const exception& e)
{
cout << "std::exception: " << e.what() << endl << endl;
}
return 0;
}
當 CD 啟動時,它將首先解釋其命令行參數,然後創建數據庫(參見圖 7)。接下來,CD 將打印輸出標題。(如果它在您看來不像是合法的 C++,則您尚未學習有關便利的 C 預處理器功能的內容。該預處理器將所有僅由空格分隔的字符串文字連接在一起。)最後,CD 針對命令行上指定的每個線程數目調用 doTest 兩次。第一次測試以最明顯的方式同步對數據庫的訪問。第二次使用我的經過優化的技巧。為了確保得到有用的錯誤消息,主函數還會捕獲最可能的異常類型。
Figure 8 doTest
typedef vector<auto_ptr<WorkerThread> > ThreadList;
typedef ThreadList::const_iterator ThreadIter;
static void doTest(Database& db, unsigned long numIterations,
unsigned long numThreads)
{
// Set up thread pool:
ThreadList threads;
threads.reserve(numThreads);
for (unsigned i = 0; i < numThreads; i++)
{
WorkerThread* pThread = new WorkerThread(i, numThreads,
numIterations, db);
threads.push_back(auto_ptr<WorkerThread>(pThread));
}
Timer timer;
// Start threads running:
for (ThreadIter j = threads.begin(); j != threads.end(); j++)
{
(*j)->start();
}
// Wait on threads:
for (ThreadIter k = threads.begin(); k != threads.end(); k++)
{
(*k)->wait();
}
timer.stop();
cout << ',' << timer.getMilliSec() << flush;
}
圖 8
圖 8 顯示了 doTest 函數。該函數開始時創建了一個線程池,它是指向 WorkerThread 對象的指針的向量。實際上,更准確地說,它是 auto_ptr 對象的向量,以便在銷毀該數組時,還將刪除所有 WorkerThread 對象。在下一部分中,我將詳細討論 WorkerThread 類。
接下來,doTest 創建一個計時器來對測試進行計時,啟動每個線程運行,並且等待各個線程以確保它們全部完成該測試。最後,DoTest 停止計時器並打印結果。請注意,輸出格式有一點兒奇怪。它采用逗號分隔值 (CSV) 格式。這樣,我可以將輸出重定向到具有 .csv 文件擴展名的文件中,並將其直接導入 Microsoft Excel。這可以快速而輕松地創建漂亮的圖表。
Figure 9 WorkerThread Class Declaration
class WorkerThread : public Thread
{
public:
WorkerThread(unsigned long threadNum, unsigned long numThreads,
unsigned long numIters, Database& db);
virtual ~WorkerThread();
protected:
virtual void run();
private:
enum RequestType { k_read, k_update };
void getRequest(unsigned long& entryId, RequestType& requestType,
string& newValue);
void doUpdate(unsigned long entryId, const string& newValue);
string doRead(unsigned long entryId);
static void simulateWork(unsigned long iterations);
enum
{
k_randMax = 1771875ul,
k_randCoeff = 2416ul,
k_randOffset = 374441ul
};
unsigned long rand(unsigned long hi);
unsigned long m_randSeed;
unsigned long m_threadNum;
unsigned long m_numThreads;
unsigned long m_numIters;
Database& m_db;
};
Figure 10 WorkerThread Class Implementation
WorkerThread::WorkerThread(unsigned long threadNum,
unsigned long numThreads, unsigned long numIters, Database& db) :
m_randSeed(threadNum % k_randMax),
m_threadNum(threadNum),
m_numThreads(numThreads),
m_numIters(numIters),
m_db(db)
{
}
WorkerThread::~WorkerThread()
{
}
void WorkerThread::run()
{
// The strange starting point and step size in this loop make sure
// that there are the correct total number of iterations among all
// the threads, even if m_numIters is not evenly divisible by
// m_numThreads.
for (unsigned long i = m_threadNum; i < m_numIters;
i += m_numThreads)
{
// Get a request:
unsigned long entryId;
RequestType requestType;
string value;
getRequest(entryId, requestType, value);
// Process the request:
if (requestType == k_update)
{
doUpdate(entryId, value);
}
else
{
value = doRead(entryId);
}
// In a real-world server, the result would be marshaled back
// to the client here.
}
}
void WorkerThread::getRequest(unsigned long& entryId,
RequestType& requestType, string& newValue)
{
const unsigned long k_numReadsPerUpdate = 5;
entryId = rand(m_db.getNumEntries() - 1);
requestType = (rand(k_numReadsPerUpdate) == 0)
? k_update
: k_read;
if (requestType == k_update)
{
newValue = "new value";
}
}
void WorkerThread::doUpdate(unsigned long entryId, const string& newValue)
{
// Update the database:
DBEntry& entry = m_db.getEntry(entryId);
LockKeeper<DBEntry> keeper(entry);
entry.setValue(newValue);
// Simulate update overhead:
simulateWork(100);
// Unlock entry as we return from this method
}
string WorkerThread::doRead(unsigned long entryId)
{
// Read from the database:
DBEntry& entry = m_db.getEntry(entryId);
LockKeeper<DBEntry> keeper(entry);
string readResult = entry.getValue();
// Simulate read overhead:
simulateWork(10);
return readResult;
// Unlock entry as we pass out of this scope
}
static double g_dummy = 0; // prevents optimizing simulateWork away
void WorkerThread::simulateWork(unsigned long iterations)
{
for (unsigned long i = 0; i < iterations; i++)
{
// Meaningless work to take up time:
unsigned long x = i % 37;
g_dummy = cos(x) + sin(x) + cosh(x) + sinh(x);
}
}
// This is a very simple pseudo-random number generator, which overcomes
// two limitations of the built-in rand() function:
// * Its maximum is considerably higher, and
// * It doesn't serialize calling threads.
// Derived from "Numerical Recipes in C", by Press, Flannery, Teukolsky,
// and Vetterling, ©1988 by Cambridge University Press, pp.209-211.
unsigned long WorkerThread::rand(unsigned long hi)
{
assert(hi < k_randMax);
m_randSeed = (m_randSeed * k_randCoeff + k_randOffset) % k_randMax;
return (hi * m_randSeed) / (k_randMax - 1);
}
WorkerThread 類
WorkerThread 類(參見圖 9 和圖 10)顯然派生自 Thread。構造函數獲得一串輸入參數,並且只是將其存儲到數據成員中以便供以後使用。run 方法使用其中前三個參數來控制循環。這在開始時可能看起來有點奇怪,但其意義在於盡可能均勻地將迭代總次數分配到所有線程中,即使迭代次數並不能由線程個數整除。如果發生這種情況,則某些線程將比其他線程多迭代一次。
在每次迭代中,run 方法都會調用 getRequest 以獲取下一個請求的參數。在實際程序中,getRequest 將通過某種網絡傳輸機制來從客戶端獲取輸入。為使討論簡單化,我編寫了 getRequest 以生成隨機請求。為了防止這一方法使結果失真,我不得不使用我自己的隨機數生成器。這是因為編譯器的隨機數生成器使用全局種子,因此需要一個臨界區。這會引入額外的線程同步,從而掩蓋我試圖觀察的結果。我的隨機數生成器使用線程本地種子(存儲在 WorkerThread 類中),因此不需要同步。
根據請求類型的不同,run 方法隨後會調用 doUpdate 或 doRead。這些方法中的每個方法都會獲取一個對所指示的數據庫項的引用,鎖定該引用,執行請求的操作,然後返回。請注意,使用了 LockKeeper 對象來直接鎖定數據庫項。這是一個示例,說明了如何使用 LockKeeper 模板來鎖定任何具有不帶任何參數的 acquire 和 release 方法的對象。稍後,我將詳細討論 DBEntry 類上的 acquire 和 release 方法。
還請注意,doUpdate 和 doRead 方法調用了 simulateWork 方法。在實際的服務器中,更新和讀取(尤其是更新)會引起一些開銷。為了使 doUpdate 和 doRead 占用足夠的執行時間來顯示期望的結果,我需要添加對 simulateWork 的調用。在我用作基准測試的計算機上,這會使 doRead 和 doUpdate 的執行時間分別增加大約 20 和 200 微秒。(這裡需要稱贊一下 Visual C++ 優化器:我必須向 simulateWork 添加一個全局訪問,以防止該方法以及對它的調用被完全優化掉。)
在 doRead 和 doUpdate 中有一個難以發現的微妙之處。如果您大體考察一下 CD 代碼,您會發現每當將字符串作為 in 參數傳遞給方法時,該參數的類型都是 const 字符串引用,而每當從方法中返回字符串時,返回類型都是字符串。然而,DBEntry 上的 setValue 和 getValue 方法卻獲取並返回 const char*。您可能認為這只是我在 C++ 標准庫出現之前的多年 C 和 C++ 編碼經驗所遺留下來的習慣,但這完全是有意的。兩個字符串對象可以包含對同一字符串數組的引用,以便優化內存使用率,減少復制字符串所花的時間。如果 setValue 獲取 const 字符串引用並將其賦給 m_value 成員,則該成員將僅包含對傳入的字符串的引用。這可能導致兩個線程同時訪問同一字符串數組。因為字符串類未經過同步,所以這可能導致堆損壞。我的解決方案是改為傳遞(或返回)const char*。這會在鎖被 DBEntry 對象占有時強制進行字符串復制。進行復制之後,其他線程就可以接觸 DBEntry 而不會造成損害。
問題和可能的解決方案
既然您已基本了解該示例程序所做的工作,那麼讓我們考察一下下面的問題:如何同步對數據庫項的訪問?您不能允許輔助線程雜亂無章地獲取和設置數據庫項,因為產生的競爭情形在最好的情況下會導致不正確的結果,在最壞的情況下會導致服務器崩潰。
最簡單且最明顯的解決方案是使用單個臨界區。任何要讀取或更新某個項的線程都必須首先獲取臨界區。在許多情況下,這是最適當的解決方案。然而,請注意它會過分地同步線程。兩個正在訪問不同項的線程根本無須進行同步,但使用單個臨界區卻無論如何都會將它們同步。如果多個線程經常需要同時訪問不同的項,則這將在您的服務器中導致瓶頸,並且限制它的並發性。
另一種解決方案是在 DBEntry 本身內部嵌入一個臨界區。該解決方案具有兩個討厭的問題。首先,它會消耗數量驚人的系統資源。每個臨界區都使用 24 字節的內存以及一個事件內核對象。因此,如果您的數據庫中含有 1,000,000 個項,則該方法將消耗 24MB 內存和 1,000,000 個事件,而這一切僅僅是為了進行同步!這將不會受到您的客戶的歡迎。
該方法的另一個問題是您無法使用它來同步項的刪除。(這在該示例中不是一個問題,但在實際情況中通常是一個問題。)要刪除某個項,您需要鎖定它,然後刪除它。然後,另一個正在等待讀取該對象的線程將獲取駐留在已刪除的內存中的臨界區。這一點絕對不會受到客戶的歡迎。
Figure 11 CritSecTable Class Definition
class CritSecTable
{
public:
CritSecTable()
{}
~CritSecTable()
{}
void acquire(void* p)
{ m_table[hash(p)].acquire(); }
bool tryAcquire(void* p) // use only on Windows NT or Windows 2000
{ return m_table[hash(p)].tryAcquire(); }
void release(void* p)
{ m_table[hash(p)].release(); }
private:
static unsigned char hash(void* p);
CritSec m_table[256];
};
Figure 12 CritSecTable Class Implementation
unsigned char CritSecTable::hash(void* p)
{
unsigned char result;
if (sizeof(void*) == 8)
{
assert(sizeof(unsigned long) == 4);
assert(sizeof(unsigned short) == 2);
unsigned long temp1 = ((unsigned long*) (&p))[0]
^ ((unsigned long*) (&p))[1];
unsigned short temp2 = ((unsigned short*) (&temp1))[0]
^ ((unsigned short*) (&temp1))[1];
result = ((unsigned char*) (&temp2))[0]
^ ((unsigned char*) (&temp2))[1];
}
else if (sizeof(void*) == 4)
{
assert(sizeof(unsigned short) == 2);
unsigned short temp = ((unsigned short*) (&p))[0]
^ ((unsigned short*) (&p))[1];
result = ((unsigned char*) (&temp))[0]
^ ((unsigned char*) (&temp))[1];
}
else
{
result = ((unsigned char*) (&p))[0];
for (unsigned i = 1; i < sizeof(void*); i++)
{
result ^= ((unsigned char*) (&p))[i];
}
}
return result;
}
我的針對這一問題的解決方案是封裝在 CritSecTable 類中(參見圖 11 和圖 12)。該類的接口看起來幾乎與 CritSec 的接口完全相同,不同之處在於 acquire 和 release 方法采用 void* 參數。
Figure 13 DBEntry Class
bool DBEntry::g_useSingleCritSec = true;
CritSec DBEntry::g_singleCritSec;
CritSecTable DBEntry::g_critSecTable;
void DBEntry::acquire()
{
if (g_useSingleCritSec)
{
g_singleCritSec.acquire();
}
else
{
g_critSecTable.acquire(this);
}
}
void DBEntry::release()
{
if (g_useSingleCritSec)
{
g_singleCritSec.release();
}
else
{
g_critSecTable.release(this);
}
}
要使用該類,需要將一個 CritSecTable 實例與您希望對其進行並發訪問的大型集合(在這種情況下,即內存中的數據庫)相關聯。當您希望鎖定或取消鎖定某個項時,需要分別在 CritSecTable 對象上調用 acquire 或 release,並將該項的地址作為 void* 參數進行傳遞。有關示例,請參見 DBEntry 類的 acquire 和 release 方法的實現(如圖 13 所示)。(我已經實現了這些方法,以便它們可以為整個數據庫使用單個臨界區,或者使用一個 CritSecTable,具體取決於全局標志 g_useSingleCritSec 的設置。)
CritSecTable 在內部維護了一個 CritSec 實例數組(在我的實現中,包含 256 個實例)。當您調用 acquire 或 release 時,它將根據該 void* 參數計算一個哈希,然後使用該哈希對數組進行索引,並在相應的 CritSec 對象上調用 acquire 或 release。這意味著對於任何給定的數據庫項,您都將始終使用同一個 CritSec 對象,從而保證您能夠保持正確的同步行為。
如果兩個線程試圖同時鎖定不同的項,則其中一個線程阻塞另一個線程的可能性非常低(二百五十六分之一的可能性)。當然,隨著試圖對數據庫進行並發訪問的線程數的增加,其中一個或多個線程被阻塞的可能性也將增加。然而,在 Windows 中這通常不是一個問題。運行 Windows 的計算機很少具有八個以上的 CPU,並且(據我所知)上限是 32 個。如果您的服務器應用程序正在使用 I/O 完成端口(正像它應該做的那樣),則在任意給定時間,您的服務器中正在運行的線程數目將接近於 CPU 的數目。(注:有關 I/O 完成端口的討論超出了本文的范圍,但最近幾年來 MSDN Magazine 中出現過幾篇有關該主題的好文章。
我選擇使 CritSec 數組的長度為 256,因為它有利於使用一個非常簡單但有效的哈希函數。在此情況下,該哈希函數只是簡單地對 void* 的字節進行 XOR 運算,從而得到單個無符號 char。我已經花費了一些時間,針對 void* 的長度為四個字節、八個字節的情況以及一般性情況(針對您恰好在具有 7 字節指針的系統上運行 Windows 的情形)優化該哈希函數。在 32 位 Intel 系統上,Visual C++ 編譯器將哈希方法的 32 行 C++ 代碼簡化為只有六條匯編語言指令。
如果您的應用程序將具有數量大得多的線程試圖同時鎖定不同的項,則您可能需要更大的 CritSec 數組,但您將需要更為復雜的哈希函數來對其進行哈希運算。
並發性結果
我在具有一個 CPU 的 500 MHz Pentium III 計算機上以及具有四個 CPU 的 550 MHz Pentium III Xeon 計算機上運行了 CD 示例。在每種情況下,我都使用不斷增加的輔助線程數目運行了兩個測試(一個使用單個臨界區,另一個使用 CritSecTable)。圖 14 顯示了在單 CPU 計算機上使用一到八個輔助線程運行測試的結果。
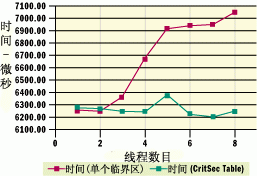
圖 14 單 CPU 計算機上的結果
使用單個臨界區時,隨著線程數目的增加,用於執行固定次數迭代的時間顯著增加。這是因為單個臨界區使得線程過於頻繁地進行上下文切換,並且 CPU 花費過多的時間在內核模式下執行上下文切換代碼。
您可以在 Windows NT 或 Windows 2000 上通過 Performance Monitor 應用程序證實這一點。在 Windows NT 上,您可以在 Start | Programs | Administrative Tools 下找到它。從 Edit 菜單中選擇 Add to Chart,將性能對象設置為 System,然後將以下三個跟蹤標志添加到您的圖表中:% Total Processor Time、% Total Privileged Time 和 Context Switches/sec。在 Windows 2000 上,概念是一樣的,但 Redmondtonians(指 Microsoft)已經改變了組件的位置。Performance Monitor 位於 Control Panel 中的 Administrative Tools 下面。單擊工具欄上的大加號,將性能對象設置為 Processor,再添加跟蹤標志 % Processor Time 和 % Privileged Time。然後,將性能對象設置為 System 並添加 Context Switches/sec。
當您運行 ConcurrencyDemo 時,您將看到在使用大量輔助線程的單個臨界區測試期間,特權時間量和上下文切換的次數都大大增加了。與此相反,使用臨界區表的測試將執行少得多的上下文切換,從而得到相當穩定的執行時間,如圖 14 所示。
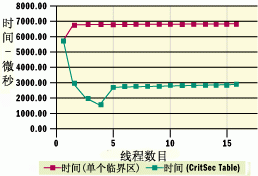
圖 15 多 CPU 計算機上的結果
四 CPU 計算機上的結果更加令人吃驚(參見圖 15)。使用單個臨界區時的趨勢在最初因為線程數從一個增加為兩個而增加以後,變得相當穩定。請注意此處與單 CPU 計算機上的單個臨界區情形完全不同的行為。四 CPU 計算機無須疲於應付上下文切換的原因在於,在多 CPU 計算機上,臨界區具有一個“旋轉計數”。這意味著當一個線程試圖獲取已經鎖定的臨界區時,該線程將在循環中“旋轉”一會兒,檢查該鎖是否已被釋放,然後進入休眠狀態。這是有利的,因為休眠會導致上下文切換,其代價要比浪費在旋轉上的周期更大。
使用臨界區表時,隨著您使用的線程數從一個增加到四個,執行時間會急劇下降(70% 以上)。這表明全部四個 CPU 正在並行工作,以獲得最佳的並發性。(實際上,理論上的最佳並發性將顯示執行時間下降 75%,但完全按線性比例下降是很罕見的。)請注意,隨著您使用的線程數超過四個,性能將會因為上下文切換更為頻繁而下降。這表明了使用 I/O 完成端口以使正在運行的線程數非常接近 CPU 個數的重要性。
小結
本文介紹的用於提高並發性的技術具有許多應用。我首先在一個服務器應用程序上設計了這一技術,該應用程序使用 C++ 智能指針並通過引用計數對象實現了垃圾回收。我用臨界區表保護了該引用計數。(您可能認為我可以使用 InterlockedXxx 系列函數達到這一目的,但是將引用計數遞減到零以及刪除該對象的操作必須是需要臨界區的原子操作。)
還可以使用臨界區表來克服 CD 示例中數據庫的一個主要局限,即無法以線程安全且具有高度並發性的方式在該數據庫中添加或刪除項。創建具有高度並發性的集合是一項艱難的任務,並且超出了本文的范圍,但在我已經發現的問題的一個解決方案中,臨界區表是一個重要的組件。
我希望您將在自己的服務器應用程序中找到這一技術的用武之地。如果您確實這樣做了,那麼我非常願意了解相關情況。
本文配套源碼