開始我們做個實驗,先打開兩個文檔附帶的程序,一個工程是MD5C,一個工程是MD5ASM,其中MD5C是從VCKBASE下載的md5算法的標准C語言原代碼,MD5ASM是我修改後的md5算法原代碼。我給這兩個工程的main函數裡面都添加了一段回朔代碼,用來產生0~99999999的數字,然後用這兩個工程裡面的可執行文件去對每個數字md5加密。好了,經過一段時間的等待後,就可以看到類似的結果了:
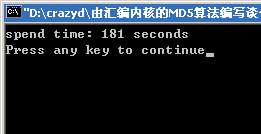
MD5ASM工程在我的機器上的結果是181秒,MD5C在我的機器上產生的結果是999秒,呵呵,數字有點怪,不過我看了表的,差不多是這個時間,巨大的差距是怎樣產生的,讓我們接下來往下看吧。
在開始正題之前,大家需要清楚一件事,就是MD5C裡面的代碼雖然效率不高,但絕對是優秀的,因為它主要在演示md5的算法,用的是純粹的C,沒有添加任何平台相干的代碼,而我改寫的MD5ASM是只能夠運行於x86上的windows系統中。所以速度是以兼容性來交換的。
一、算法優化
先觀察一下MD5C裡面的一段代碼:
static void Encode (unsigned char *output, unsigned int *input, unsigned int len)
{
unsigned int i, j;
for (i = 0, j = 0; j < len; i++, j += 4) {
output[j] = (unsigned char)(input[i] & 0xff);
output[j+1] = (unsigned char)((input[i] >> 8) & 0xff);
output[j+2] = (unsigned char)((input[i] >> 16) & 0xff);
output[j+3] = (unsigned char)((input[i] >> 24) & 0xff);
}
}
這是一段將整數數組轉換成為字符數組的代碼,我們看看它到底做了些什麼。假設主函數輸入了一個整數0x30313233,那麼這個子函數的調用就可以寫成下面的樣子:
Encode (output, input, 1)
Input指向一個整數數組,數組的第一個元素是0x30313233,我們接下來看函數轉換
i=0,j=0
output[0]= (unsigned char)(input[0]& 0xff)=0x33
output[1]= (unsigned char)(input[0]& 0xff)=0x32
output[2]= (unsigned char)(input[0]& 0xff)=0x31
output[3]= (unsigned char)(input[0]& 0xff)=0x30
i=0,j=4
跳出循環
output的內存排列順序為
+--+--+--+--+--
|33|32|31|30|
+--+--+--+--+--
^
output
現在大家注意了,input的排列順序是什麼?由計算機原理可知道,在計算機內部,數據的存放順序是“高位對應高位,低位對應低位”,0x30313233中的33因為是個位,是低位,所以對應內存單元的最低位,同理30在內存單元的最高位,由此推出0x30313233在數組中的排列順序為:
+--+--+--+--+--
|33 32 31 30|
+--+--+--+--+--
^
input
結果顯而易見了,這個函數的功能只是將一個無符號整形數組轉換成為了一個無符號字符形數組,作者的目的我雖然不清楚,但是這個地方確實可以優化如下:
output=(unsigned char *)input;
把這個地方叫作算法的優化可能有點牽強,但是算法的優化確實是最為重要的,比如說搜索算法,如果選擇不當,可能要喪失很多的效率。
二、內存拷貝優化
再觀察一下MD5C裡面的一段代碼:
static void MD5_memcpy (unsigned char *output, unsigned int *input, unsigned int len)
{
unsigned int i;
for (i = 0; i < len; i++)
output[i] = input[i];
}
這處的為什麼要修改是非常明顯的,for循環是非常慢的,我們一般可以把類似的代碼替換成為C的庫函數或者操作系統的標准函數,如:
CopyMemory ()
memcpy()
這種內存代碼你也千萬不要嘗試自己去實現,那將是一種災難,在每個操作系統中,內存拷貝可以說是非常頻繁的,所以系統的內存拷貝函數基本上都是非常完美的,不信的話你可以自己寫一段內存拷貝函數,然後和系統的內存拷貝函數比較一下就知道了,具體原代碼可以參考linux中string.lib的實現。
這處代碼是特別值得注意的地方,如果你在你的代碼的運算密集處寫出了類似MD5_memcpy的代碼的化,那麼性能將會急劇的下降,對你的系統將是災難性的。
三、使用匯編優化
下面又一段MD5C裡面的代碼,這種代碼每一次md5加密要運算64次,而我們要窮舉8位數字的話,就需要運算64000000次,將下面的代碼用匯編展開以後大概是23行的匯編代碼,也就是這個轉換將耗費147200000000,即1472億個指令周期。
//參考test/test1的原代碼
#define UINT4 unsigned int
#define ROTATE_LEFT(x, n) (((x) << (n)) | ((x) >> (32-(n))))
#define F(x, y, z) (((x) & (y)) | ((~x) & (z)))
#define FF(a, b, c, d, x, s, ac) { \
(a) += F ((b), (c), (d)) + (x) + (UINT4)(ac); \
(a) = ROTATE_LEFT ((a), (s)); \
(a) += (b); \
}
3.1 減少內存的訪問次數
把test1的代碼反匯編得到代碼如下:
mov eax,dword ptr [ebp-8]
and eax,dword ptr [ebp-0Ch]
mov ecx,dword ptr [ebp-8]
not ecx <-
and ecx,dword ptr [ebp-10h]
or eax,ecx <-
add eax,dword ptr [ebp-14h]
add eax,dword ptr [ebp-1Ch]
mov edx,dword ptr [ebp-4]
add edx,eax <-
mov dword ptr [ebp-4],edx
mov eax,dword ptr [ebp-4]
mov ecx,dword ptr [ebp-18h]
shl eax,cl <-
mov ecx,20h <-
sub ecx,dword ptr [ebp-18h]
mov edx,dword ptr [ebp-4]
shr edx,cl <-
or eax,edx <-
mov dword ptr [ebp-4],eax
mov eax,dword ptr [ebp-4]
add eax,dword ptr [ebp-8]
mov dword ptr [ebp-4],eax
從上面的代碼可以看到,23條編譯後的匯編代碼中有16條是涉及內存訪問指令,考慮到邏輯運算和四則運算的平均指令周期是4,而內存訪問指令平均指令周期是10,所以上敘的內存訪問指令將消耗整個程序時間的七成以上。所以,個人認為匯編的優化,其實質就是減少內存的訪問,能夠在寄存器內部完成的就不要反復的訪問內存,此處我采取強制定義的方式使得這段程序基本不訪問內存。
考慮到 FF(a, b, c, d, x, s, ac) 中s,ac是常數,x是一個數組,不好強制定義成寄存器,所以這裡只強制定義了a,b,c,d四個變量為寄存器,以及tmp1,tmp2兩個寄存器類型的臨時變量。
//參考test/test2的原代碼
#define a esi
#define b edi
#define c edx
#define d ebx
#define tmp1 eax
#define tmp2 ecx
3.2 單句的優化
現在我們首先將上敘C代碼用最簡單樸實的思路轉換成為匯編,其中ROTATE_LEFT(x, n)實際上是一個循環左移,可以替換成為 ROL,加減乘除也可以用匯編相應的代碼來替換,開始要注意的是,考慮到中間的一些參數,比如x,a要反復利用,我們必須把結果用臨時變量來保存,單句的優化如下:
//參考test/test2的原代碼
#define FF(a, b, c, d, x, s, ac)\
__asm mov tmp1,b\
__asm and tmp1,c\
__asm mov tmp2,b\
__asm not tmp2\
__asm and tmp2,d\
__asm or tmp2,tmp1\ <- 以上為F(x, y, z)實現
__asm add tmp2,x\
__asm add tmp2,ac\
__asm add a,tmp2\
__asm rol a,s\ <- (a) = ROTATE_LEFT(x, n)
__asm add a,b\ <- (a) += (b)
<- 以上為FF(a, b, c, d, x, s, ac)實現
3.3 多句的整合優化
上面的代碼已經從23行下降到了11行,是不是到了極限了呢。還沒有,我們還可以作一些匯編行與行之間的優化,注意:
__asm add tmp2,ac此處,我們可以采取連加的語句來實現,大家可能回感到奇怪,匯編中有連加的語句嗎,好像沒有聽說過啊,其實此處優化我們利用的是語句lea,大家看看下面的lea語句:
__asm add a,tmp2
__asm lea a,[tmp2+a+ac]lea的標准用法是:
LEA REG,[BASE+INDEX*SCALE+DISP]其實這種尋址方式常常用於數據結構中訪問特定元素內的一個字段,base為數組的起始地址,scale為每個元素的大小,index為下標。如果數組元素始數據結構,則disp為具體字段在結構中的位移。此處我們是將scale設置為1,所以就變成了:
LEA REG,[BASE+INDEX +DISP]因此就實現了三個數字的連加,類似的優化方法還有不少
所以再次優化後如下共10句:
//參考test/test3的原代碼
#define FF(a, b, c, d, x, s, ac) \
__asm mov tmp1,b \
__asm and tmp1,c \
__asm mov tmp2,b \
__asm not tmp2 \
__asm and tmp2,d \
__asm or tmp2,tmp1 \
__asm lea a,[tmp2+a+ac] \
__asm add a,x \
__asm rol a,s \
__asm add a,b \
3.4 利用mmx指令優化
我的這幾個工程雖然沒有涉及到利用mmx指令優化,但是我們考慮到mmx指令是基於64位的,可以大大的減少運算量,最明顯的例子是des算法,它加密的明文是64位,加密後的密文也是64位,所以使用mmx的寄存器mm0,mm1,……,可以得到性能的提升,不過要注意如何盡可能的滿足U,V流水線的需求,就不在本文的討論范圍內了。有興趣的可以參考下面的地址:
http://www.chinaithero.com/dev/mmx/mmx.htm
我暫時能夠想到的就是這些了,我在確實感到程序優化所帶來的系統性能提升那種快感是無可比擬的,我2002年10月開始寫的時候,一個8位數的窮舉破解花了8個小時,到了2003年1月,時間只有4分鐘,可見優化對一個運算密集型的軟件是多麼的重要。
本文配套源碼