支持並尊重原創!原文地址:http://jingyan.baidu.com/article/2c8c281deb79ed0008252af1.html
判斷一個字符是不是漢字通常有三種方法,第1種用 ASCII 碼判斷,第2種用漢字的 UNICODE 編碼范圍判 斷,第3種用正則表達式判斷,下面是具體方法。
1、用ASCII碼判斷
在 ASCII碼表中,英文的范圍是0-127,而漢字則是大於127,根據這個范圍可以判斷,具體代碼如下:

1 /// <summary>
2 /// 用 ASCII 碼范圍判斷字符是不是漢字
3 /// </summary>
4 /// <param name="text">待判斷字符或字符串</param>
5 /// <returns>真:是漢字;假:不是</returns>
6 public bool CheckStringChinese(string text)
7 {
8 bool res = false;
9 foreach (char t in text)
10 {
11 if ((int)t > 127)
12 res = true;
13 }
14 return res;
15 }
View Code

調用方法:CheckStringChinese("是不是漢字");
2、用漢字的 UNICODE 編碼范圍判斷
漢字的 UNICODE 編碼范圍是4e00-9fbb,根據此范圍也可 以判斷,具體代碼如下:
1 /// <summary>
2 /// 用 UNICODE 編碼范圍判斷字符是不是漢字
3 /// </summary>
4 /// <param name="text">待判斷字符或字符串</param>
5 /// <returns>真:是漢字;假:不是</returns>
6 public bool CheckStringChineseUn(string text)
7 {
8 bool res = false;
9 foreach (char t in text)
10 {
11 if (t >= 0x4e00 && t <= 0x9fbb)
12 {
13 res = true;
14 break;
15 }
16 }
17 return res;
18 }
View Code

調用方法:CheckStringChineseUn("是不是漢字");
3、用正則表達式判斷
用正則表達式判斷也是根據漢字的 UNICODE 編碼范圍判斷的,具體代碼如下:
1 /// <summary>
2 /// 用 正則表達式 判斷字符是不是漢字
3 /// </summary>
4 /// <param name="text">待判斷字符或字符串</param>
5 /// <returns>真:是漢字;假:不是</returns>
6 public bool CheckStringChineseReg(string text)
7 {
8 return System.Text.RegularExpressions.Regex.IsMatch(text, @"[\u4e00-\u9fbb]+$");
9 }
View Code
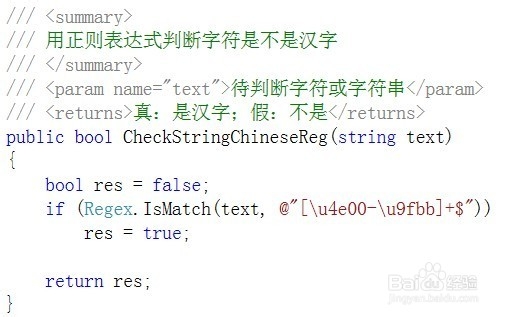
調用方法:CheckStringChineseReg("是不是漢字");