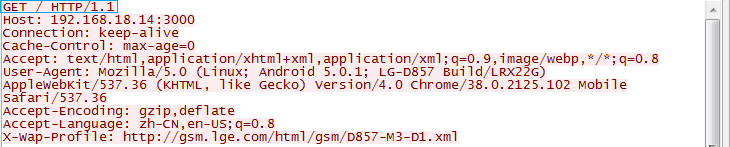
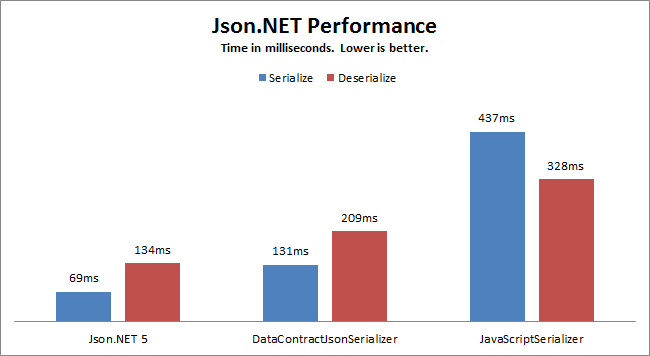
1、讀取網絡中html網頁內容,獲取網頁中元素body內的html,處理所有img元素的src屬性後以字符串返回
if (l_sWenBenHtmlFtpPath.Substring(l_sWenBenHtmlFtpPath.LastIndexOf(".") + 1) == "html")
{
HtmlWeb htmlWeb = new HtmlWeb();
HtmlDocument htmlDoc = htmlWeb.Load(l_sWenBenHtmlFtpPath);
HtmlNode htmlNode = htmlDoc.DocumentNode;
HtmlNodeCollection nodes = htmlNode.SelectNodes("//body"); //使用xpath語法進行查詢
if (nodes != null)
{
foreach (HtmlNode bodyTag in nodes)
{
HtmlNodeCollection nodes2 = htmlNode.SelectNodes("//img"); //使用xpath語法進行查詢
if (nodes2 != null)
{
foreach (HtmlNode imgTag in nodes2)
{
string imgHttpPath = imgTag.Attributes["src"].Value;
imgTag.Attributes["src"].Value = l_sWenBenHtmlFtpPath.Substring(0, l_sWenBenHtmlFtpPath.LastIndexOf("/") + 1) + imgHttpPath;
}
}
l_sWenBenHtml = bodyTag.InnerHtml;
}
}
}
2、通過HtmlAgilityPack Html操作類庫將html格式的字符串加載為html文檔對象,再對html dom進行操作
//1.解碼前台提交的html字串
string sDecodeString = HttpUtility.HtmlDecode(HttpUtility.UrlDecode(sEncodeString));
//2.拼接成完整的html字串
sDecodeString = @"<!DOCTYPE html><html><head><meta http-equiv=""content-type"" content=""text/html;charset=UTF-8""/>"
+ @"</head><body><div>"
+ sDecodeString + @"</div></body></html>";
//3.處理html的img標簽的src屬性-C#的HTML DOM操作
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(sDecodeString.Replace("\n", " "));
HtmlNode node = doc.DocumentNode;
HtmlNodeCollection nodes = node.SelectNodes("//img"); //使用xpath語法進行查詢
if (nodes != null) //沒有img節點時出錯
{
//處理html字符串中img標簽的src屬性
foreach (HtmlNode imgTag in nodes)
{
string imgHttpPath = imgTag.Attributes["src"].Value;
imgHttpPath = imgHttpPath.Substring(imgHttpPath.LastIndexOf("/") + 1);
imgTag.Attributes["src"].Value = imgHttpPath;
}
}
//4.獲取處理後的html字符串
sHtmlString = node.OuterHtml; //處理img中src屬性後的html字符串
//5.將字符串存入html格式的文件中
//do something
持續完善更新中,敬請期待...