大家應該都知道Memcached要想實現分布式只能在客戶端來完成,目前比較流行的是通過一致性hash算法來實現.常規的方法是將server的hash值與server的總台數進行求余,即hash%N,這種方法的弊端是當增減服務器時,將會有較多的緩存需要被重新分配且會造成緩存分配不均勻的情況(有可能某一台服務器分配的很多,其它的卻很少).
今天分享一種叫做”ketama”的一致性hash算法,它通過虛擬節點的概念和不同的緩存分配規則有效的抑制了緩存分布不均勻,並最大限度地減少服務器增減時緩存的重新分布。
假設我們現在有N台Memcached的Server,如果我們用統一的規則對memcached進行Set,Get操作. 使具有不同key的object很均衡的分散存儲在這些Server上,Get操作時也是按同樣規則去對應的Server上取出object,這樣各個Server之間不就是一個整體了嗎?
那到底是一個什麼樣的規則?
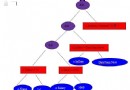
如下圖所示,我們現在有5台(A,B,C,D,E)Memcached的Server,我們將其串聯起來形成一個環形,每一台Server都代表圓環上的一個點,每一個點都具有唯一的Hash值,這個圓環上一共有2^32個點.
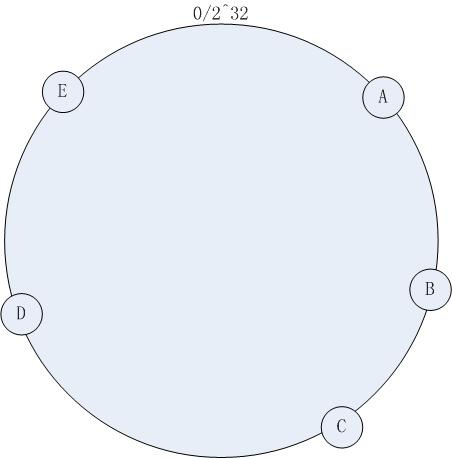
那麼該如何確定每台Server具體分布在哪個點上? 這裡我們通過”Ketama”的Hash算法來計算出每台Server的Hash值,拿到Hash值後就可以對應到圓環上點了.(可以用Server的IP地址作為Hash算法的Key.)
這樣做的好處是,如下圖當我新增Server F時,那麼我只需要將hash值落在C和F之間的object從原本的D上重新分配到F上就可以了,其它的server上的緩存不需要重新分配,並且新增的Server也能及時幫忙緩沖其它Server的壓力.
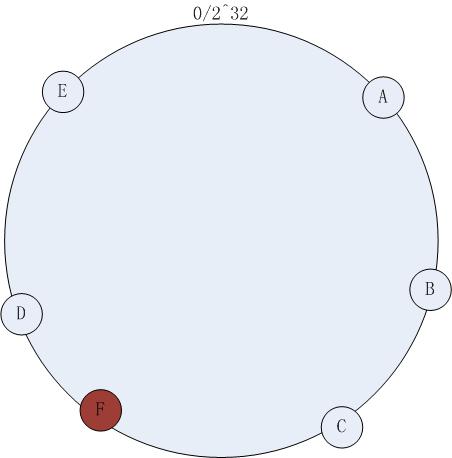
到此我們已經解決了增減服務器時大量緩存需要被重新分配的弊端.那該如何解決緩存分配不均勻的問題呢?因為現在我們的server只占據圓環上的6個點,而圓環上總共有2^32個點,這極其容易導致某一台server上熱點非常多,某一台上熱點很少的情況.
”虛擬節點”的概念很好的解決了這種負載不均衡的問題.通過將每台物理存在的Server分割成N個虛擬的Server節點(N通常根據物理Server個數來定,這裡有個比較好的阈值為250).這樣每個物理Server實際上對應了N個虛擬的節點. 存儲點多了,各個Server的負載自然要均衡一些.就像地鐵站出口一樣,出口越多,每個出口出現擁擠的情況就會越少.
代碼實現:

//保存所有虛擬節點信息, key : 虛擬節點的hash key, value: 虛擬節點對應的真實server
private Dictionary<uint, string> hostDictionary = new Dictionary<uint, string>();
//保存所有虛擬節點的hash key, 已按升序排序
private uint[] ketamaHashKeys = new uint[] { };
//保存真實server主機地址
private string[] realHostArr = new string[] { };
//每台真實server對應虛擬節點個數
private int VirtualNodeNum = 250;
public KetamaVirtualNodeInit(string[] hostArr)
{
this.realHostArr = hostArr;
this.InitVirtualNodes();
}
/// <summary>
/// 初始化虛擬節點
/// </summary>
private void InitVirtualNodes()
{
hostDictionary = new Dictionary<uint, string>();
List<uint> hostKeys = new List<uint>();
if (realHostArr == null || realHostArr.Length == 0)
{
throw new Exception("不能傳入空的Server集合");
}
for (int i = 0; i < realHostArr.Length; i++)
{
for (int j = 0; j < VirtualNodeNum; j++)
{
byte[] nameBytes = Encoding.UTF8.GetBytes(string.Format("{0}-node{1}", realHostArr[i], j));
//調用Ketama hash算法獲取hash key
uint hashKey = BitConverter.ToUInt32(new KetamaHash().ComputeHash(nameBytes), 0);
hostKeys.Add(hashKey);
if (hostDictionary.ContainsKey(hashKey))
{
throw new Exception("創建虛擬節點時發現相同hash key,請檢查是否傳入了相同Server");
}
hostDictionary.Add(hashKey, realHostArr[i]);
}
}
hostKeys.Sort();
ketamaHashKeys = hostKeys.ToArray();
}
到此我們已經知道了所有虛擬節點的Hash值, 現在讓我們來看下當我們拿到一個對象時如何存入Server, 或是拿到一個對象的Key時該如何取出對象.
Set一個對象時,先將對象的Key作為”Ketama”算法的Key,計算出Hash值後我們需要做下面幾個步驟.
1:首先檢查虛擬節點當中是否有與當前對象Hash值相等的,如有則直接將對象存入那個Hash值相等的節點,後面的步驟就不繼續了.
2:如沒有,則找出第一個比當前對象Hash值要大的節點,(節點的Hash值按升序進行排序,圓環上對應按照順時針來排列),即離對象最近的節點,然後將對象存入該節點.
3:如果沒有找到Hash值比對象要大的Server,證明對象的Hash值是介於最後一個節點和第一個節點之間的,也就是圓環上的E和A之間.這種情況就直接將對象存入第一個節點,即A.
代碼實現:
/// <summary>
/// 根據hash key 獲取對應的真實Server
/// </summary>
/// <param name="hash"></param>
/// <returns></returns>
public string GetHostByHashKey(string key)
{
byte[] bytes = Encoding.UTF8.GetBytes(key);
uint hash = BitConverter.ToUInt32(new KetamaHash().ComputeHash(bytes), 0);
//尋找與當前hash值相等的Server.
int i = Array.BinarySearch(ketamaHashKeys, hash);
//如果i小於零則表示沒有hash值相等的虛擬節點
if (i < 0)
{
//將i繼續按位求補,得到數組中第一個大於當前hash值的虛擬節點
i = ~i;
//如果按位求補後的i大於等於數組的大小,則表示數組中沒有大於當前hash值的虛擬節點
//此時直接取第一個server
if (i >= ketamaHashKeys.Length)
{
i = 0;
}
}
//根據虛擬節點的hash key 返回對應的真實server host地址
return hostDictionary[ketamaHashKeys[i]];
}
Get一個對象,同樣也是通過”Ketama”算法計算出Hash值,然後與Set過程一樣尋找節點,找到之後直接取出對象即可.
那麼這個”Ketama”到底長什麼樣呢,讓我們來看看代碼實現.
/// <summary>
/// Ketama hash加密算法
/// 關於HashAlgorithm參見MSDN鏈接
/// http://msdn.microsoft.com/zh-cn/library/system.security.cryptography.hashalgorithm%28v=vs.110%29.aspx
/// </summary>
public class KetamaHash : HashAlgorithm
{
private static readonly uint FNV_prime = 16777619;
private static readonly uint offset_basis = 2166136261;
protected uint hash;
public KetamaHash()
{
HashSizeValue = 32;
}
public override void Initialize()
{
hash = offset_basis;
}
protected override void HashCore(byte[] array, int ibStart, int cbSize)
{
int length = ibStart + cbSize;
for (int i = ibStart; i < length; i++)
{
hash = (hash * FNV_prime) ^ array[i];
}
}
protected override byte[] HashFinal()
{
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return BitConverter.GetBytes(hash);
}
}
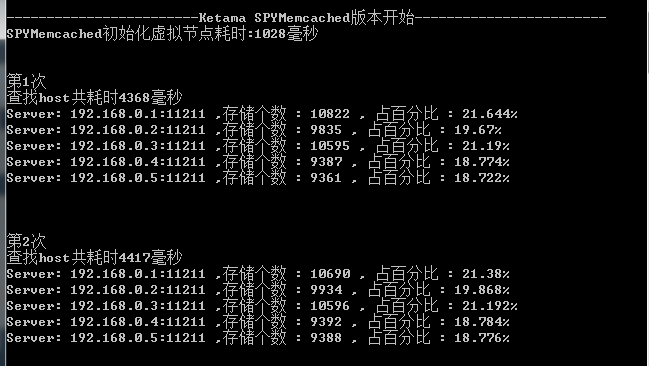
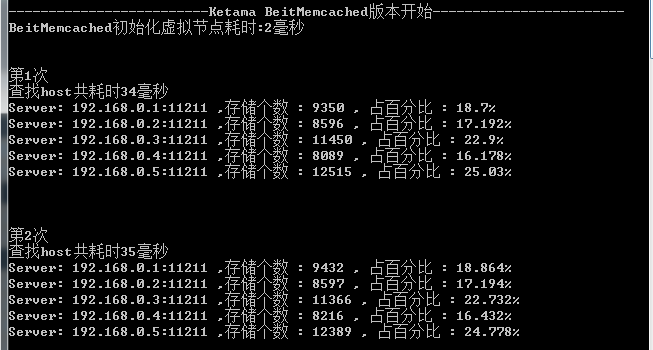
最後我把自己參考BeitMemcached寫的算法與老代(Discuz!代震軍)參考SPYMemcached寫的做了一下對比.
源碼在後面有下載.
結果:查找5W個key的時間比老代的版本快了100多倍,但在負載均衡方面差了一些.
測試數據:
1:真實Server都是5台
2:隨機生成5W個字符串key(生成方法直接拿老代的)
3:虛擬節點都是250個
我的版本:
老代的版本: