最近有一個需求是這樣的,
根據鍵值對存儲類型數據,也算是數據緩存塊模塊功能設計。
一個鍵對應多個值。每一個鍵的值類型相同,但是每個不同的鍵之間類型不一定相同。
Java 設計如下
HashMap<String, ArrayList<Object>>
java把數據添加到集合中
TestIterator tIterator = new TestIterator();
ArrayList<Object> objs = new ArrayList<>();
objs.add("sdfsfdsfdsf");
objs.add("sdfsfdsfdsf");
objs.add("sdfsfdsfdsf");
objs.add("sdfsfdsfdsf");
tIterator.getList().put("Key1", objs);
objs = new ArrayList<>();
objs.add(1);
objs.add(2);
objs.add(3);
objs.add(4);
tIterator.getList().put("Key2", objs);
objs = new ArrayList<>();
objs.add(new String[]{"1", ""});
objs.add(new String[]{"2", ""});
objs.add(new String[]{"3", ""});
objs.add(new String[]{"4", ""});
tIterator.getList().put("Key3", objs);
添加進數據緩存後,然後讀取數據,我們先忽略,緩存集合的線程安全性問題,
{
ArrayList<Object> getObjs = tIterator.getList().get("Key1");
for (Object getObj : getObjs) {
System.out.println("My is String:" + (String) getObj);
}
}
{
ArrayList<Object> getObjs = tIterator.getList().get("Key2");
for (Object getObj : getObjs) {
System.out.println("My is int:" + (int) getObj);
}
}
{
ArrayList<Object> getObjs = tIterator.getList().get("Key3");
for (Object getObj : getObjs) {
String[] strs = (String[]) getObj;
System.out.println("My is String[]:" + strs[0] + " : " + strs[1]);
}
}
我們發現。使用的時候,每個地方都需要轉換。
(String[]) getObj; (int) getObj (String) getObj
同樣代碼需要重復寫,那麼我們是否可以封裝一次呢?
public <T> ArrayList<T> getValue(String keyString, Class<T> t) {
ArrayList<T> rets = new ArrayList<>();
ArrayList<Object> getObjs = _List.get(keyString);
if (getObjs != null) {
for (Object getObj : getObjs) {
//if (getObj instanceof T) {
rets.add((T) getObj);
//}
}
}
return rets;
}
這裡我發現一個問題,不支持泛型檢查,據我很淺的知識了解到,java算是動態類型數據。
並且是偽泛型類型所以不支持泛型類型判定
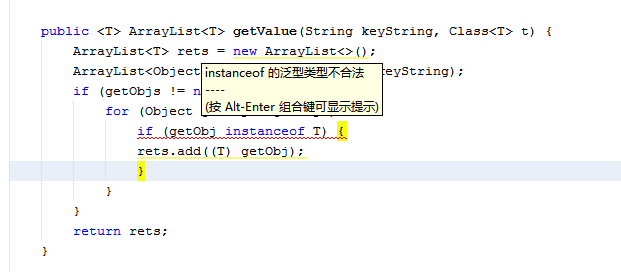
這點很不爽了,為啥不能泛型類型判定。也許是我知識淺薄~!望前輩指點;
再次查看調用
{
ArrayList<String> value = tIterator.getValue("Key1", String.class);
for (String value1 : value) {
}
}
{
ArrayList<Integer> value = tIterator.getValue("Key1", Integer.class);
for (Integer value1 : value) {
}
}
{
ArrayList<String[]> value = tIterator.getValue("Key1", String[].class);
for (String[] value1 : value) {
}
}
稍稍覺得清爽了一點吧。當然,我這裡都是用到基礎類型,如果用到復雜類型,和滿篇調用的時候才能體現出這段代碼的優越性。
更加的符合面向對象編程的重構行和復用性;
可是上面代碼,不曉得大家注意沒,出現一個問題,那就是每一次調用都再一次的聲明了
ArrayList<T> rets = new ArrayList<>();
對象,如果是需要考慮性能問題的時候,我們肯定不能不能這樣。每次調用都需要重新分配ArrayList的內存空間。並且在 ArrayList.add() 的時候每一次都在檢查ArrayList的空間夠不夠,不夠,再次開辟新空間。重組。
雖然這個動作很快,可是如果我們緩存的數據過多。那麼情況可就不一樣了。且伴隨著每一次的調用都是一個消耗。訪問次數過多的話。那麼程序的的性能勢必會變的低下。
再次考慮,是否可以用迭代器實現功能呢?
查看了一下迭代器實現方式,我無法完成我需求的迭代器功能。只能依葫蘆畫瓢,實現了一個自定義的迭代器功能。
class TestIterator {
HashMap<String, ArrayList<Object>> _List = new HashMap<>();
public TestIterator() {
}
public <T> ArrayList<T> getValue(String keyString, Class<T> t) {
ArrayList<T> rets = new ArrayList<>();
ArrayList<Object> getObjs = _List.get(keyString);
if (getObjs != null) {
for (Object getObj : getObjs) {
//if (getObj instanceof T) {
rets.add((T) getObj);
//}
}
}
return rets;
}
public HashMap<String, ArrayList<Object>> getList() {
return _List;
}
public void setList(HashMap<String, ArrayList<Object>> _List) {
this._List = _List;
}
public <T> TestIterator.ArrayIterator<T> iterator(String keyString, Class<T> t) {
return new ArrayIterator<T>(keyString);
}
public class ArrayIterator<T> {
private String key;
int index = -1;
private T content;
public ArrayIterator(String key) {
this.key = key;
}
public void reset() {
index = -1;
}
public T getContent() {
//忽略是否存在鍵的問題
Object get = TestIterator.this._List.get(key).get(index);
return (T) get;
}
public boolean next() {
//忽略是否存在鍵的問題
if (index >= TestIterator.this._List.get(key).size()) {
reset();
return false;
}
index++;
return true;
}
}
}
調用方式
{
TestIterator.ArrayIterator<String> iterator1 = tIterator.iterator("Key1", String.class);
while (iterator1.next()) {
String content = iterator1.getContent();
}
}
{
TestIterator.ArrayIterator<Integer> iterator1 = tIterator.iterator("Key2", Integer.class);
while (iterator1.next()) {
Integer content = iterator1.getContent();
}
}
{
TestIterator.ArrayIterator<String[]> iterator = tIterator.iterator("Key3", String[].class);
while (iterator.next()) {
String[] content = iterator.getContent();
}
}
總結了一些問題,
Java的泛型是偽泛型,底層其實都是通過object對象,裝箱拆箱完成的。
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
這個從我目前代碼設計思路我能理解。如果讓我自己設計。也行也會設計如此。
但是無法理解為什麼使用泛型無法類型判定;
我這個自定義的迭代器無法使用 for each 功能;
說了這麼多。接下來我們看看.net;
C# 設計如下
Dictionary<String, List<Object>>
TestIterator tIterator = new TestIterator();
List<Object> objs = new List<Object>();
objs.Add("sdfsfdsfdsf");
objs.Add("sdfsfdsfdsf");
objs.Add("sdfsfdsfdsf");
objs.Add("sdfsfdsfdsf");
tIterator["Key1"] = objs;
objs = new List<Object>();
objs.Add(1);
objs.Add(2);
objs.Add(3);
objs.Add(4);
tIterator["Key2"] = objs;
objs = new List<Object>();
objs.Add(new String[] { "1", "" });
objs.Add(new String[] { "2", "" });
objs.Add(new String[] { "3", "" });
objs.Add(new String[] { "4", "" });
tIterator["Key3"] = objs;
由於有了以上 Java 部分的代碼和思路,那麼我們直接創建自定義迭代器就可以了;
public class TestIterator : Dictionary<String, List<Object>>
{
public IEnumerable<T> CreateEnumerator<T>(String name)
{
if (this.ContainsKey(name))
{
List<Object> items = this[name];
foreach (var item in items)
{
if (item is T)
{
Console.WriteLine(item);
yield return (T)item;
}
}
}
}
}
查看調用方式
foreach (var item in tIterator.CreateEnumerator<String>("tt1"))
{
Console.WriteLine(item + "艹艹艹艹");
}
輸出結果:
yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf
查看對比一下調用方式
foreach (var item in tIterator.CreateEnumerator<String>("Key1"))
{
Console.WriteLine("foreach : " + item);
}
Console.WriteLine("===============分割線==============");
IEnumerable<String> getObjs = tIterator.CreateEnumerator<String>("Key1").ToList();
foreach (var item in getObjs)
{
Console.WriteLine("foreach : " + item);
}
主要上面的兩張調用方式。輸出結果完全不同
yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf ===============分割線============== yield return : sdfsfdsfdsf yield return : sdfsfdsfdsf yield return : sdfsfdsfdsf yield return : sdfsfdsfdsf foreach : sdfsfdsfdsf foreach : sdfsfdsfdsf foreach : sdfsfdsfdsf foreach : sdfsfdsfdsf
可以看出第二種調用方式是全部返回了數據,那麼就和之前java的設計如出一轍了.
public <T> ArrayList<T> getValue(String keyString, Class<T> t) {
ArrayList<T> rets = new ArrayList<>();
ArrayList<Object> getObjs = _List.get(keyString);
if (getObjs != null) {
for (Object getObj : getObjs) {
//if (getObj instanceof T) {
rets.add((T) getObj);
//}
}
}
return rets;
}
雖然表面看上去沒有聲明List對象,可實際底層依然做好了底層對象的分配對性能也是有所消耗;
C# 迭代器實現了泛型類型判定檢測;
且沒有多余的開銷,
總結。
Java的自定義迭代。多出了一下定義
private String key;
int index = -1;
private T content;
不支持泛型的類型判別;
C# 的自定義迭代器 沒什麼多余的代碼開銷,但其實底層依然做了我們類使用Java的自定義代碼段。只是我們無需再定義而已。
C# 支持 泛型類型的判別。
其實這些都是語法糖的問題。沒有什麼高明或者不高明之處。但是在面對快速開發和高性能程序的基礎上,優勢劣勢。自己判別了。
以上代碼不足之處,還請各位看客之處。
不喜勿碰~!~!~!