List和Dictionary泛型類查找效率淺析,listdictionary
List和Dictionary泛型類查找效率存在巨大差異,前段時間親歷了一次。事情的背景是開發一個匹配程序,將書籍(BookID)推薦給網友(UserID),生成今日推薦數據時,有條規則是同一書籍七日內不能推薦給同一網友。
同一書籍七日內不能推薦給同一網友規則的實現是程序不斷優化的過程,第一版程序是直接取數據庫,根據BookID+UserID查詢七日內有無記錄,有的話不進行分配。但隨著數據量的增大,程序運行時間越來越長,於是開始優化。第一次優化是把所有七日內的數據取出來,放到List<T>中,然後再內存中進行查找,發現這樣效率只是稍有提高,但不明顯。第二次優化采用了Dictionary<TKey, TValue>,意外的發現效果不是一般的好,程序效率提高了幾倍。
下面是偽代碼,簡化了程序代碼,只是為說明List和Dictionary效率的差別,並不具備實際意義。

![]()
/// <summary>
/// 集合類效率測試
/// </summary>
public class SetEfficiencyTest
{
static List<TestModel> todayList = InitTodayData();
static List<TestModel> historyList = InitHisoryData();
public static void Run()
{
CodeTimer.Time("ListTest", 1, ListTest);
CodeTimer.Time("DictionaryTest", 1, DictionaryTest);
}
public static void ListTest()
{
List<TestModel> resultList = todayList.FindAll(re =>
{
if (historyList.Exists(m => m.UserID == re.UserID && m.BookID == re.BookID))
{
return false;
}
return true;
});
}
public static void DictionaryTest()
{
Dictionary<int, List<string>> bDic = new Dictionary<int, List<string>>();
foreach (TestModel obj in historyList)
{
if (!bDic.ContainsKey(obj.UserID))
{
bDic.Add(obj.UserID, new List<string>());
}
bDic[obj.UserID].Add(obj.BookID);
}
List<TestModel> resultList = todayList.FindAll(re =>
{
if (bDic.ContainsKey(re.UserID) && bDic[re.UserID].Contains(re.BookID))
{
return false;
}
return true;
});
}
/// <summary>
/// 初始化數據(今日)
/// </summary>
/// <returns></returns>
public static List<TestModel> InitTodayData()
{
List<TestModel> list = new List<TestModel>();
for (int i = 0; i < 10000; i++)
{
list.Add(new TestModel() { UserID = i, BookID = i.ToString() });
}
return list;
}
/// <summary>
/// 初始化數據(歷史)
/// </summary>
/// <returns></returns>
public static List<TestModel> InitHisoryData()
{
List<TestModel> list = new List<TestModel>();
Random r = new Random();
int loopTimes = 60000;
for (int i = 0; i < loopTimes; i++)
{
list.Add(new TestModel() { UserID = r.Next(0, loopTimes), BookID = i.ToString() });
}
return list;
}
/// <summary>
/// 測試實體
/// </summary>
public class TestModel
{
/// <summary>
/// 用戶ID
/// </summary>
public int UserID { get; set; }
/// <summary>
/// 書ID
/// </summary>
public string BookID { get; set; }
}
}
View Code
輸出如下:
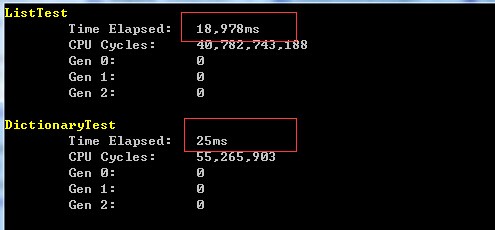
真是想不到,兩者效率相差這麼多。接下來研究下兩者差異巨大的原因。
List<T>.Exists()函數的實現:
![]()
public bool Exists(Predicate<T> match)
{
return this.FindIndex(match) != -1;
}
public int FindIndex(Predicate<T> match)
{
return this.FindIndex(0, this._size, match);
}
public int FindIndex(int startIndex, int count, Predicate<T> match)
{
if (startIndex > this._size)
{
ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.startIndex, ExceptionResource.ArgumentOutOfRange_Index);
}
if (count < 0 || startIndex > this._size - count)
{
ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.count, ExceptionResource.ArgumentOutOfRange_Count);
}
if (match == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.match);
}
int num = startIndex + count;
for (int i = startIndex; i < num; i++)
{
if (match(this._items[i]))
{
return i;
}
}
return -1;
}
View Code
List<T>.Exists 本質是通過循環查找出該條數據,每一次的調用都會重頭循環,所以效率很低。顯然,這是不可取的。
Dictionary<TKey, TValue>.ContainsKey()函數的實現:
![]()
public bool ContainsKey(TKey key)
{
return this.FindEntry(key) >= 0;
}
// System.Collections.Generic.Dictionary<TKey, TValue>
private int FindEntry(TKey key)
{
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (this.buckets != null)
{
int num = this.comparer.GetHashCode(key) & 2147483647;
for (int i = this.buckets[num % this.buckets.Length]; i >= 0; i = this.entries[i].next)
{
if (this.entries[i].hashCode == num && this.comparer.Equals(this.entries[i].key, key))
{
return i;
}
}
}
return -1;
}
View Code
Dictionary<TKey, TValue>.ContainsKey() 內部是通過Hash查找實現的,所以效率比List高出很多。
最後,給出MSDN上的建議:
1.如果需要非常快地添加、刪除和查找項目,而且不關心集合中項目的順序,那麼首先應該考慮使用 System.Collections.Generic.Dictionary<TKey, TValue>(或者您正在使用 .NET Framework 1.x,可以考慮 Hashtable)。三個基本操作(添加、刪除和包含)都可快速操作,即使集合包含上百萬的項目。
2.如果您的使用模式很少需要刪除和大量添加,而重要的是保持集合的順序,那麼您仍然可以選擇 List<T>。雖然查找速度可能比較慢(因為在搜索目標項目時需要遍歷基礎數組),但可以保證集合會保持特定的順序。
3.您可以選擇 Queue<T> 實現先進先出 (FIFO) 順序或 Stack<T> 實現後進先出 (LIFO) 順序。雖然 Queue<T> 和 Stack<T> 都支持枚舉集合中的所有項目,但前者只支持在末尾插入和從開頭刪除,而後者只支持從開頭插入和刪除。
4.如果需要在實現快速插入的同時保持順序,那麼使用新的 LinkedList<T> 集合可幫助您提高性能。與 List<T> 不同,LinkedList<T> 是作為動態分配的對象鏈實現。與 List<T> 相比,在集合中間插入對象只需要更新兩個連接和添加新項目。從性能的角度來看,鏈接列表的缺點是垃圾收集器會增加其活動,因為它必須遍歷整個列表以確保沒有對象沒有被釋放。另外,由於每個節點相關的開銷以及每個節點在內存中的位置等原因,大的鏈接列表可能會出現性能問題。雖然將項目插入到 LinkedList<T> 的實際操作比在 List<T> 中插入要快得多,但是找到要插入新值的特定位置仍需遍歷列表並找到正確的位置。
參考資料:CLR 完全介紹: 最佳實踐集合, List和hashtable之查找效率