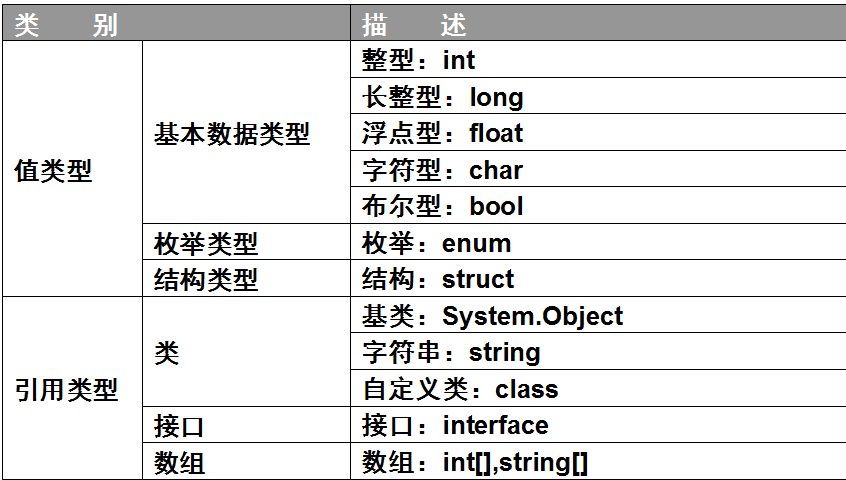
無論什麼類型,所有的數據都是一系列的位,即0和1。變量的含義是通過解釋這些程序的方式來傳達的。最簡單的是char類型,這種類型用一個數字表示Unicode字符集中的一個字符。實際上,這個數字與ushort的存儲方式完全相同——它們都存儲在0~65535之間。
然而,一般的,不同類型的變量使用不同的模式來表示數據,這意味著,即使把一系列的位從一種類型的變量移動到另一種類型的變量中,結果往往與預期不同。
這並不是數據位從一個變量到另一個變量的一對一的映射,而是需要對數據類型進行轉換。類型轉換有隱式轉換和顯示轉換之分。
隱式轉換:從A類型到B類型的轉換可以再所有情況下進行,轉換規則比較簡單,可以讓編譯器執行。轉換規則:任何類型A只要其取值范圍完全包含在類型B的取值范圍內,就可以隱式轉換為類型B;
顯示轉換:從A類型到B類型的轉換只能在某些情況下進行,轉換規則比較復雜,需要進行某種類型處理。
請看下面例子:
//嘗試將short值轉換成byte值
byte destinationVar;
short sourceVar=7;
destinationVar=sourceVar;
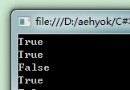
Console.WriteLine("sourceVar:{0}",sourceVar);
Console.WriteLine("destinationVar:{0}",destinationVar);
如果編譯這段代碼,就會出現以下錯誤:
Cannot implicitly convert type 'short' to 'byte'. An explicit conversion exists(are you missing a cast?)
從而引入強制轉換(強迫數據從一種類型轉換成另一種類型)語法比較簡單:<(destinationVar的類型)sourceVar>,也就是改成:
byte destinationVar;
short sourceVar=7;
destinationVar=(byte)sourceVar;
Console.WriteLine("sourceVar:{0}",sourceVar);
Console.WriteLine("destinationVar:{0}",destinationVar);
這將把<sourceVar>中的short類型的值轉換為<destinationVar>中byte類型的值。當然,這只是在某些情況下是可行的,彼此之間幾乎沒有什麼關系的類型或根本沒有關系的類型不能強制轉換類型。
顯示的把數據從一種類型轉換為另一種類型時,可能導致數據溢出,因為源變量的取值范圍與目標變量的取值范圍往往有出入,我們可以從其存儲的數據本身(開始說了,實際是一系列的位)得到解析。
檢查溢出,要用到兩個關鍵字checked和uncheked,稱為表達式溢出的檢查上下文。
byte destinationVar;
short sourceVar=7;
destinationVar=checked((byte)sourceVar);
Console.WriteLine("sourceVar:{0}",sourceVar);
Console.WriteLine("destinationVar:{0}",destinationVar);
如果修改變量sourceVar的值,使其大於255,執行程序就會出錯,並提示溢出。
當然,還有Convert命令,它也用於顯示的類型轉換,下面給出以上所有類型轉換的一個實例:
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
short shortResult, shortVar = 4;
int integerVar = 67;
long longResult;
float floatVar = 10.5F;
double doubleResult, doubleVar = 99.999;
string stringResult, stringVar = "17";
bool boolVar = true;
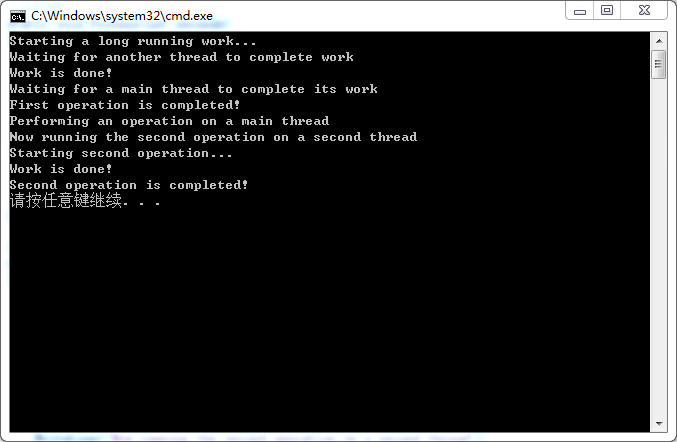
Console.WriteLine("Variable Conversion Examples\n");
doubleResult = floatVar * shortVar;
Console.WriteLine("Implicit,->double:{0}*{1}->{2}", floatVar, shortVar, doubleResult);
shortResult = (short)floatVar;
Console.WriteLine("Implicit,->short:{0}->{1}", floatVar, shortResult);
stringResult = Convert.ToString(boolVar) + Convert.ToString(doubleVar);
Console.WriteLine("Implicit,->string:\"{0}\"+\"{1}\"->{2}", boolVar, doubleVar, stringResult);
longResult = integerVar + Convert.ToInt64(stringVar);
Console.WriteLine("Mixed, ->long:{0}+{1}->{2}", integerVar, stringVar, longResult);
Console.ReadKey();
}
}
}
main()
{
int i,j,temp;
int a[10];
for(i=0;i<10;i++)
scanf ("%d,",&a[i]);
for(j=0;j<=9;j++)
{ for (i=0;i<10-j;i++)
if (a[i]>a[i+1])
{ temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;}
}
for(i=1;i<11;i++)
printf("%5d,",a[i] );
printf("\n");
}
--------------
冒泡算法
冒泡排序的算法分析與改進
交換排序的基本思想是:兩兩比較待排序記錄的關鍵字,發現兩個記錄的次序相反時即進行交換,直到沒有反序的記錄為止。
應用交換排序基本思想的主要排序方法有:冒泡排序和快速排序。
冒泡排序
1、排序方法
將被排序的記錄數組R[1..n]垂直排列,每個記錄R看作是重量為R.key的氣泡。根據輕氣泡不能在重氣泡之下的原則,從下往上掃描數組R:凡掃描到違反本原則的輕氣泡,就使其向上"飄浮"。如此反復進行,直到最後任何兩個氣泡都是輕者在上,重者在下為止。
(1)初始
R[1..n]為無序區。
(2)第一趟掃描
從無序區底部向上依次比較相鄰的兩個氣泡的重量,若發現輕者在下、重者在上,則交換二者的位置。即依次比較(R[n],R[n-1]),(R[n-1],R[n-2]),…,(R[2],R[1]);對於每對氣泡(R[j+1],R[j]),若R[j+1].key<R[j].key,則交換R[j+1]和R[j]的內容。
第一趟掃描完畢時,"最輕"的氣泡就飄浮到該區間的頂部,即關鍵字最小的記錄被放在最高位置R[1]上。
(3)第二趟掃描
掃描R[2..n]。掃描完畢時,"次輕"的氣泡飄浮到R[2]的位置上……
最後,經過n-1 趟掃描可得到有序區R[1..n]
注意:
第i趟掃描時,R[1..i-1]和R[i..n]分別為當前的有序區和無序區。掃描仍是從無序區底部向上直至該區頂部。掃描完畢時,該區中最輕氣泡飄浮到頂部位置R上,結果是R[1..i]變為新的有序區。
2、冒泡排序過程示例
對關鍵字序列為49 38 65 97 76 13 27 49的文件進行冒泡排序的過程
3、排序算法
(1)分析
因為每一趟排序都使有序區增加了一個氣泡,在經過n-1趟排序之後,有序區中就有n-1個氣泡,而無序區中氣泡的重量總是大於等於有序區中氣泡的重量,所以整個冒泡排序過程至多需要進行n-1趟排序。
若在某一趟排序中未發現氣泡位置的交換,則說明待排序的無序區中所有氣泡均滿足輕者在上,重者在下的原則,因此,冒泡排序過程可在此趟排序後終止。為此,在下面給出的算法中,引入一個布爾量exchange,在每趟排序開始前,先將其置為FALSE。若排序過程中發生了交換,則將其置為TRUE。各趟排序結束時檢查exchange,若未曾發生過交換則終止算法,不再進行下一趟排序。
(2)具體算法
void BubbleSort(SeqList R)
{ //R(l..n)是待排序的文件,采用自下向上掃描,對R做冒泡排序
int i,j;
Boolean exchange; //交換標志
for(i=1;i&......余下全文>>
main()
{
int i,j,temp;
int a[10];
for(i=0;i<10;i++)
scanf ("%d,",&a[i]);
for(j=0;j<=9;j++)
{ for (i=0;i<10-j;i++)
if (a[i]>a[i+1])
{ temp=a[i];
a[i]=a[i+1];
a[i+1]=temp;}
}
for(i=1;i<11;i++)
printf("%5d,",a[i] );
printf("\n");
}
--------------
冒泡算法
冒泡排序的算法分析與改進
交換排序的基本思想是:兩兩比較待排序記錄的關鍵字,發現兩個記錄的次序相反時即進行交換,直到沒有反序的記錄為止。
應用交換排序基本思想的主要排序方法有:冒泡排序和快速排序。
冒泡排序
1、排序方法
將被排序的記錄數組R[1..n]垂直排列,每個記錄R看作是重量為R.key的氣泡。根據輕氣泡不能在重氣泡之下的原則,從下往上掃描數組R:凡掃描到違反本原則的輕氣泡,就使其向上"飄浮"。如此反復進行,直到最後任何兩個氣泡都是輕者在上,重者在下為止。
(1)初始
R[1..n]為無序區。
(2)第一趟掃描
從無序區底部向上依次比較相鄰的兩個氣泡的重量,若發現輕者在下、重者在上,則交換二者的位置。即依次比較(R[n],R[n-1]),(R[n-1],R[n-2]),…,(R[2],R[1]);對於每對氣泡(R[j+1],R[j]),若R[j+1].key<R[j].key,則交換R[j+1]和R[j]的內容。
第一趟掃描完畢時,"最輕"的氣泡就飄浮到該區間的頂部,即關鍵字最小的記錄被放在最高位置R[1]上。
(3)第二趟掃描
掃描R[2..n]。掃描完畢時,"次輕"的氣泡飄浮到R[2]的位置上……
最後,經過n-1 趟掃描可得到有序區R[1..n]
注意:
第i趟掃描時,R[1..i-1]和R[i..n]分別為當前的有序區和無序區。掃描仍是從無序區底部向上直至該區頂部。掃描完畢時,該區中最輕氣泡飄浮到頂部位置R上,結果是R[1..i]變為新的有序區。
2、冒泡排序過程示例
對關鍵字序列為49 38 65 97 76 13 27 49的文件進行冒泡排序的過程
3、排序算法
(1)分析
因為每一趟排序都使有序區增加了一個氣泡,在經過n-1趟排序之後,有序區中就有n-1個氣泡,而無序區中氣泡的重量總是大於等於有序區中氣泡的重量,所以整個冒泡排序過程至多需要進行n-1趟排序。
若在某一趟排序中未發現氣泡位置的交換,則說明待排序的無序區中所有氣泡均滿足輕者在上,重者在下的原則,因此,冒泡排序過程可在此趟排序後終止。為此,在下面給出的算法中,引入一個布爾量exchange,在每趟排序開始前,先將其置為FALSE。若排序過程中發生了交換,則將其置為TRUE。各趟排序結束時檢查exchange,若未曾發生過交換則終止算法,不再進行下一趟排序。
(2)具體算法
void BubbleSort(SeqList R)
{ //R(l..n)是待排序的文件,采用自下向上掃描,對R做冒泡排序
int i,j;
Boolean exchange; //交換標志
for(i=1;i&......余下全文>>