DHT抓取程序開源地址:https://github.com/h31h31/H31DHTDEMO
數據處理程序開源地址:https://github.com/h31h31/H31DHTMgr
1.當服務器查詢本地一個文件是否存在都需要200MS(毫秒)的時候的時候你怎麼辦?(文件夾有4096個一級文件夾,每個文件夾有1000個文件,23.當服務器網站搜索關鍵詞的時候需要5S左右的時候需要怎麼辦?(目前搜索采用SQL語句的LIKE查詢)
問題1:先看下服務器移動文件中的花費時間:
4096個文件夾需要移動剛開始估計34個小時(看下圖大概一分鐘處理2個文件夾,一小時處理120個,總共需要34小時),
看來當初的設計很有問題,光移動就需要花費這麼久,以後數據再大點,設計如果需要修改還需要更多時間

移動種子文件到子文件夾下
/// <summary>
/// 批量插入
/// </summary>
public static int BulkInsertFile(string tablename,string filepath)
{
try
{
string strSql = string.Format("BULK INSERT {0} FROM '{1}' WITH ( FIELDTERMINATOR='|',ROWTERMINATOR=';\\n',BATCHSIZE = 5000)", tablename, filepath);
return dbsql.ExecuteNonQuery(CommandType.Text, strSql.ToString(), null);
}
catch (System.Exception ex)
{
H31Debug.PrintLn("AddNewHashLOGFile" + filepath + ex.StackTrace);
}
return -1;
}
需要注意的問題有如何保證中文進數據庫不是亂碼的問題.
保存的時候使用Unicode編碼.SQLSERVER2005以後就不支持UTF8就行了.有些日文等保存到數據庫就會有問題,采用Unicode編碼就好了.
StreamWriter writer = StreamWriter(filename,
使用BULKINSERT批量插入就需要將HASH表裡面的ID字段取消自增的屬性,在本地操作基本上沒有什麼問題,因為本地數據量小,但一到服務器上就不行了,
12個表有一個表數據量大,修改不了,其它表修改成功,嚇得直接冒汗了,
如果修改不了,批量插入的設計就是白白設計的,因為HASH表的ID字段被關聯到其它表了,所以本地生成文件的時候這個ID必須有.
網上找了一堆的方法,說是修改工具欄裡面的選項,如下圖所示:
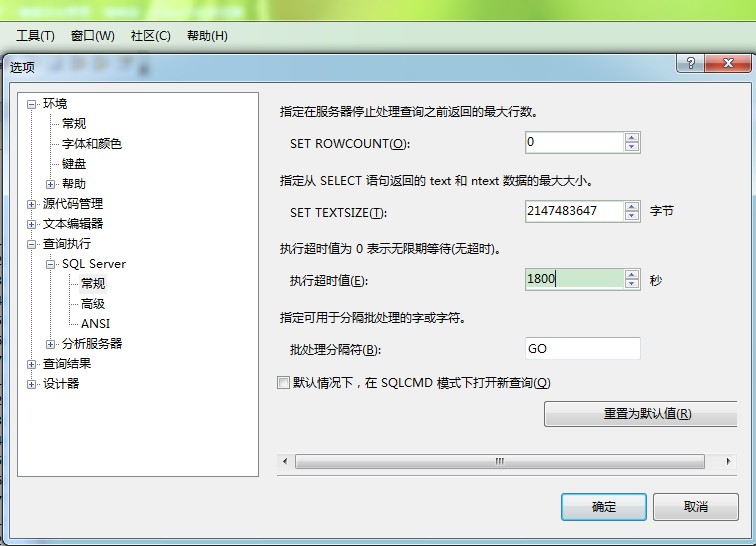
發現修改後還是沒有用,數據庫重啟也沒有用.
急得不行的情況下,掛停網站,將數據庫分離收縮附加回來再修改,還是執行超時.
在沒有人請教的情況下,只能慢慢的GOOGLE搜索英文的文章了,終於發現一個修改注冊表的方法了.
This timeout setting value , but it still times seconds.
剛開始修改為300秒也不行,直接修改為1800秒,也基本上無效,只能重啟數據庫,多點幾次保存修改,後來有一次成功了.看來工具也需要有會配置的時候..
由於之前讓數據庫自動生成自增ID,目前看來是個錯誤的設計,現在只能在錯一半基本上改了,因為重新跑一次所有數據,估計最少需要15天的時間.
現在盡量不與數據庫實時打交道,程序啟動時,遍歷表的最大ID號,然後本地用來生成自增ID號直接存儲數據到本地文件文件中,
就需要保證ID號自增的唯一性了,哪就需要考慮:
1.軟件唯一運行的問題;
2.軟件開始運行後保證以前生成的SQL批量文本文件全部插入到數據庫中,然後才能去取最大ID號的問題;
3.生成的SQL批量文本文件需要考慮如果插入不成功就可能數據庫已經存在的問題;
4.存在的情況下需要讀取一條條插入的問題.
目前基本上軟件的流程修改得差不多了,少用數據庫,這就給網站查詢速度更小的壓力了.
由於網站還是采用SQL的LIKE語句來搜索,所以時間大概在2-5S的時間,特別是搜索結果比較多的時候顯示更慢.
經過大家的推薦使用hubble.net,Lucene.net目前分析的結果是采用Lucene.net.
由於服務器目前內存不夠的情況下,只能讓CPU用起來的問題了,Lucene采用文本來索引,占用內存少的情況下,目前只能這麼架構測試了.
由於Lucene還在研究中,所以後期有什麼不會的地方,請大家指點下.
1.目前還沒有搞明白移動很多小文件需要這麼長的時間.
2.批量插入會不會引起什麼其它的問題還需要進一步觀察.
希望有了解的朋友在此留言指教下.
大家看累了,就移步到娛樂區http://h31bt.com 去看看,休息下...
希望大家多多推薦哦...大家的推薦才是下一篇介紹的動力...
祝大家國慶節快樂.........