ArrayList 和Vector是采用數組方式存儲數據,此數組元素數大於實際存儲的數據以便增加和插入元素,都允許直接序號索引元素,但是插入數據要設計到數組元素移動等內存操作,所以索引數據快插入數據慢,Vector由於使用了synchronized方法(線程安全)所以性能上比ArrayList要差,LinkedList使用雙向鏈表實現存儲,按序號索引數據需要進行向前或向後遍歷,但是插入數據時只需要記錄本項的前後項即可,所以插入數度較快!
線性表,鏈表,哈希表是常用的數據結構,在進行Java開發時,JDK已經為我們提供了一系列相應的類來實現基本的數據結構。這些類均在java.util包中。本文試圖通過簡單的描述,向讀者闡述各個類的作用以及如何正確使用這些類。
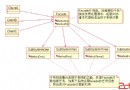
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Map
├Hashtable
├HashMap
└WeakHashMap
Collection接口
Collection是最基本的集合接口,一個Collection代表一組Object,即Collection的元素(Elements)。一些Collection允許相同的元素而另一些不行。一些能排序而另一些不行。Java SDK不提供直接繼承自Collection的類,Java SDK提供的類都是繼承自Collection的“子接口”如List和Set。
所有實現Collection接口的類都必須提供兩個標准的構造函數:無參數的構造函數用於創建一個空的Collection,有一個Collection參數的構造函數用於創建一個新的Collection,這個新的Collection與傳入的Collection有相同的元素。後一個構造函數允許用戶復制一個Collection。
如何遍歷Collection中的每一個元素?不論Collection的實際類型如何,它都支持一個iterator()的方法,該方法返回一個迭代子,使用該迭代子即可逐一訪問Collection中每一個元素。典型的用法如下:
Iterator it = collection.iterator(); // 獲得一個迭代子
while(it.hasNext()) {
Object obj = it.next(); // 得到下一個元素
}
由Collection接口派生的兩個接口是List和Set。
List接口
List是有序的Collection,使用此接口能夠精確的控制每個元素插入的位置。用戶能夠使用索引(元素在List中的位置,類似於數組下標)來訪問List中的元素,這類似於Java的數組。
和下面要提到的Set不同,List允許有相同的元素。
除了具有Collection接口必備的iterator()方法外,List還提供一個listIterator()方法,返回一個ListIterator接口,和標准的Iterator接口相比,ListIterator多了一些add()之類的方法,允許添加,刪除,設定元素,還能向前或向後遍歷。
實現List接口的常用類有LinkedList,ArrayList,Vector和Stack。
LinkedList類
LinkedList實現了List接口,允許null元素。此外LinkedList提供額外的get,remove,insert方法在LinkedList的首部或尾部。這些操作使LinkedList可被用作堆棧(stack),隊列(queue)或雙向隊列(deque)。
注意LinkedList沒有同步方法。如果多個線程同時訪問一個List,則必須自己實現訪問同步。一種解決方法是在創建List時構造一個同步的List:
List list = Collections.synchronizedList(new LinkedList(...));
ArrayList類
ArrayList實現了可變大小的數組。它允許所有元素,包括null。ArrayList沒有同步。
size,isEmpty,get,set方法運行時間為常數。但是add方法開銷為分攤的常數,添加n個元素需要O(n)的時間。其他的方法運行時間為線性。
每個ArrayList實例都有一個容量(Capacity),即用於存儲元素的數組的大小。這個容量可隨著不斷添加新元素而自動增加,但是增長算法並沒有定義。當需要插入大量元素時,在插入前可以調用ensureCapacity方法來增加ArrayList的容量以提高插入效率。
和LinkedList一樣,ArrayList也是非同步的(unsynchronized)。
Vector類
Vector非常類似ArrayList,但是Vector是同步的。由Vector創建的Iterator,雖然和ArrayList創建的Iterator是同一接口,但是,因為Vector是同步的,當一個Iterator被創建而且正在被使用,另一個線程改變了Vector的狀態(例如,添加或刪除了一些元素),這時調用Iterator的方法時將拋出ConcurrentModificationException,因此必須捕獲該異常。
Stack 類
Stack繼承自Vector,實現一個後進先出的堆棧。Stack提供5個額外的方法使得Vector得以被當作堆棧使用。基本的push和pop方法,還有peek方法得到棧頂的元素,empty方法測試堆棧是否為空,search方法檢測一個元素在堆棧中的位置。Stack剛創建後是空棧。
Set接口
Set是一種不包含重復的元素的Collection,即任意的兩個元素e1和e2都有e1.equals(e2)=false,Set最多有一個null元素。
很明顯,Set的構造函數有一個約束條件,傳入的Collection參數不能包含重復的元素。
請注意:必須小心操作可變對象(Mutable Object)。如果一個Set中的可變元素改變了自身狀態導致Object.equals(Object)=true將導致一些問題。
Map接口
請注意,Map沒有繼承Collection接口,Map提供key到value的映射。一個Map中不能包含相同的key,每個key只能映射一個value。Map接口提供3種集合的視圖,Map的內容可以被當作一組key集合,一組value集合,或者一組key-value映射。
Hashtable類
Hashtable繼承Map接口,實現一個key-value映射的哈希表。任何非空(non-null)的對象都可作為key或者value。
添加數據使用put(key, value),取出數據使用get(key),這兩個基本操作的時間開銷為常數。
Hashtable通過initial capacity和load factor兩個參數調整性能。通常缺省的load factor 0.75較好地實現了時間和空間的均衡。增大load factor可以節省空間但相應的查找時間將增大,這會影響像get和put這樣的操作。
使用Hashtable的簡單示例如下,將1,2,3放到Hashtable中,他們的key分別是”one”,”two”,”three”:
Hashtable numbers = new Hashtable();
numbers.put(“one”, new Integer(1));
numbers.put(“two”, new Integer(2));
numbers.put(“three”, new Integer(3));
要取出一個數,比如2,用相應的key:
Integer n = (Integer)numbers.get(“two”);
System.out.println(“two = ” + n);
由於作為key的對象將通過計算其散列函數來確定與之對應的value的位置,因此任何作為key的對象都必須實現hashCode和equals方法。hashCode和equals方法繼承自根類Object,如果你用自定義的類當作key的話,要相當小心,按照散列函數的定義,如果兩個對象相同,即obj1.equals(obj2)=true,則它們的hashCode必須相同,但如果兩個對象不同,則它們的hashCode不一定不同,如果兩個不同對象的hashCode相同,這種現象稱為沖突,沖突會導致操作哈希表的時間開銷增大,所以盡量定義好的hashCode()方法,能加快哈希表的操作。
如果相同的對象有不同的hashCode,對哈希表的操作會出現意想不到的結果(期待的get方法返回null),要避免這種問題,只需要牢記一條:要同時復寫equals方法和hashCode方法,而不要只寫其中一個。
Hashtable是同步的。
HashMap類
HashMap和Hashtable類似,不同之處在於HashMap是非同步的,並且允許null,即null value和null key。,但是將HashMap視為Collection時(values()方法可返回Collection),其迭代子操作時間開銷和HashMap的容量成比例。因此,如果迭代操作的性能相當重要的話,不要將HashMap的初始化容量設得過高,或者load factor過低。
WeakHashMap類
WeakHashMap是一種改進的HashMap,它對key實行“弱引用”,如果一個key不再被外部所引用,那麼該key可以被GC回收。
總結
如果涉及到堆棧,隊列等操作,應該考慮用List,對於需要快速插入,刪除元素,應該使用LinkedList,如果需要快速隨機訪問元素,應該使用ArrayList。
如果程序在單線程環境中,或者訪問僅僅在一個線程中進行,考慮非同步的類,其效率較高,如果多個線程可能同時操作一個類,應該使用同步的類。
要特別注意對哈希表的操作,作為key的對象要正確復寫equals和hashCode方法。
盡量返回接口而非實際的類型,如返回List而非ArrayList,這樣如果以後需要將ArrayList