雖然文章的標題是詞法分析,但首先還是要從編譯原理說開來。編譯原理應該很多人都聽說過,雖然不一定會有多麼了解。
簡單的說,編譯原理就是研究如何進行編譯——也就如何從代碼(*.cs 文件)轉換為計算機可以執行的程序(*.exe 文件)。當然也有些語言如 JavaScript 是解釋執行的,它的代碼是直接被執行的,不需要生成可執行程序。
編譯過程是很復雜的,它涉及到很多步驟,直接拿《編譯原理》(Compilers: Principles, Techniques and Tools,紅龍書)上的圖來看:
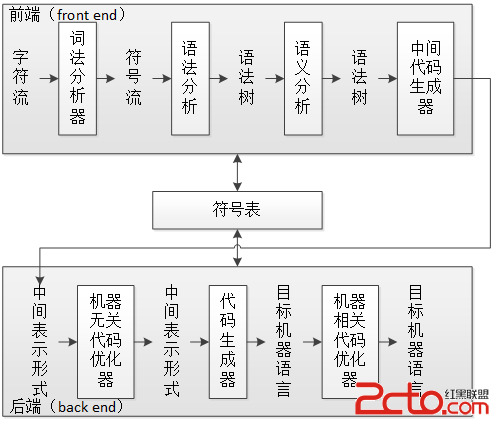
圖 1 編譯器的各個步驟,其實是我根據書上的圖綜合了一下後畫的
這裡給出了 7 個步驟(後面的優化步驟是可選的),其中前 4 個步驟是分析部分(也被稱為前端 front end),是把源程序分解為多個組成要素,並在這些要素上加上語法結構,最後把信息存放在符號表(symbol table)中。後三個步驟是綜合部分(也成為後端 back end),它們根據中間表示和符號表中的信息構造期待的目標程序。
將編譯器分為這麼多步驟,其好處就是使得每個步驟更加簡單,從而使編譯器更加容易設計,也可以利用很多現有的工具——例如詞法分析器可以用 Lex 或 Flex 生成,語法分析器可以用 Yacc 或 Bison 生成,幾乎不用做太多編碼工作就能得到一顆語法樹,前端的工作也就完成的差不多了。而至於後端,也有很多現有的技術可以使用,例如現成的虛擬機(CLR 或 Java,只要翻譯成相應的 IL 就可以了)。
這個系列的文章,說的就是編譯原理的第一步:語法分析。大部分算法和理論都來自《編譯原理》,其余的部分則是自己搞出來的,或者是參考了 Flex 的實現(這裡的 Flex 是指 fast lexical analyzer generator,一種著名的提供詞法分析的程序,而不是 Adobe 的 Flex)。
我會盡量完整的介紹詞法分析器的編寫過程,包括一些細節的實現。當然,目前只能根據正則表達式定義得到一個可以用來進行詞法分析的對象,要想達到 Flex 那樣直接根據詞法定義文件生成詞法分析器源代碼,還有很多工作要做,不是短期內能夠搞定的。
本篇文章作為系列的第一篇,將會對詞法分析做綜合的概述,介紹一下其中用到的技術和大致的流程。
一、詞法分析介紹
詞法分析(lexical analysis)或掃描(scanning)是編譯器的第一個步驟。詞法分析器讀入組成源程序的字符流,並且將它們組織成有意義的詞素(lexeme)的序列,並對每個詞素產生詞法單元(token)作為輸出。
簡單的來說,詞法分析就是將源程序(可以認為是一個很長的字符串)讀進來,並且“切”成小段(每一段就是一個詞法單元 token),每個單元都是有具體的意義的,例如表示某個特定的關鍵詞,或者代表一個數字。而這個詞法單元在源程序中對應的文本,就叫做“詞素”。
以計算器來舉例,12+34*9 這一段“源程序”的詞法分析過程如下所示:
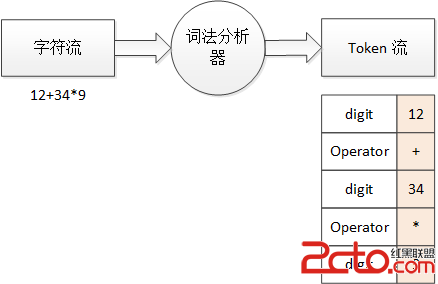
圖 2 算式的詞法分析過程
一段對計算機來說豪無意義的字符串,經過語法分析後就得到了略微有意義的 Token 流。digit 就表示這個詞法單元對應的是數字,operator 則表示操作符,後面相應的數字和符號(粉色背景)就是詞素。同時,程序中一些不必要的空白、注釋也可以由詞法分析器來過濾掉,這樣,之後的語法分析等步驟處理起來就會容易得多。
在實際的程序中,詞法單元都會以枚舉或數字來表示這是哪一類詞法單元。我的 Token.cs 定義如下所示:
1 namespace Cyjb.Text {
2 struct Token {
3 // 詞法單元的符號索引,表示詞法單元的類型。
4 int Index;
5 // 詞法單元的文本,即“詞素”。
6 string Text;
7 // 獲取詞法單元的起始位置。
8 SourceLocation Start;
9 // 獲取詞法單元的結束位置。
10 SourceLocation End;
11 // 獲取詞法單元的值。
12 object Value;
13 }
14 }裡面的 Index 和 Text 屬性不必多做解釋,Start 和 End 是用來在源文件中定位的(索引,行數和列數),Value 則僅僅是為了方便傳遞一些值而設。
二、如何描述詞素
現在知道了詞法分析可以將詞素分割開來,那麼詞素是怎麼描述的?或者說,為什麼 12、+ 和 34 都是詞素,而 1、 2+3 和 4 就不是詞素呢?這就需要用到模式了。
模式(pattern)描述了一個詞法單元的詞素可能具有的形式。
也就是說,我定義了 digit 模式為“由一個或多個數字組成的序列”,和 operator 模式為“單個 + 或 * 字符”,詞法分析器就知道 12 是一個詞素,而 2+3 則不是詞素了。
現在,模式一般都是用正則表達式(regular expression)表示的,這裡所謂的正則表達式,與平常所說的正則表達式(例如 System.Text.RegularExpressions.Regex 類)形式完全相同,功能卻更有限,它只包含了字符串的匹配能力,而沒有分組、引用和替換的能力。簡單的舉個例子,a+ 這個正則表達式就表示“由一個或多個字符 a 組成的序列”。關於正則表達式更多詳細信息,我會在後面的文章中列出來,當然,有限的參考一下 System.Text.RegularExpressions.Regex 也是可以的。
在本系列之後的文章中所提的正則表達式,都指的是這種只具有字符串匹配能力的正則表達式,大家一定要注意不要與 System.Text.RegularExpressions.Regex 相混淆。