一、輸入緩沖
在介紹如何進行詞法分析之前,先來說說一個不怎麼被提及的問題——怎麼從源文件中讀取字符流。為什麼這個問題這麼重要呢?是因為在詞法分析中,對字符流是有要求的,它必須能夠支持回退操作(就是將多個字符放回到流中,以後會再次被讀取)。
先來解釋下為什麼需要支持回退操作,舉個簡單的例子來說,現在要對兩個模式進行匹配:

圖 1 流的回退過程
上面是一個簡單的匹配過程,僅為了展示回退過程,在後面實現 DFA 模擬器時會詳細解釋是如何匹配詞素的。
現在來看看 C# 中與輸入相關的類,有 Stream,它支持流的查找,但是只能以字節方式訪問;BinaryReader 和 TextReader 雖然支持讀取字符,但是又不能支持回退。所以,就必須自己完成這個輸入緩沖類了,大致思路就是以 TextReader 作為底層的字符輸入,然後由自己的類完成對回退能力的支持。
《編譯原理》上給出了一種緩沖區對的方法,簡單的說就是開辟兩個緩沖區,設緩沖區大小都是 N 個字符。每一次都將 N 個字符讀入到緩沖區中,並在這個緩沖區上實現字符操作。如果當前緩沖區的數據已經處理完畢,就將 N 個新字符讀入到另一個緩沖區中,接下來就換做操作新的緩沖區。
這樣的數據結構效率很高,而且只要維護合適的指針,就可以很容易的實現回退功能。不過它的緩沖區大小是固定的,新讀入的字符會覆蓋舊的字符。如果需要回退的字符數量過多(比如在分析很長的字符串時),就容易出現錯誤。我通過使用多個緩沖區解決了舊字符被覆蓋的問題——如果緩沖區不足了,就開辟新緩沖區,而不是覆蓋舊數據。
如果僅僅是不斷的添加緩沖區,那麼占用的內存只會不斷增加,這樣是沒有什麼意義的,因此我定義了三個釋放緩沖區的操作:Drop,Accept 和 AcceptToken。Drop 的作用是將當前位置之前的所有數據標記為無效(被拋棄),被標記無效的數據占用的緩沖區就被釋放掉,可以拿來被重復利用了;Accept 則會將標記為無效的數據以字符串形式返回,而不僅僅是簡單的拋棄;類似的,AcceptToken 是以 Token 形式返回被無效化的數據,是為了方便進行詞法分析。
這樣的數據結構比較類似於 STL 中的 deque,不過這裡不需要隨機訪問和插入、刪除數據,僅會在數據的頭、尾進行操作,因此我直接將多個緩沖區使用雙向鏈表連成一個環,使用三個指針 current,first 和 last 指向鏈表中有數據的緩沖區,如下圖所示:
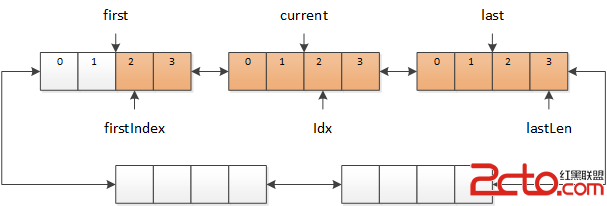
圖 2 多個緩沖區組成的鏈表,紅色的部分表示有數據,白色的部分沒有數據
其中,first 指向的是最早的數據緩沖區,last 指向的是最新的數據緩沖區,current 指向的是當前正在訪問的數據緩沖區,current 總是在 [first, last] 范圍之內。firstIndex 和 lastLen 之間紅色的部分,就是包含有效數據的緩沖區,idx 表示當前正在訪問的字符。白色的部分表示空緩沖區,或是緩沖區中的數據已無效。
當需要讀取下一個字符時,就從 current 中依次讀取數據,並將 idx 後移。如果 current 中的數據已經讀取完畢,則將 current 移向 last(這裡用移向,是因為 current 和 last 之間可能有多個緩沖區),同時 idx 也要相應的移動。
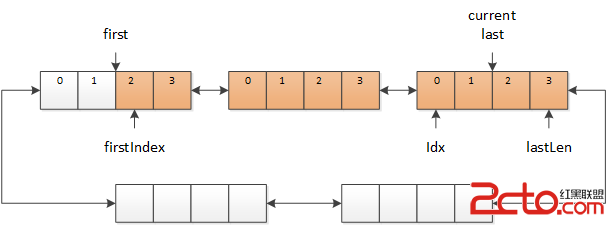
圖 3 current 移向 last
如果需要繼續讀取字符,但是 current 中沒有新數據了,而此時 current 已經與 last 相同,表示緩沖區中已經沒有更新的數據,那麼就需要從 TextReader 中讀取數據,放到新的緩沖區中,同時後移 current 和 last(需要保證 last 總是指向最新的緩沖區)。
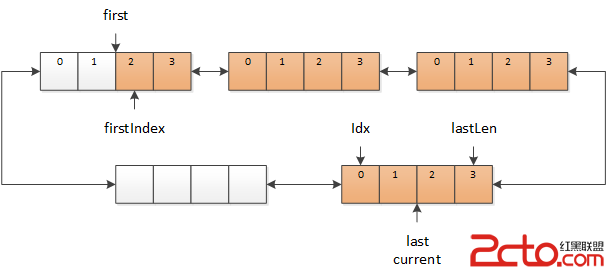
圖 4 current 和 last 向後移
現在來看看回退操作。進行回退時,只需要將 current 向 first 的方向移動(同樣,current 和 first 之間可能有多個緩沖區)。
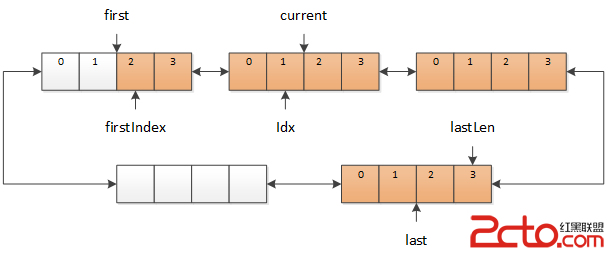
圖 5 回退操作
Drop 操作(Accept 和 AcceptToken 也同理)的實現也很簡單,只需要將 first 移動到 current 位置,將 firstIndex 移動到 idx 即可,這就表示 idx 之前的數據都看作無效數據。
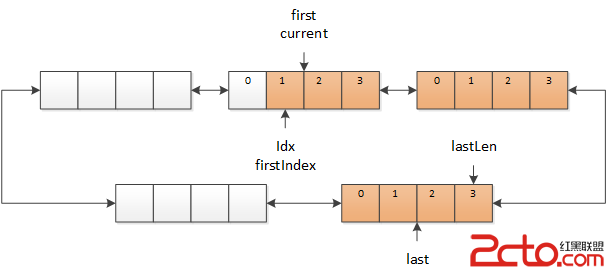
圖 6 Drop 操作
這裡需要注意的就是,Drop 操作完成後,被無效化的數據就有可能會被新數據覆蓋,因此應該確定數據不再需要時再執行 Drop 操作。Drop 操作的效率很高(移動兩個引用),基本不用擔心會影響效率。
使用這種環形數據結構的優點是除了將字符填充到緩沖區之外,完全避免了數據的額外復制,無論是前進、回退還是 Drop 操作都只有指針(引用)操作,效率很高。當 Drop 比較及時時,僅會使用兩個緩沖區,不會額外的占用內存。當占用的緩沖區過多時,還能夠實現主動釋放多余的內存(這裡現在沒有考慮)。
缺點就是實現起來會復雜些,需要仔細處理好 first、current 和 last 的關系,以及 firstIndex、index 和 lastLen 范圍限制,有時還會涉及到多個緩沖區的操作。
完整的代碼可見 SourceReader.cs。