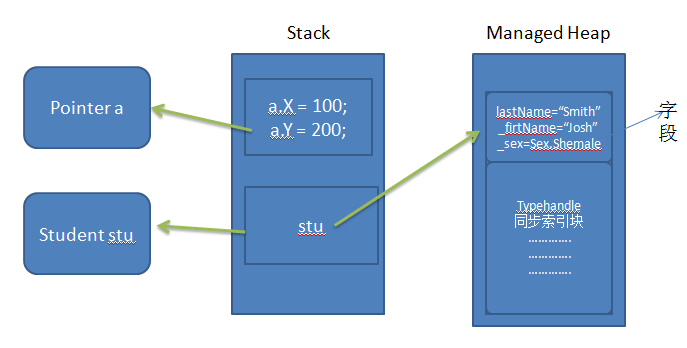
關於string的效率,眾所周知的恐怕是“+”和StringBuilder了,這些本文就不在贅述了。關於本文,請先回答以下問題(假設都是基於多次循環反復調用的情況下):
1.使用Insert與Format方法,哪個效率更高?
2.Contains(value)與IndexOf(value)誰效率更高?
假如您對此2問不感興趣或已非常了解,請忽略此文。另外本文將不對文中代碼的實際用途做任何解釋。
str1 = str2 = = .Format(= str1.Insert(, str2);
WriteTime( title,
再添加一個方法對字符串進行循環操作
LoopCalc(Action<, >[] array = [ ( i = ; i < array.Length; i++= i.ToString()= ( i = ; i < array.Length; i++
添加對string進行Insert與Format的效率對比代碼並在Main方法中調用
inserTime = LoopCalc((x, y) => x.Insert( formatTime = LoopCalc((x, y) => .Format(
運行結果如下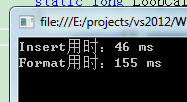
明顯看到Insert效率更高,但是這種結果有局限性,如果字符串很長,那麼經過我親測他們效率相差無幾。
注:我這個只是將Format用於字符串拼接的場景,更高的效率應該仍然是StringBuilder,當然Format的其他不可替代用途太多了,Insert和StringBuilder根本無法替代它,這裡就不羅嗦了。
str1 = str2 = (str1.IndexOf(str2) > -) { }
在這裡仍然使用了上述的LoopCalc方法,並增加如下方法,然後在Main方法中調用其
indexOfTime = LoopCalc((x, y) => { (x.IndexOf(y) >= containersTime = LoopCalc((x, y) => {
結果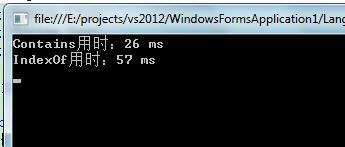
顯然Contains效率更高,為什麼呢?我之前也不懂為什麼,現在來看下String類的源碼(關於.NET自帶類庫的源碼可以谷歌搜到官方的下載地址,我忘了地址了),代碼很多,我就貼出以下string類中的方法給各位看官
CultureInfo.CurrentCulture.CompareInfo.IndexOf( IndexOf(String value, CultureInfo.CurrentCulture.CompareInfo.IndexOf(
Contains( ( IndexOf(value, StringComparison.Ordinal) >=
以下是有關Contains調用的IndexOf的重載
IndexOf(value, , IndexOf(String value, IndexOf(value, startIndex, .Length - IndexOf(String value, startIndex,
(value == ArgumentNullException( (startIndex < || startIndex > ArgumentOutOfRangeException(, Environment.GetResourceString( (count < || startIndex > .Length - ArgumentOutOfRangeException(,Environment.GetResourceString( CultureInfo.CurrentCulture.CompareInfo.IndexOf( CultureInfo.CurrentCulture.CompareInfo.IndexOf( CultureInfo.InvariantCulture.CompareInfo.IndexOf( CultureInfo.InvariantCulture.CompareInfo.IndexOf( CultureInfo.InvariantCulture.CompareInfo.IndexOf( TextInfo.IndexOfStringOrdinalIgnoreCase( ArgumentException(Environment.GetResourceString(),
結論差不多出來了吧,不過這裡還牽扯到另一個類CultureInfo.InvariantCulture.CompareInfo,我也看過該類的代碼,裡頭有unsafe代碼,不在本文范疇,但是有個結論就是當把我的Demo裡的代碼的IndexOf改為“x.IndexOf(y, StringComparison.Ordinal)”,那麼他們倆的相率將相差無二。
string其本身就是char數組的封裝,其或多或少體現著Array的一些特點,那麼接下來再來看看在List集合中的關於Contains與IndexOf的情況。

運行結果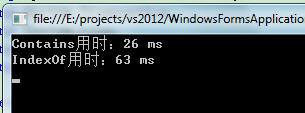
很顯然在判斷是否包含時,我們應該堅定不移的使用Contains。
總結:
1.這點效率問題對於某些人來說可能無所謂,但是我覺得更重要的是編碼習慣的養成問題。
2.能用Contains的地方還是盡量使用Contains(發現我改的代碼中有不少同事直接用了"IndexOf(value)"),當然會有特殊的例外場景,這裡不羅嗦。
3.關於Insert,我編寫了兩個擴展方法,如下(方法雖簡單,但是給代碼帶來了更大的優雅性)
InsertLast( source, InsertFirst( source, source.Insert(