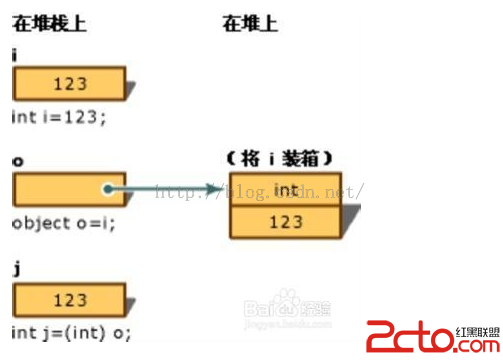
c#完成metro文件緊縮解壓示例。本站提示廣大學習愛好者:(c#完成metro文件緊縮解壓示例)文章只能為提供參考,不一定能成為您想要的結果。以下是c#完成metro文件緊縮解壓示例正文
在1.zip中增長一張新圖片
StorageFile jpg = await KnownFolders.PicturesLibrary.GetFileAsync("1.jpg");
StorageFile zip = await KnownFolders.PicturesLibrary.GetFileAsync("1.zip");
//把下面這句改成以下就成了緊縮文件
//StorageFile zip = await KnownFolders.PicturesLibrary.CreateFileAsync(jpg.DisplayName+".zip",CreationCollisionOption.WordStrExisting);
using (ZipArchive archive = new ZipArchive((await zip.OpenAsync(FileAccessMode.ReadWrite)).AsStream(), ZipArchiveMode.Update))
{
ZipArchiveEntry readmeEntry = archive.CreateEntry(jpg.Name);
byte[] buffer = WindowsRuntimeBufferExtensions.ToArray(await FileIO.ReadBufferAsync(jpg));
using (var writer = readmeEntry.Open())
{
await writer.WriteAsync(buffer, 0, buffer.Length);
}
}
把1.jpg從1.zip中刪除
StorageFile zip = await KnownFolders.PicturesLibrary.GetFileAsync("1.zip");
using (ZipArchive archive = new ZipArchive((await zip.OpenAsync(FileAccessMode.ReadWrite)).AsStream(), ZipArchiveMode.Update))
{
//刪除文件
archive.GetEntry("1.jpg").Delete();
}
導出1.jpg,newFile為要到出的文件
StorageFile zip = await KnownFolders.PicturesLibrary.GetFileAsync("1.zip");
using (ZipArchive archive = new ZipArchive((await zip.OpenAsync(FileAccessMode.ReadWrite)).AsStream(), ZipArchiveMode.Update))
{
ZipArchiveEntry zipArchiveEntry = archive.GetEntry("1.jpg").
using (Stream fileData = zipArchiveEntry.Open())
{
StorageFile newFile = await KnownFolders.PicturesLibrary.CreateFileAsync(zipArchiveEntry.FullName, CreationCollisionOption.WordStrExisting);
using (IRandomAccessStream newFileStream = await newFile.OpenAsync(FileAccessMode.ReadWrite))
{
using (Stream s = newFileStream.AsStreamForWrite())
{
await fileData.CopyToAsync(s);
await s.FlushAsync();
}
}
}
}
起首,看一下SparseArray的結構函數:
/**
* Creates a new SparseArray containing no mappings.
*/
public SparseArray() {
this(10);
}
/**
* Creates a new SparseArray containing no mappings that will not
* require any additional memory allocation to store the specified
* number of mappings. If you supply an initial capacity of 0, the
* sparse array will be initialized with a light-weight representation
* not requiring any additional array allocations.
*/
public SparseArray(int initialCapacity) {
if (initialCapacity == 0) {
mKeys = ContainerHelpers.EMPTY_INTS;
mValues = ContainerHelpers.EMPTY_OBJECTS;
} else {
initialCapacity = ArrayUtils.idealIntArraySize(initialCapacity);
mKeys = new int[initialCapacity];
mValues = new Object[initialCapacity];
}
mSize = 0;
}
從結構辦法可以看出,這裡也是事後設置了容器的年夜小,默許年夜小為10。
再來看一下添加數據操作:
/**
* Adds a mapping from the specified key to the specified value,
* replacing the previous mapping from the specified key if there
* was one.
*/
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
mValues[i] = value;
} else {
i = ~i;
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
if (mSize >= mKeys.length) {
int n = ArrayUtils.idealIntArraySize(mSize + 1);
int[] nkeys = new int[n];
Object[] nvalues = new Object[n];
// Log.e("SparseArray", "grow " + mKeys.length + " to " + n);
System.arraycopy(mKeys, 0, nkeys, 0, mKeys.length);
System.arraycopy(mValues, 0, nvalues, 0, mValues.length);
mKeys = nkeys;
mValues = nvalues;
}
if (mSize - i != 0) {
// Log.e("SparseArray", "move " + (mSize - i));
System.arraycopy(mKeys, i, mKeys, i + 1, mSize - i);
System.arraycopy(mValues, i, mValues, i + 1, mSize - i);
}
mKeys[i] = key;
mValues[i] = value;
mSize++;
}
}
再看查數據的辦法:
/**
* Gets the Object mapped from the specified key, or <code>null</code>
* if no such mapping has been made.
*/
public E get(int key) {
return get(key, null);
}
/**
* Gets the Object mapped from the specified key, or the specified Object
* if no such mapping has been made.
*/
@SuppressWarnings("unchecked")
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
return (E) mValues[i];
}
}
可以看到,在put數據和get數據的進程中,都同一挪用了一個二分查找算法,其實這也就是SparseArray可以或許晉升效力的焦點。
static int binarySearch(int[] array, int size, int value) {
int lo = 0;
int hi = size - 1;
while (lo <= hi) {
final int mid = (lo + hi) >>> 1;
final int midVal = array[mid];
if (midVal < value) {
lo = mid + 1;
} else if (midVal > value) {
hi = mid - 1;
} else {
return mid; // value found
}
}
return ~lo; // value not present
}
小我以為(lo + hi) >>> 1的辦法有些奇異,直接用 lo + (hi - lo) / 2更好一些。