正則表達式是一種描述詞素的重要表示方法。雖然正則表達式並不能表達出所有可能的模式(例如“由等數量的 a 和 b 組成的字符串”),但是它可以非常高效的描述處理詞法單元時要用到的模式類型。
一、正則表達式的定義
正則表達式可以由較小的正則表達式按照規則遞歸地構建。每個正則表達式 r 表示一個語言 L(r),而語言可以認為是一個字符串的集合。正則表達式有以下兩個基本要素:
是一個正則表達式, L()=,即該語言只包含空串(長度為 0 的字符串)。
如果 a 是一個字符,那麼 a 是一個正則表達式,並且 L(a)={a},即該語言只包含一個長度為 1 的字符串 a。
由小的正則表達式構造較大的正則表達式的步驟有以下四個部分。假定 r 和 s 都是正則表達式,分別表示語言 L(r) 和 L(s),那麼:
(r)|(s) 是一個正則表達式,表示語言 L(r)∪L(s),即屬於 L(r) 的字符串和屬於 L(s) 的字符串的集合( L(r)∪L(s)={s|s∈L(r) or s∈L(s)})。
(r)(s) 是一個正則表達式,表示語言 L(r)L(s),即從 L(r) 中任取一個字符串,再從 L(s) 中任取一個字符串,然後將它們連接後得到的所有字符串的集合( L(r)L(s)={st|s∈L(r) and t∈L(s)})。
(r) 是一個正則表達式,表示語言 L(r),即將 L(r) 連接 0 次或多次後得到的語言。
(r) 是一個正則表達式,表示語言 L(r)。
上面這些規則都是由 Kleene 在 20 世紀 50 年代提出的,在之後有出現了很多針對正則表達式的擴展,他們被用來增強正則表達式表述字符串模式的能力。這裡采用是類似 Flex 的正則表達式擴展,風格則類似於 .Net 內置的正則表達式:

這裡與字符類和 Unicode 通用類別相關的知識請參考 C# 的正則表達式語言 - 快速參考中的“字符類”小節。大部分的正則表達式表示方法也與 C# 中的相同,有所不同的向前看(r/s)、上下文(<s>r)和文件結尾(<<EOF>>)會在之後的文章中解釋。
利用上面的表格中列出擴展正則表達式,就可以比較方便的定義需要的模式了。不過有些需要注意的地方:
這裡的定義不支持 POSIX Style 的字符類,例如 [:alnum:] 之類的,與 Flex 不同。
$ 匹配行尾,即可以匹配 \n 也可以匹配 \r\n,也與 Flex 不同。
字符集的相減是 C# 風格的 [a-z-[b-f]],而不是 Flex 那樣的 [a-c]{-}[b-z]。
向前看中的 $ 只表示 '$',而不再匹配行尾,例如 a/b$ 僅當 "a" 後面是 "b$" 時才匹配 "a"。
二、正則表達式的表示
雖然上面定義了正則表達式的規則,但它們表示起來卻很簡單,我使用 Cyjb.Compilers.RegularExpressions 命名空間下的 8 個類來表示任意的正則表達式,其類圖如下所示:
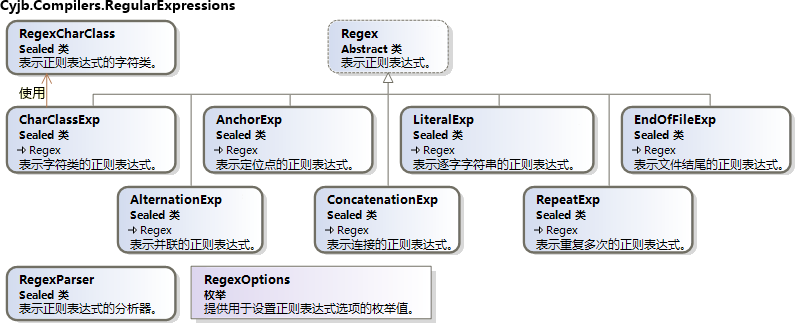
圖 1 正則表達式類圖
其中,Regex 類是正則表達式的基類,CharClassExp 表示字符類(單個字符),LiteralExp 表示原義文本(多個字符組成的字符串),RepeatExp 表示正則表達式重復(可以重復上限至下限之間的任意次數),AlternationExp 表示正則表達式的並(r|s),ConcatenationExp 表示正則表達式的連接(rs),AnchorExp 表示行首限定、行尾限定和向前看,EndOfFileExp 表示文件的結尾(<<EOF>>)。
將 CharClassExp、LiteralExp、RepeatExp、AlternationExp、ConcatenationExp 這些類進行嵌套,就可以表示大部分正則表達式了;AnchorExp 單獨拿出來是因為它只能作為最外層的正則表達式,而不能位於其它正則表達式內部;EndOfFileExp 則是專門用於 <<EOF>> 的。這裡並未考慮上下文,因為上下文的處理並不在正則表達式這裡,而是在之後的“終結符符定義”部分。
正則表達式的表示比較簡單,但為了更加易用,有必要提供從字符串(例如 "abc[0-9]+")轉換為相應的正則表達式的轉換方法。RegexCharClass 類是System.Text.RegularExpressions.RegexCharClass 類的包裝,用於表示一個字符類,我對其中的某些函數進行了修改,以符合我這裡的正則表達式定義。RegexOptions 類和 RegexParser 類則是用於正則表達式解析的類,具體的解析算法太過復雜,就不多加解釋。
三、正則表達式
正則表達式構造好後,就需要使用它去匹配詞素。一個詞法分析器可能需要定義很多正則表達式,還可能包括上下文以及行首限定符,處理起來還是比較復雜的。為了簡便起見,我會首先討論怎麼用一條正則表達式去匹配字符串,在之後的文章中再討論如何用組合多條正則表達式去匹配詞素。
使用正則表達式匹配字符串,一般都會用到有窮自動機(finite automata)的表示方法。有窮自動機是識別器(recognizer),只能對每個可能的輸入回答“是”或“否”,表示時候與此自動機相匹配。或者說,不斷的讀入字符,直到有窮自動機回答“是”,此刻就正確的匹配了一個字符串。
有窮自動機分為兩類:
不確定的有窮自動機(Nondeterministic Finite Automata,NFA)對其邊上的標號沒有任何限制。一個符號標記離開同一狀態的多條邊,並且空串 也可以作為標號。
確定的有窮自動機(Deterministic Finite Automata,DFA)對於每個狀態及自動機輸入字母表中的每個符號有且只有一條離開該狀態、以該符號為標號的邊。
NFA 和 DFA 可以識別的語言集合是相同的(後面會說到 NFA 如何轉換為等價的 DFA),並且這些語言的集合正好是能夠用正則表達式描述的語言集合(正則表達式可以轉換為等價的 NFA)。因此,采用有窮自動機來識別正則表達式描述的語言,也是很自然的。
3.1 不確定的有窮自動機 NFA
一個不確定的有窮自動機(NFA)由以下幾個部分組成:
一個有窮的狀態集合 S。
一個輸入符號集合 Σ,即輸入字母表(input alphabet)。我們假設空串 不是 Σ 中的元素。
一個轉換函數(transition function),它為每個狀態和 Σ∪{} 的每個符號都給出了相應的後繼狀態(next state)的集合。
S 中的一個狀態 s0 被指定為開始狀態,或者說初始狀態。
S 的一個子集 F 被指定為接受狀態(或者說終止狀態)的集合。
下圖就是一個能識別正則表達式 (a|b)*baa 的語言的 NFA,邊上的字母就是該邊的標號。
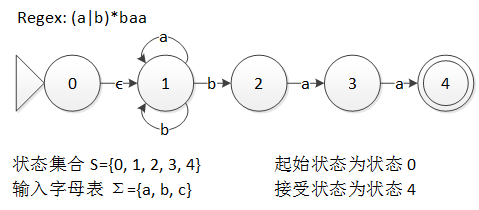
圖 2 NFA 實例
NFA 的匹配過程很直觀,從起始狀態開始,每讀入一個符號,NFA 就可以沿著這個符號對應的邊前進到下一個狀態( 邊不用讀入符號也可以前進,當然也可以不前進),就這樣不斷讀入符號,直到所有符號都讀入進來,如果最後到達的是接受狀態,那麼匹配成功,否則匹配失敗。
在狀態 1 上,有兩條標號為 b 的邊,一條指向狀態 1,一條指向狀態 2,這就使自動機產生了不確定性——當到達狀態 1 時,如果讀入的字符是 'b',那麼並不能確定應該轉移到狀態 1 還是 2,此時就需要使用集合保存所有可能的狀態,把它們都嘗試一遍才可以。
接下來嘗試用這個 NFA 去匹配字符串 "ababaa"。

查看本欄目
DFA 的匹配過程則更加簡單,因為沒有了 轉換和不確定的轉換,只要從起始狀態開始,每讀入一個符號,就直接沿著這個符號對應的邊前進到下一個狀態(這個狀態是唯一的),就這樣不斷讀入符號,直到所有符號都讀入進來,如果最後到達的是接受狀態,那麼匹配成功,否則匹配失敗。
接下來嘗試用這個 DFA 去匹配字符串 "ababaa"。
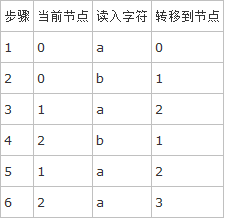
此時字符串已經全部讀入,最後到達了狀態 3,是一個接受狀態,因此 DFA 返回結果“是”。
使用 DFA 進行模式匹配的時間復雜度是 O(k),其中 k 為要匹配的字符串的長度,可見,DFA 的效率只與輸入字符串的長度有關,效率非常高。
3.3 為什麼使用 DFA
上面介紹的 NFA 和 DFA 識別語言的能力是相同的,但在詞法分析中實際使用的都是 DFA,是有下面幾種原因。
NFA 的匹配效率比不過 DFA 的,詞法分析器顯然運行的越快越好。
雖然 DFA 的構造則要花費很長時間,一般是 O(r3),最壞情況下可能會是 O(r22r),但在詞法分析器這一特定領域中,DFA 只需要構造一次,就可以多次使用,而且 Flex 可以在生成源代碼的時候就構造好 DFA,耗點時間也沒有關系。
DFA 在最壞情況下可能會使狀態個數呈指數增長,《編譯原理》上給出了一個例子 (a|b)a(a|b)n1,識別這個正則表達式的 NFA 具有 n+1 個狀態,而 DFA 卻至少有 2n 個狀態,不過這麼特殊的情況在編程語言中基本不會見到,不用擔心這一點。
不過 NFA 還是有用的,因為 DFA 要利用 NFA,通過子集構造法得到;將正則表達式轉換為 NFA,也有助於理解如何處理多條正則表達式和處理向前看。下一篇文章就開始介紹 NFA 的表示以及如何將正則表達式轉換為 NFA。
作者:CYJB
出處:http://www.cnblogs.com/cyjb/