只有深究最本質的東西,才能把握最本質的東西。
有很多朋友都分析過System.Object作為Dotnet Framework裡面的一個基類,她的特性、方法特點及其相關的概念,這篇博文裡面,我就從System.Object這個基類的定義以及底層實現的角度,探索這個基類對象在內存裡面的布局模型,探索這個基類最本質的面目。
首先,從一個Type的實例在內存裡面的布局模型、以及一個實例的各個部分在一個托管進程結構裡面對應安排到相應的哪個部分說起。
下面是一個簡單的實例結構示意圖以及邏輯結構圖:
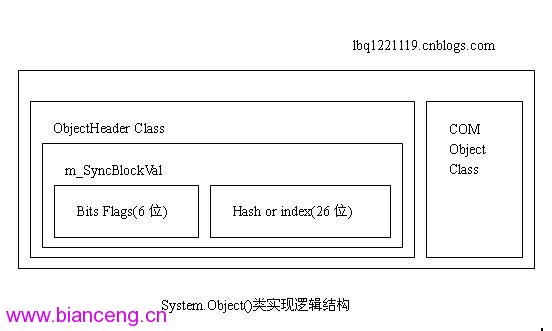
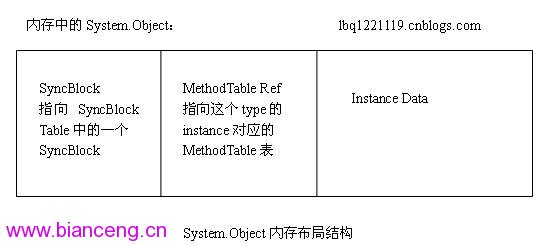
通常所說的對一個Object的引用,實際上這個Object的Ref是指向GC Heap或者是Thread的Heap裡面的這個實例的Object Header這部分。而Object Header顧名思義,只是定義部分,它指向的是一個type的MethodTable。每個類型對應著一個MethodTable保存在托管堆裡面。這部分的數據,它的存在是為了對一個type進行自描述。
而index指向的是一個叫做SynBlock table的表。每個Object都在這個表裡面有一個record。每個record就是我們有的時候可以看到的SyncBlock。保存了相關的一些CLR對這個對象的控制的信息。
我以前在研究這部分的時候,經常看到網上的一些同行們,在說明一個instance的結構的時候指出,一個object的結構,是m_SyncBlockValue後面緊接著MethodTable,然後緊接著Instance Data。需要指出的是,這個理解是將一個Object的邏輯結構和在內存裡面的物理結構的一些概念整到了一起,片面而不完整的。
實際上,一個Object的邏輯結構,是由由兩個部分組成的。就像上面的第一個圖表示的。一個叫做ObjHeader的類,然後就是Object的具體細節實現類。Object類在實現的時候,引用了很多COM+內部對象模型的結構概念。一個ObjHeader,主要包含了兩個部分:Bit Flags以及index這兩個東西。都包含在m_SyncBlockValue相關的定義裡面。
m_SyncBlockValue是一個DWORD類型的數據,4個字節。又叫做:the index and the Bits。裡面包含一個LONG的值當作index來用,還有剩下的作為某些特定功能的控制位來使用。在一個實例對象運行的時候,這些位的含義可以自動的被一些opcodes來獲取。
m_SyncBlockValue的高六位來標記m_SyncBlockValue的各種不同的功能和用途。m_SyncBlockValue的低26位來保存hash碼,或者是SyncBlock的index或者是SpinLock。具體的後26位是標識什麼東西,是由前面的6位裡面的相關字段來標識出來的。
在lock一個對象時,CLR首先將m_SyncBlockValue當做一個SpinLock使用。如果CLR在有限次的重試後無法獲得SpinLock的擁有權,CLR將SpinLock升級為一個AwareLock。AwareLock類似與Windows中的CriticalSection。
這裡需要特別說明一下為什麼這麼設計:
這樣設計的好處,在於把不同功能級別的操作或者是控制代碼分離開了。數據和控制代碼分離。對於這個instance的使用者來說,instance data是最為一個實例結構的最後一部分保存在GC Heap或者是Thread Heap裡面的。而對這個instance在運行的時候需要的數據或者是控制代碼,放在了MethodTable裡面,從ObjHeader可以獲得到操作一個instance的時候的這些數據或者代碼。而由於程序是運行在托管的環境下面的,為了支持一些CLR的特性,我們需要給這個instance一些CLR或者說是托管環境相關的屬性。這些東西,是作為SyncBlock Table裡面的一個表項保存在dotnet Framework執行引擎的內存空間裡面的。這樣,就實現了不同級別的數據的隔離。
我們知道,一個type的實例,也就是對象的分配,是在GC Heap上面進行分配的。一個instance和這個instance相關聯的type的相關的不同類型的數據類型,在不同的地方分配,並不是連續在一起分配的。譬如MethodTable,一些static字段,還有相關的Field或者是MethodDesc,這些東西並不是連續分配在一起的。CLR基於效率和性能上面的考慮,將它們放在了不同的地方。
如果看過我前面對應用程序域的介紹,就會知道,對於每個托管進程,都有一個或者幾個私有的AppDomian。MethodTable,就是分配在Private Appdomain的高頻堆上面(high-frequency heap),而MethodTable裡面的相關的項,FieldDescs、methodDescs是分配在低頻堆裡面的。而native Code,是放在JIT Heap裡面的。一個Object的相關數據的分布,並不是連續的,至少有5個或者是以上的Heap來存放這些數據的分布。
另外,SyncBlock也不是在GC Heap的,它更加特殊,是在CLR自己的私有地址空間裡面的。
下面,具體詳析的探索下這些結構的實現:
首先打開ObjHeader這個類的定義:
************************C++ Code*****************************
class ObjHeader
{
private:
// !!! Notice: m_SyncBlockValue *MUST* be the last field in ObjHeader.
DWORD m_SyncBlockValue; // the Index and the Bits
public:
// 訪問Sync Block表裡面的相關Syncblock的index。使用位操作來獲取。
DWORD GetHeaderSyncBlockIndex()
{
LEAF_CONTRACT;
// pull the value out before checking it to avoid race condition
DWORD value = m_SyncBlockValue;
//對於這一句含義的了解,可以通過對Bits的各個位的含義的獲取來了解。
if ((value & (BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX |
BIT_SBLK_IS_HASHCODE)) != BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX)
return 0;
return value & MASK_SYNCBLOCKINDEX;
}
//下面的這個方法演示的是在index裡面設置一個bit位的操作方法
void SetIndex(DWORD indx)
{
//注意,這裡定義的是一個LONG類型的變量,也就是前面說的m_SyncBlockValue裡面包含一個LONG類型的index
LONG newValue;
LONG oldValue;
while (TRUE) {
//獲取現有的LONG類型的index
oldValue = *(volatile LONG*)&m_SyncBlockValue;
//在以前的版本裡面,這句是沒有的,_ASSERTE具體用途沒找到,稍後探索
// Access to the Sync Block Index, by masking the Value.
_ASSERTE(GetHeaderSyncBlockIndex() == 0);
// or in the old value except any index that is there -
// note that indx
//could be carrying the BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX bit that we need to preserve
newValue = (indx |
(oldValue & ~(BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX |
BIT_SBLK_IS_HASHCODE | MASK_SYNCBLOCKINDEX)));
//這句主要是為了保證這些位不被隨便修改掉。
if (FastInterlockCompareExchange((LONG*)&m_SyncBlockValue,
newValue, oldValue)== oldValue)
{
return;
}
}
}
Object *GetBaseObject()
{
LEAF_CONTRACT;
return (Object *) (this + 1);
}
//省略了若干對index和bit位的操作方法
};
************************C++ Code end************************
在上面的代碼中,很多關於bits flag位的定義的不了解,會對這些代碼以及內部運行機制帶來困難。下面就解釋下一個m_SyncBlockValue裡面相關的BitFlags的含義:
在m_SyncBlockValue中,使用高位的bit來作為flags標志。在每次獲取或者是修改這些位的時候,都需要使用mask來獲取這些bits:
// These first three are only used on strings (If the first one is on, we know whether
// the string has high byte characters, and the second bit tells which way it is.
// Note that we are reusing the FINALIZER_RUN bit since strings don't have finalizers,
// so the value of this bit does not matter for strings
#define BIT_SBLK_STRING_HAS_NO_HIGH_CHARS 0x80000000
// Used as workaround for infinite loop case. Will set this bit in the sblk if we have already
// seen this sblk in our agile checking logic. Problem is seen when object 1 has a ref to object 2
// and object 2 has a ref to object 1. The agile checker will infinitely loop on these references.
#define BIT_SBLK_AGILE_IN_PROGRESS 0x80000000
#define BIT_SBLK_STRING_HIGH_CHARS_KNOWN 0x40000000
#define BIT_SBLK_STRING_HAS_SPECIAL_SORT 0xC0000000
#define BIT_SBLK_STRING_HIGH_CHAR_MASK 0xC0000000
#define BIT_SBLK_FINALIZER_RUN 0x40000000
#define BIT_SBLK_GC_RESERVE 0x20000000
// This lock is only taken when we need to modify the index value in m_SyncBlockValue.
// It should not be taken if the object already has a real syncblock index.
#define BIT_SBLK_SPIN_LOCK 0x10000000
#define BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX 0x08000000
// if BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX is clear,
the rest of the header dword is layed out as follows:
// - lower ten bits (bits 0 thru 9) is thread id used for the thin locks
// value is zero if no thread is holding the lock
// - following six bits (bits 10 thru 15) is recursion level used for the thin locks
// value is zero if lock is not taken or only taken once by the same thread
// - following 11 bits (bits 16 thru 26) is app domain index
// value is zero if no app domain index is set for the object
#define SBLK_MASK_LOCK_THREADID 0x000003FF
#define SBLK_MASK_LOCK_RECLEVEL 0x0000FC00
#define SBLK_LOCK_RECLEVEL_INC 0x00000400
#define SBLK_APPDOMAIN_SHIFT 16
#define SBLK_RECLEVEL_SHIFT 10
#define SBLK_MASK_APPDOMAININDEX 0x000007FF
// 如果 BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX 被設置了,並且,如果
BIT_SBLK_IS_HASHCODE 也被設置了, 剩下的dword就是hash Code (bits 0 to 25),
// otherwise the rest of the dword is the sync block index (bits 0 thru 25)
#define BIT_SBLK_IS_HASHCODE 0x04000000
#define MASK_HASHCODE ((1<<HASHCODE_BITS)-1)
#define SYNCBLOCKINDEX_BITS 26
#define MASK_SYNCBLOCKINDEX ((1<<SYNCBLOCKINDEX_BITS)-1)
// Spin for about 1000 cycles before waiting longer.
#define BIT_SBLK_SPIN_COUNT 1000
// The GC is highly dependent on SIZE_OF_OBJHEADER being exactly the sizeof(ObjHeader)
// We define this macro so that the preprocessor can calculate padding structures.
#define SIZEOF_OBJHEADER 4
可以從這些注釋裡面,可以看到每個字段的大概的用法。
接著,就說到了index裡面所指向的東西。也就是index指向的SyncBlock Table裡面的記錄。首先,m_SyncBlockValue記錄的是一個instance的額外的state。如果這個值是0,就說明沒有額外的狀態。如果它有一個非零的值,CLR就會自動把這個index和
g_pSyncTable裡面的SyncTableEntries這個屬性一一的對應起來。g_pSyncTable是一個全局的表,也可以說是數組,裡面存儲每個變量的SyncBlock。
大多數instance的指向SyncBlock的index都是0,和其它的Object一起,共享一個虛構的SyncBlock。SyncBlock的主要作用,是為了object的同步。每個對象的Hash()這個方法的實現,就是根據SyncTableEntry這個字段來實現的。同時,在一個Object(在上面的定義中,我們可以看到,一個Object在最底層的實現,是一個COM+的Object)與底層的COM+交互的過程中,這裡也可以存儲少量的額外的信息。
這裡,插入說一下一個SyncBlock與一個SyncTableEntry的區別。一個Object的m_SyncBlockValue裡面的index指向的是g_pSyncTable這個全局表(或者數組)裡面的一個記錄。這個記錄就叫做SyncBlock。而確定index和表裡面的哪一個SyncBlock的對應關系的就是每個SyncBlock裡面的SyncTableEntry的這個字段。
同時,SyncTableEntry和SyncBlock都是分配非GC回收內存裡面的,因為g_pSyncTable就是分配在非GC堆上面,也就是CLR的私有內存裡面的。然後,有一個弱類型的pointer指向每個instance的SyncTableEntry這個字段,用於這些對象的回收。
SyncTableEntries在以前版本的framework裡面還是以一個結構體的形式出現的,到了後來的版本,就2.0後來的版本,就改寫成了一個class:
class SyncTableEntry
{
public:
PTR_SyncBlock m_SyncBlock;
Object *m_Object;
static SyncTableEntry*& GetSyncTableEntry();
};
從上面可以看到,每個SyncTableEntry都包含了一個向前和向後的指針。向後退回到Object,向前指向SyncTableEntry對應的SyncBlock。
在GetSyncTableEntry()方法中,直接返回了g_pSyncTable:
SyncTableEntry*& SyncTableEntry::GetSyncTableEntry()
{
LEAF_CONTRACT;
return g_pSyncTable;
}
對於g_pSyncTable,實際上是一個叫做SyncBlockArray的數組。其定義如下
class SyncBlockArray
{
public:
SyncBlockArray *m_Next;
BYTE m_Blocks[MAXSYNCBLOCK * sizeof (SyncBlock)];
};
在上面的定義的過程中,使用m_Blocks[MAXSYNCBLOCK * sizeof (SyncBlock)]這句,可以保證在大多數只指定了SyncTableEntry而沒有指定值的情況下的性能。
OK,截止到這裡,對System.Object這個最基本的類,是如何來實現的,及其在內存裡面的布局,和針對這個布局程序上是如何實現的,有了一個較為深入的探索。
了解了這些東西,對於探索一個托管引用程序在運行時的特性,以及探索一個托管經常的運行時的內部機制的各個細節問題,都有了一個開山鋪路的先驅。
在接下來的2008,將繼續深入研究Dotnet最底層的核心運行機制,把這些鮮為人知的“那些事”,都展示出來,拋磚引玉,彌補一下國內大多數人只注重一些編程技巧和控件使用現狀的不足吧。
後記:
在後來的修改過程中,更正了幾個表達不准確的地方,同時加了兩個簡單的圖,希望有駐與文章的閱讀吧。