正則表達式獲取CSS裡面的圖片的例子,裡面有URL裡面的圖片地址有雙引號,要注意用兩個雙引號表示
其中如果包含的字符串中包含雙引號,那麼就兩個雙引號表示,而不是反斜槓加上雙引號(”),也不是斜槓加上雙引號(/”)
正則表達式獲取CSS裡面的圖片的例子,裡面有URL裡面的圖片地址有雙引號,要注意用兩個雙引號""表示
?
1 2 3 4 5 6 7 static void Main(string[] args) { Regex reg = new Regex(@"url((['""]?)(.+[^'""])1)"); //注意裡面的引號 要用雙引號表示,而不是用反斜槓 Console.WriteLine(reg.Match(@"{background-image:url(//ssl.gstatic.com/ui/v1/menu/checkmark.png);backgro")); //輸出 url(//ssl.gstatic.com/ui/v1/menu/checkmark.png) Console.ReadKey(); } 帶組名的後向引用在C#中是 k
?
1 2 3 4 5 6 7 8 static void Main(string[] args) { Regex reg = new Regex(@"b(?<group>w+ +)k<group>"); string str = "what the hell are you you talking about?"; Console.WriteLine(reg.Match(str)); Console.ReadKey(); }在C#中new一個Regex對象的時候,第二個參數能夠用枚舉支持選擇匹配模式,現在就來說說這些枚舉值對正則的影響。
模式 說明
.SingleLine 點號能夠匹配任何字符
.Multiline 擴展^和$的匹配,使^和$能夠匹配字符串內部的換行符
.IgnorePatternWhitespace 設計寬松排列和注釋模式
.IgnoreCase 進行不區分大小寫的匹配
.ECMAScript 限制w s d,令其只對ASCII字符有效
.RightToLeft 傳動裝置的驅動過程不變,但是方向相反(從字符的末尾開始,向開頭移動)
.Compiled 多花些時間優化正則表達式,編譯到dll裡,占用多點內存,但是匹配更快。
.ExplicitCapture 普通括號()在正常情況下是捕獲型括號,但是在此模式下與(?:...)一樣,之分組,不捕獲
RegexOptions.Compiled的意義
使用RegexOptions.Compiled與不使用RegexOptions.Compiled的對比
標准 不使用 使用
啟動速度 較快 較慢(最多60倍)
內存占用 少 多(每個正則表達式占用5-15KB)
匹配速度 一般 最多能提升10倍
在使用了RegexOptons.Compiled時,在程序執行過程中,這塊內存會一直被占用,無法被釋放,因此僅對於那些經常被使用的正則表達式才適合使用此選項。
ECMAScript模式
要注意ECMAScript只能與下面的選項同時使用
RegexOptons.IgnoreCase
RegexOptons.Multiline
RegexOptons.Compiled
而且反斜線-數字不會有反向引用和十進制轉移的二義性,因為它只能夠表示反向引用。例如 10 表示反向引用 1 然後是文字0。如果沒有啟用該模式,則 12 匹配的是ASCII進紙符linefeed。同時w d s W D S只能匹配ASCII。
另外在C#中,分組的編號也需要注意。
分組0是整個正則表達式匹配到的結果。
然後依次是未命名分組。
最後是命名分組。
例如:
(w)(?
1 3 2
特殊的Replacement處理
Regex.Replace方法和Match.Result方法都可以接收能夠進行特殊處理的replacement字符串。下面的字符序列會被匹配到的文本所替換:
字符序列 替換內容
$& 整個表達式匹配的文本,相當於$0
$1 $2 對應編號的捕獲分組所匹配的文本
${name} 對應命名捕獲分組匹配的文本
$‘ 目標字符串中匹配文本之前的文本
$' 目標字符串中匹配文本之後的文本
$$ 單個$字符($1的顯示為$$!)
$_ 正則原始目標字符串的副本
$+ .NET中表示最後的那個捕獲型括號匹配的文本
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 static void Main(string[] args) { Regex reg1 = new Regex(@"d+"); string str = reg1.Replace("123","insert into table where id = $&"); Console.WriteLine(str); //輸出 insert into table where id = 123 Regex reg2 = new Regex(@"1+1=(d)"); string str2 = reg2.Replace("1+1=3","不是$1"); Console.WriteLine(str2); //輸出 不是3 Regex reg3 = new Regex(@"1+1=(?<result>d)"); string str3 = reg3.Replace("1+1=3", "不是${result}"); Console.WriteLine(str3); //輸出 不是3 Regex reg4 = new Regex(@"d+"); string str4 = reg4.Replace("123ABC", "後面是$'"); //匹配文本之後的文本 Console.WriteLine(str4); //輸出 後面是ABCABC 為什麼會輸出 後面是ABCABC呢?因為$'指的是ABC,然後替換掉原字符串中的123。不懂看多幾次這句話 Regex reg5 = new Regex(@"d+"); string str5 = reg5.Replace("ABC123", "前面是$`"); //ABC前面是ABC 符號是 1左邊那個 Console.WriteLine(str5); Regex reg6 = new Regex(@"d+"); string str6 = reg6.Replace("ABC123","右邊原始輸入字符串$_"); Console.WriteLine(str6); //輸出 右邊是原始字符串ABC123 Console.ReadKey(); }關於.net中的正則裝配件是用於構建正則表達式庫的,保存在硬盤中,其他程序也能夠調用,提高重用率。主要就是用到了Regex類的CompileToAssembly方法。
今天,碰到一個非常有趣的問題,公司多了個客戶,產品那邊說添加關鍵詞太辛苦,讓我幫忙批量導入一批關鍵詞。哥這幾天正好在研究正則表達式呢,於是二話不說,立馬應了下來。一看,Excel,算了NPOI還沒學呢。於是復制到txt文本裡。
格式如下:
中山大道
粵墾路
.....
天助我也,難度不大,而且看來這幾天學的東西有用武之地了。於是立馬有了以下代碼
?
1 2 3 4 5 6 7 8 9 static void Main(string[] args) { string str = File.ReadAllText(@"D:daoru.txt", Encoding.Default); Regex reg = new Regex(@".+"); string str1 = reg.Replace(str, "insert into Keyword values(196,'admin1','admin1','$&')"); File.WriteAllText(@"D:123.txt", str1); Console.ReadKey(); }這是一個根據關鍵詞生成SQL語句的方法,從D盤導入txt文本(在這個地方,碰到一個問題,因為關鍵詞是中文,所以直覺上覺得應該用Utf-8編碼去讀,但是竟然出錯了。於是上網查了一下,居然用Encoding.Default可以解決這個問題)。然後用正則表達式匹配到關鍵詞。默認的new Regex() 點號.是不會匹配換行符的,因此非常適合關鍵詞一行一個的,例如從Excel復制過來的時候。然後用Regex類提供的Replace將關鍵詞替換成Sql語句,直接黏貼到數據庫上全選,執行。OK。一次過導入了近500個關鍵詞。
本來以為正則表達式學得不錯了,結果昨天替換的SQL語句就出了問題,存入數據庫的數據無緣無故多了個換行符。其實在執行SQL語句的時候,SQLSERVER已經很盡職地給出提示了,可惜太大意或者說高興得太早直接忽略了。來看昨天SQL語句執行時的圖片:
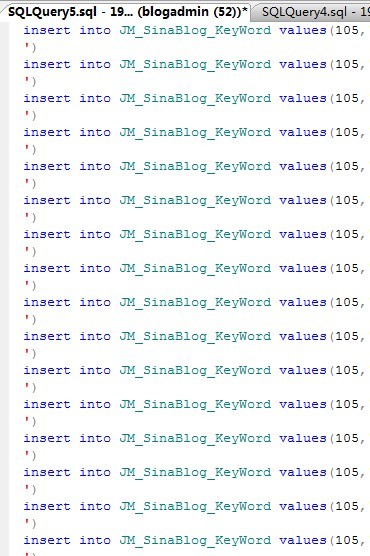
看到換行了吧,這樣一來就會將在結果中多了個r,在數據庫表中還看不到,但是在用的時候,如果僅僅用於顯示,也沒問題,但是如果用來匹配,那就悲劇了。因此今天更改了程序。要將換行符替換掉。代碼改為如下所示,其中改動部分紅色標記:
?
1 2 3 4 5 6 7 8 9 static void Main(string[] args) { string str = File.ReadAllText(@"D:daoru.txt", Encoding.Default); Regex reg = new Regex(@".+"); string str1 = reg.Replace(str, "insert into JM_SinaBlog_KeyWord values(105,'jmeii','jmeii','$&')").Replace((char)13, (char)0);//here File.WriteAllText(@"D:123.txt", str1); Console.ReadKey(); }這樣一來,就替換掉換行符了。將生成的代碼再復制到SQLSERVER裡,可以看到SQLSERVER的顯示變了:
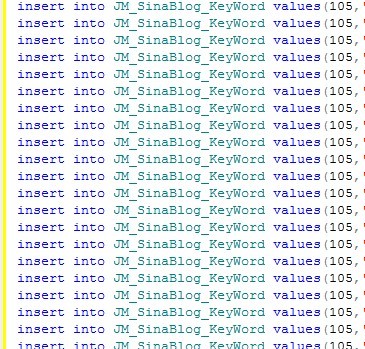
這樣就沒問題了,以後在寫正則表達式時要對換行,空格非常敏感才行。