將值 a a a替換為 b b b
本小節所用原始數據(demo.xlsx):
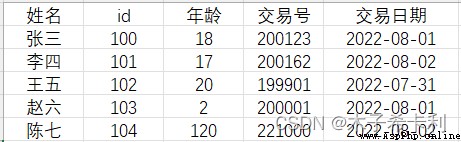
首先選擇要操作的區域
點擊菜單欄 “開始”> “編輯”>“查找和選擇”>“替換” (或者Ctrl+H),調出替換界面
將異常值120替換為18:
df.replace(to_replace=None,
value=<no_default>,
inplace: 'bool' = False,
limit=None,
regex: 'bool' = False,
method: 'str | lib.NoDefault' = <no_default>)
to_replace設置被替換的值或替換方式value設置替換後的值。limit設置替換的最多個數inplace設置的是否在原表上進行操作。為False代表不是,會返回一個新表。為True代表是,返回None.默認為Falseregex設置是否支持正則表達式。默認為False不支持。設置為True,支持,此時to_replace必須是正則表達式字符串。method設置value的就近替換方式。此時value必須為None 。'pad'或'ffill'為上一個非空值。'backfill'或'bfill'為下一個非空值。將異常值120替換為18:
print(df)
""" 姓名 id 年齡 交易號 交易日期 0 張三 100 18 200123 2022-08-01 1 李四 101 17 200162 2022-08-02 2 王五 102 20 199901 2022-07-31 3 趙六 103 2 200001 2022-08-01 4 陳七 104 120 221000 2022-08-02 """
df["年齡"].replace(120,18,inplace=True) # 先選中"年齡"列,再替換
print(df)
""" 姓名 id 年齡 交易號 交易日期 0 張三 100 18 200123 2022-08-01 1 李四 101 17 200162 2022-08-02 2 王五 102 20 199901 2022-07-31 3 趙六 103 2 200001 2022-08-01 4 陳七 104 18 221000 2022-08-02 """
將值 a , b , c . . . a,b,c... a,b,c... 替換為 d d d
可以直接進行多次一對一替換。
也可以借助OR函數和IF函數,將替換後的數據新建一列顯示
=OR(條件1,條件2,···)
=IF(條件,條件成立值,條件不成立的值)
已知"年齡"是第C列,新建一列“替換後的年齡",對C2應用以下公式,並填充到整列
=IF(OR(C2=17,C2=2,C2=120),18,C2)
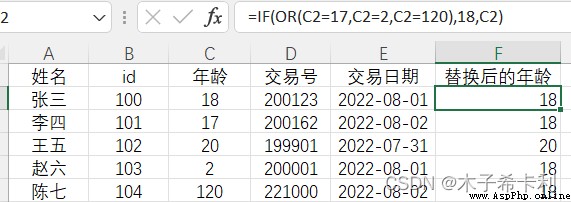
如圖所示,異常值17,2,120都替換成了18,顯示在新列中
繼續使用replace方法,只是需將傳入的to_replace改為列表
如:
df["年齡"].replace([17,2,120],18,inplace=True)
print(df)
""" 姓名 id 年齡 交易號 交易日期 0 張三 100 18 200123 2022-08-01 1 李四 101 18 200162 2022-08-02 2 王五 102 20 199901 2022-07-31 3 趙六 103 18 200001 2022-08-01 4 陳七 104 18 221000 2022-08-02 """
將值 a , b , c . . . a,b,c... a,b,c...替換為 A , B , C . . . A,B,C... A,B,C...
可以直接進行多次一對一替換。
也可以借助嵌套的IF函數將替換後的數據新建一列顯示
已知"年齡"是第C列,新建一列“替換後的年齡",對C2應用以下公式,並填充到整列
=IF(OR(C2=17,C2=2),18,IF(C2=120,60,C2))
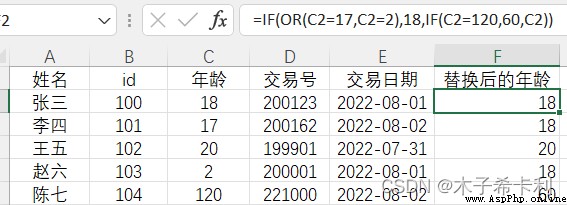
如圖所示,異常值17,2替換成了18,120替換成了60,顯示在新列中
繼續使用replace方法。將to_replace改為字典,key為被替換的值,value為替換後的值。不需要設置value。
如:
df["年齡"].replace({
(17,2):18,120:60},inplace=True)
print(df)
""" 姓名 id 年齡 交易號 交易日期 0 張三 100 18 200123 2022-08-01 1 李四 101 18 200162 2022-08-02 2 王五 102 20 199901 2022-07-31 3 趙六 103 18 200001 2022-08-01 4 陳七 104 60 221000 2022-08-02 """
選中一列,點擊菜單欄"開始">“編輯”>“排序與篩選”>“升序”/"降序"進行排序
df.sort_values(by,
axis: 'Axis' = 0,
ascending=True,
inplace: 'bool' = False,
na_position: 'str' = 'last',
ignore_index: 'bool' = False,
key: 'ValueKeyFunc' = None
)
by設置排序的依據。可以是索引名,也可以是索引名組成的列表。axis設置將行還是列看成一個單位整體進行排序。0或'index' 代表行。1或columns代表列。ascending設置是升序排序(True),還是降序排序(False)。inplace設置的是否在原表上進行操作。為False代表不是,會返回一個新表。為True代表是,返回None.默認為Falsena_position設置排序時空值的位置。first代表放在最前面,last代表放在最後面。ignore_index設置是否重新設置默認索引(從0開始的整數)。False代表不重新設置,True代表重新設置。key,指定其他排序方式,需要傳入函數對象,同Python內置函數sort()的key參數如:
df1=df.sort_values("年齡")
print(df1)
""" 姓名 id 年齡 交易號 交易日期 0 張三 100 18 200123 2022-08-01 1 李四 101 18 200162 2022-08-02 3 趙六 103 18 200001 2022-08-01 2 王五 102 20 199901 2022-07-31 4 陳七 104 60 221000 2022-08-02 """
df2=df.sort_values("年齡",ascending=False,ignore_index=True)
print(df2)
""" 姓名 id 年齡 交易號 交易日期 0 陳七 104 60 221000 2022-08-02 1 王五 102 20 199901 2022-07-31 2 張三 100 18 200123 2022-08-01 3 李四 101 18 200162 2022-08-02 4 趙六 103 18 200001 2022-08-01 """
選中整個表格,點擊菜單欄"開始">“編輯”>“排序與篩選”>“自定義排序”,
調出"自定義排序"界面,
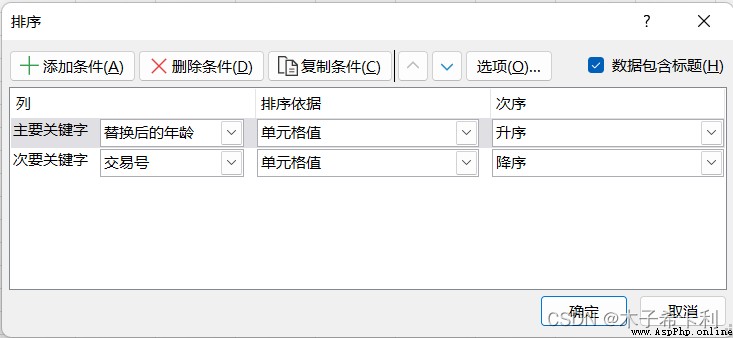
依次從上到下添加條件。
如圖,按照條件1(主要關鍵字)"替換後的年齡"進行升序排序,如果"替換後的年齡"相同,再按照條件2(次要關鍵字)"交易號"進行降序排序。
最終結果:
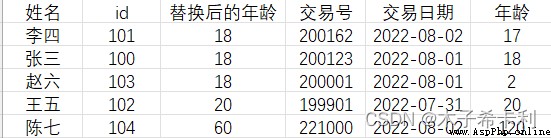
繼續使用sort_values()方法。
設置by為列表,從前往後重要級別下降。
設置ascending為對應by的列表,True代表升序,False代表降序。
如,按照"年齡"進行升序排序,如果"年齡"相同,再按照"交易號"進行降序排序。
df3=df.sort_values(["年齡","交易號"],ascending=[True,False])
print(df3)
""" 姓名 id 年齡 交易號 交易日期 1 李四 101 18 200162 2022-08-02 0 張三 100 18 200123 2022-08-01 3 趙六 103 18 200001 2022-08-01 2 王五 102 20 199901 2022-07-31 4 陳七 104 60 221000 2022-08-02 """
數值排名與數值排序相對應。一般排完序後再添加一列,用以登記排名情況。
=RANK.AVG(number,ref,order)
number設置需要進行排名的數的位置ref設置需要排名的數的范圍(一般是一整列)order設置是升序(1)還是降序(0)number相同,排名值取其原始排名值的最佳和最差的平均如:
=RANK.AVG(C2,$C$2:$C$6,1)
$C$2:$C$6代表絕對引用,不會隨著公式的填充而自動變化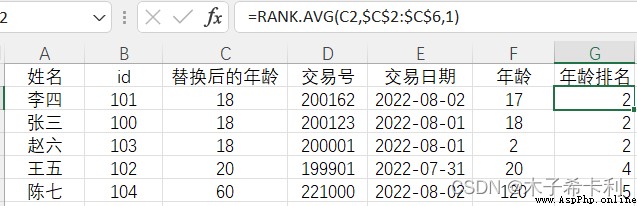
李四,張三,王五"替換後的年齡"一致,而原始排名值為1,2,3,經過中值排名後,排名都變為 1 + 3 2 = 2 \frac{1+3}{2}=2 21+3=2
=RANK.EQ(number,ref,order)
參數同RANK.AVG
如果多者number相同,排名值取其原始排名值的最佳值
如:
=RANK.EQ(C2,$C$2:$C$6,1)
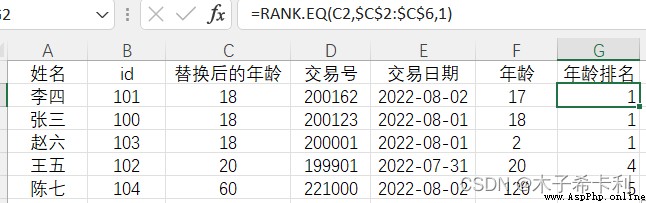
李四,張三,王五"替換後的年齡"一致,而原始排名值為1,2,3,經過最佳排名後,排名都變為1
df.rank(axis=0,
method: 'str' = 'average',
numeric_only: 'bool_t | None | lib.NoDefault' = <no_default>,
na_option: 'str' = 'keep',
ascending: 'bool_t' = True,
pct: 'bool_t' = False,)
此處的df一般為一列或者Series
axis設置按行還是列進行排名。0或'index' 代表行。1或columns代表列。
method設置排名方式。'average'相同按中值排名(同RANK.AVG,默認),min相同按最佳排名(同RANK.EQ),max相同按最差排名,first相同按出現順序排名
numeric_only,設置對不止一列的表,只對數值型數據進行排名。
na_option,設置對空值的處理。'keep',保持空值(默認)。'top',排名設置為最佳。'bottom',排名設置為最差。
ascending設置是按升序進行排名(True),還是按降序進行排名(False)。
pct,設置是否以百分數的形式顯示排名。
如:
df3['中值排名']=df3["年齡"].rank()
df3['最佳排名']=df3["年齡"].rank(method="min")
df3['先後排名']=df3["年齡"].rank(method="first")
print(df3)
""" 姓名 id 年齡 交易號 交易日期 中值排名 最佳排名 先後排名 1 李四 101 18 200162 2022-08-02 2.0 1.0 1.0 0 張三 100 18 200123 2022-08-01 2.0 1.0 2.0 3 趙六 103 18 200001 2022-08-01 2.0 1.0 3.0 2 王五 102 20 199901 2022-07-31 4.0 4.0 4.0 4 陳七 104 60 221000 2022-08-02 5.0 5.0 5.0 """
選中要刪除的一列或多列,右鍵"刪除"
df.drop(labels=None,
axis: 'Axis' = 0,
index=None,
columns=None,
level: 'Level | None' = None,
inplace: 'bool' = False,
errors: 'str' = 'raise')
labels設置要刪除的行/列的名稱索引。與axis搭配使用axis設置刪除的是行(0)還是列(1)。index設置要刪除的行的索引。columns設置要刪除的列的索引。level,當索引有多層次時,設置刪除哪層。inplace設置的是否在原表上進行操作。為False代表不是,會返回一個新表。為True代表是,返回None.默認為Falseerrors設置轉化失敗後的行為。'raise'為報錯,'ignore'為忽視。默認'raise'如:
df4=df3.drop("中值排名",axis=1)
print(df4)
""" 姓名 id 交易號 交易日期 年齡 年齡排名 最佳排名 先後排名 0 李四 101 200162 2022-08-02 18 1 1.0 1.0 1 張三 100 200123 2022-08-01 18 1 1.0 2.0 2 趙六 103 200001 2022-08-01 18 1 1.0 3.0 3 王五 102 199901 2022-07-31 20 4 4.0 4.0 4 陳七 104 221000 2022-08-02 60 5 5.0 5.0 """
df5=df3.drop(["中值排名","先後排名"],axis=1)
print(df5)
""" 姓名 id 交易號 交易日期 年齡 年齡排名 最佳排名 0 李四 101 200162 2022-08-02 18 1 1.0 1 張三 100 200123 2022-08-01 18 1 1.0 2 趙六 103 200001 2022-08-01 18 1 1.0 3 王五 102 199901 2022-07-31 20 4 4.0 4 陳七 104 221000 2022-08-02 60 5 5.0 """
df6=df3.drop(columns=["中值排名","最佳排名"])
print(df6)
""" 姓名 id 交易號 交易日期 年齡 年齡排名 先後排名 0 李四 101 200162 2022-08-02 18 1 1.0 1 張三 100 200123 2022-08-01 18 1 2.0 2 趙六 103 200001 2022-08-01 18 1 3.0 3 王五 102 199901 2022-07-31 20 4 4.0 4 陳七 104 221000 2022-08-02 60 5 5.0 """
選中要刪除的一行或多行,右鍵"刪除"
drop()方法,傳入labels+axis=0(默認) 或index
如:
df3.set_index("姓名",inplace=True)
df7=df3.drop("趙六")
print(df7)
""" id 交易號 交易日期 年齡 年齡排名 中值排名 最佳排名 先後排名 姓名 李四 101 200162 2022-08-02 18 1 2.0 1.0 1.0 張三 100 200123 2022-08-01 18 1 2.0 1.0 2.0 王五 102 199901 2022-07-31 20 4 4.0 4.0 4.0 陳七 104 221000 2022-08-02 60 5 5.0 5.0 5.0 """
df8=df3.drop(["張三","王五"])
print(df8)
""" id 交易號 交易日期 年齡 年齡排名 中值排名 最佳排名 先後排名 姓名 李四 101 200162 2022-08-02 18 1 2.0 1.0 1.0 趙六 103 200001 2022-08-01 18 1 2.0 1.0 3.0 陳七 104 221000 2022-08-02 60 5 5.0 5.0 5.0 """
df9=df3.drop(index=["李四","趙六"])
print(df9)
""" id 交易號 交易日期 年齡 年齡排名 中值排名 最佳排名 先後排名 姓名 張三 100 200123 2022-08-01 18 1 2.0 1.0 2.0 王五 102 199901 2022-07-31 20 4 4.0 4.0 4.0 陳七 104 221000 2022-08-02 60 5 5.0 5.0 5.0 """
“篩選"選擇滿足條件的行,右鍵"刪除”
pandas刪除特定行的方法是,過濾掉它們。通過布爾索引選出不需要刪除的行作為新的數據源,那些需要刪除的行自然就被"刪除"了。
利用COUNTIF函數
=COUNTIF(range,criteria)
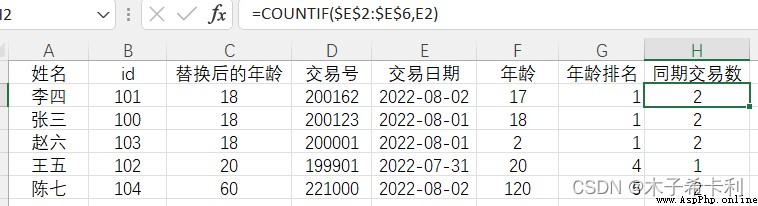
range設置計數的區域范圍criteria設置計數的條件(一個值或布爾條件)如統計在相同日期內交易的個數:
=COUNTIF($E$2:$E$6,E2)
df.value_counts(subset: 'Sequence[Hashable] | None' = None,
normalize: 'bool' = False,
sort: 'bool' = True,
ascending: 'bool' = False,
dropna: 'bool' = True)
subset設置進行計數的子列(相同值合並+1)
normalize設置顯示方式為占比。
sort設置是否按計數進行排序
ascending設置排序方式。默認False降序排序。True升序排序
dropna設置是否忽略空值。
如統計在各日期內交易的個數:
date_count=df3.value_counts(subset="交易日期")
print(date_count)
""" 交易日期 2022-08-01 2 2022-08-02 2 2022-07-31 1 dtype: int64 """
date_count=df3.value_counts(subset="交易日期",normalize=True,ascending=True)
print(date_count)
""" 交易日期 2022-07-31 0.2 2022-08-01 0.4 2022-08-02 0.4 dtype: float64 """
單獨復制出想要獲取唯一值的列,按照5.2節"重復值處理"的方法,在菜單欄依次選擇"數據">“數據工具">“刪除重復值”。剩下的就是該列的唯一值。
Series.unique()
array對象,類似列表如:
ages=df3["年齡"].unique()
print(ages)
""" [18 20 60] """
選中查找范圍(默認全表),點擊菜單欄"開始">“編輯”>“查找和選擇”>“查找”,
或者Ctrl+F,調出"查找與替換"界面
輸入查找內容,點擊"查找全部"或者"查找下一個"
df.isin(values)
values設置想要查找的值。可傳入列表True,False組成的與df同型的表格。True代表與values中某個值相同如:
is18=df3["年齡"].isin([18])
print(is18)
""" 姓名 李四 True 張三 True 趙六 True 王五 False 陳七 False Name: 年齡, dtype: bool """
將數據按照大小切分為不同個區間
可以通過IF函數嵌套實現:
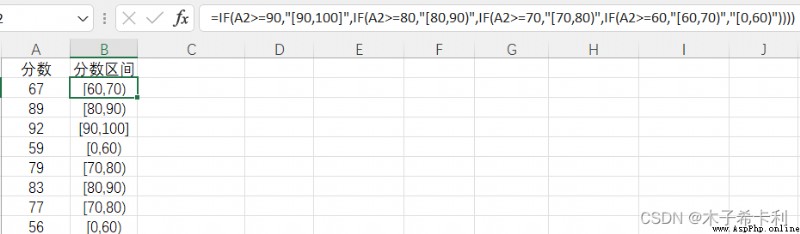
=IF(A2>=90,"[90,100]",IF(A2>=80,"[80,90)",IF(A2>=70,"[70,80)",IF(A2>=60,"[60,70)","[0,60)"))))
pd.cut( x,
bins,
right: 'bool' = True,
labels=None,
include_lowest: 'bool' = False
)
x,設置被切分的序列。需傳入一維列表類似的對象,如Seriesbins設置切分區間。可以傳入端點組成的列表,也可以傳入區間長度(此時自動切分)right設置右端點是否包含labels設置各區間名include_lowest設置左端點是否包含如:
grades=pd.Series([67,89,92,59,79,83,77,56])
new=pd.cut(grades,[0,60,70,80,90,100],right=False,include_lowest=True)
print(new)
""" 0 [60, 70) 1 [80, 90) 2 [90, 100) 3 [0, 60) 4 [70, 80) 5 [80, 90) 6 [70, 80) 7 [0, 60) dtype: category Categories (5, interval[int64, left]): [[0, 60) < [60, 70) < [70, 80) < [80, 90) < [90, 100)] """
pd.qcut( x,
q,
labels=None
)
x,設置被切分的序列。需傳入一維列表類似的對象,如Series
q設置自動切割的位數。如十分位(10),四分位(4),二分位(2)等。還可傳入占比組成的列表,如[0,0.25,0.5,0.75,1.0]設置四分位
labels設置各區間名
如:
grades=pd.Series([67,89,92,59,79,83,77,56])
new=pd.qcut(grades,2,labels=["平均以下","平均以上"])
print(new)
""" 0 平均以下 1 平均以上 2 平均以上 3 平均以下 4 平均以上 5 平均以上 6 平均以下 7 平均以下 dtype: category Categories (2, object): ['平均以下' < '平均以上'] """
grades=pd.Series([67,89,92,59,79,83,77,56])
new=pd.qcut(grades,[0,0.5,0.8,1],["第三梯隊","第二梯隊","第一梯隊"])
print(new)
""" 0 第三梯隊 1 第一梯隊 2 第一梯隊 3 第三梯隊 4 第二梯隊 5 第二梯隊 6 第三梯隊 7 第三梯隊 dtype: category Categories (3, object): ['第三梯隊' < '第二梯隊' < '第一梯隊'] """
想要在某行或某列的前面插入行/列,先選中這行/列,再右鍵"插入"
插入行並沒有現成的方法。可以將要插入的行當做一張新表,通過兩表縱向拼接的方式達到插入的效果(後面章節詳述)。
新增加列可以直接通過索引賦值的方式:
df[新列名]=[新列]
在指定位置插入列可通過insert方法
df.insert(loc: 'int',
column: 'Hashable',
value: 'Scalar | AnyArrayLike',
allow_duplicates: 'bool' = False,)
loc設置插入的位置。從0開始編號column設置插入的列的索引名value設置插入的列的數據內容allow_duplicates設置是否允許新插入的列名與已有列名重合。默認不允許重合(False)。如:
people=pd.DataFrame({
"姓名":["張三","李四","王五"],"年齡":[18,19,20],"專業":["數學與應用數學","軟件工程","計算機科學"]})
people.set_index("姓名",inplace=True)
people.insert(1,"學校",["清華大學","北京大學","浙江大學"])
people["平均績點"]=[3.9,3.8,4.0]
print(people)
""" 年齡 學校 專業 平均績點 姓名 張三 18 清華大學 數學與應用數學 3.9 李四 19 北京大學 軟件工程 3.8 王五 20 浙江大學 計算機科學 4.0 """
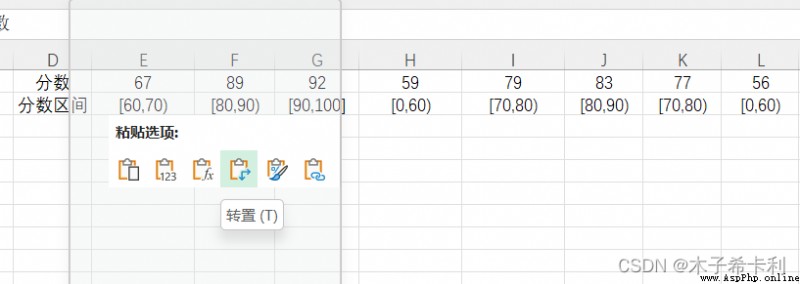
將整個表格復制,右鍵"粘貼",選擇粘貼選項:“轉置”
df.T
如:
print(people.T)
""" 姓名 張三 李四 王五 年齡 18 19 20 學校 清華大學 北京大學 浙江大學 專業 數學與應用數學 軟件工程 計算機科學 平均績點 3.9 3.8 4.0 """
print(people.T.T)
""" 年齡 學校 專業 平均績點 姓名 張三 18 清華大學 數學與應用數學 3.9 李四 19 北京大學 軟件工程 3.8 王五 20 浙江大學 計算機科學 4.0 """
常見的DataFrame結構是:
A B C
a 1 2 3
b 4 5 6
c 7 8 9
這是同時尋找行索引和列索引來定位一個數據。
同樣的信息,還可以使用下面這樣的樹形結構來表達:
A 1
a B 2
C 3
A 4
b B 5
C 6
A 7
c B 8
C 9
這是先通過第一層的行索引初步定位,再通過第二層的行索引進一步定位。(層次化索引)
將普通表型結構轉化為樹形結構,本質是將列索引也轉化為行索引。將樹形結構轉化為普通表結構是相反的過程
df.stack(level: 'Level' = -1, dropna: 'bool' = True)
level指定要轉化的列索引在層次化列索引中的層數。
dropna設置是否拋棄空值
將指定列索引轉變為內層行索引
df.unstack(level: 'Level' = -1, fill_value=None)
level指定要轉化的行索引在層次化行索引中的層數。fill_value設置出現空值時填充的內容。如:
a=people.stack()
print(a)
""" 姓名 張三 年齡 18 學校 清華大學 專業 數學與應用數學 平均績點 3.9 李四 年齡 19 學校 北京大學 專業 軟件工程 平均績點 3.8 王五 年齡 20 學校 浙江大學 專業 計算機科學 平均績點 4.0 dtype: object """
b=a.unstack()
print(b)
""" 年齡 學校 專業 平均績點 姓名 張三 18 清華大學 數學與應用數學 3.9 李四 19 北京大學 軟件工程 3.8 王五 20 浙江大學 計算機科學 4.0 """
長表:由於列的值多次重復而造成的行數較多的表。
如:
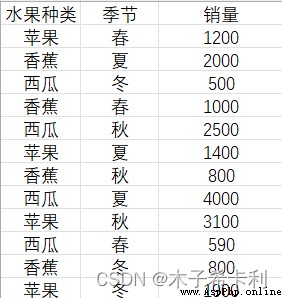
寬表:由於列劃分較多而造成的列數較多的表。

首先,利用set_index將不變的列設置為行索引。
其次,調用stack方法,將同一種類不同細化的列轉化為行索引。
最後,利用reset_index重置索引。
如:
fruits=pd.DataFrame({
"水果種類":["蘋果","香蕉","西瓜"],
"春":[1200,1000,590],
"夏":[1400,2000,4000],
"秋":[3100,800,2500],
"冬":[1900,800,500]
})
print(fruits)
""" 水果種類 春 夏 秋 冬 0 蘋果 1200 1400 3100 1900 1 香蕉 1000 2000 800 800 2 西瓜 590 4000 2500 500 """
fruits.set_index("水果種類",inplace=True)
fruits=fruits.stack()
print(fruits)
""" 水果種類 蘋果 春 1200 夏 1400 秋 3100 冬 1900 香蕉 春 1000 夏 2000 秋 800 冬 800 西瓜 春 590 夏 4000 秋 2500 冬 500 dtype: int64 """
fruits=fruits.reset_index()
print(fruits)
""" 水果種類 level_1 0 0 蘋果 春 1200 1 蘋果 夏 1400 2 蘋果 秋 3100 3 蘋果 冬 1900 4 香蕉 春 1000 5 香蕉 夏 2000 6 香蕉 秋 800 7 香蕉 冬 800 8 西瓜 春 590 9 西瓜 夏 4000 10 西瓜 秋 2500 11 西瓜 冬 500 """
fruits.rename(columns={
"level_1":"季節",0:"銷量"},inplace=True)
print(fruits)
""" 水果種類 季節 銷量 0 蘋果 春 1200 1 蘋果 夏 1400 2 蘋果 秋 3100 3 蘋果 冬 1900 4 香蕉 春 1000 5 香蕉 夏 2000 6 香蕉 秋 800 7 香蕉 冬 800 8 西瓜 春 590 9 西瓜 夏 4000 10 西瓜 秋 2500 11 西瓜 冬 500 """
df.melt(id_vars=None,
value_vars=None,
var_name=None,
value_name='value',
ignore_index: 'bool' = True)
id_vars指定寬表轉化為長表時不變的列。value_vars指定同一種類不同細化的列,以供轉化var_name設置value_var中的列的的列名在寬轉長之後對應的那一列的列名。value_name設置value_var中的列的數據值在寬轉長之後對應的那一列的列名。ignore_index設置自動生成新的數字索引而拋棄原來的行索引。如:
fruits=pd.DataFrame({
"水果種類":["蘋果","香蕉","西瓜"],
"春":[1200,1000,590],
"夏":[1400,2000,4000],
"秋":[3100,800,2500],
"冬":[1900,800,500]
})
print(fruits)
""" 水果種類 春 夏 秋 冬 0 蘋果 1200 1400 3100 1900 1 香蕉 1000 2000 800 800 2 西瓜 590 4000 2500 500 """
fruits=fruits.melt(id_vars="水果種類",value_vars=["春","夏","秋","冬"],var_name="季節",value_name="銷量")
print(fruits)
""" 水果種類 季節 銷量 0 蘋果 春 1200 1 香蕉 春 1000 2 西瓜 春 590 3 蘋果 夏 1400 4 香蕉 夏 2000 5 西瓜 夏 4000 6 蘋果 秋 3100 7 香蕉 秋 800 8 西瓜 秋 2500 9 蘋果 冬 1900 10 香蕉 冬 800 11 西瓜 冬 500 """
常見的方法是數據透視表。後面的章節會詳述。此處只是大概浏覽一下。
長表轉化為寬表,有點像寬表轉化成長表的逆過程。
df.pivot_table(values=None,
index=None,
columns=None)
values設置某列成為轉化後的寬表中的同一種類不同細化的列的數據。index設置轉化過程中不變的列。columns設置某列成為轉化後的寬表中的同一種類不同細化的列的列名。print(fruits)
""" 水果種類 季節 銷量 0 蘋果 春 1200 1 香蕉 春 1000 2 西瓜 春 590 3 蘋果 夏 1400 4 香蕉 夏 2000 5 西瓜 夏 4000 6 蘋果 秋 3100 7 香蕉 秋 800 8 西瓜 秋 2500 9 蘋果 冬 1900 10 香蕉 冬 800 11 西瓜 冬 500 """
fruits=fruits.pivot_table(values="銷量",index="水果種類",columns="季節")
print(fruits)
""" 季節 冬 夏 春 秋 水果種類 蘋果 1900 1400 1200 3100 西瓜 500 4000 590 2500 香蕉 800 2000 1000 800 """
 2. The first step by step teach you how to use pycharm running Django project
2. The first step by step teach you how to use pycharm running Django project
The following steps show how t
 Application practice of Python selenium actionchains Library (simulated mouse hover) and select Library (hierarchical menu selection)
Application practice of Python selenium actionchains Library (simulated mouse hover) and select Library (hierarchical menu selection)
selenium Is a browser automati