import re # 正則表達式模塊
import time
import requests # 數據請求模塊
import os # 文件操作模塊
filename = 'music\\'
if not os.path.exists(filename):
# 不存在則創建
os.mkdir(filename)
rank_id = input('請輸入您想要爬取的榜單id:')
# 如果要爬取其他榜單歌曲,只需更改url中的id
url = f"https://music.163.com/discover/toplist?id={
rank_id}"
""" headers請求頭,將Python代碼偽裝成浏覽器對服務器發送請求, 服務器接收到請求後,返回響應數據response """
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
# 發送請求,對榜單url地址發送請求
# 獲取數據,獲取服務器返回的響應數據
response = requests.get(url, headers)
# print(response.text)
# html_data = re.findall('a href="/song\?id=(\d+)">(.*?)</a></li>', response.text)
# 解析數據,提取textarea裡面的內容
html_data = re.findall('<textarea id="song-list-pre-data" >(.*?)</textarea>',
response.text)[0]
if len(html_data):
dir_name = filename + rank_id + '\\'
if not os.path.exists(dir_name):
# 不存在則創建
os.mkdir(dir_name)
false = null = true = ''
# 將字符串轉成列表
album_list = eval(html_data)
# print(album_list)
music_info_list = []
for album in album_list:
# 列表album_list裡面的元素都是字典類型,可通過key取值
# print(album)
# 歌手可能有多個,將歌手列表轉換成字符串,歌手之間以&拼接
artists = '&'.join([album['artists'][i]['name'] for i in range(len(album['artists']))])
# print(artist)
music_id = album['id'] # 歌曲id
title = album['name'] # 歌曲標題
trans_names = album['transNames'] # 備注/別名
title = title + '-(' + '&'.join(trans_names) + ')' if trans_names != '' else title
# print(f'{title}--{music_id}--{artists}')
# 將歌曲id、標題及歌手以元組形式添加到列表
# print(title)
music_info_list.append((music_id, title, artists))
# print(music_info_list)
# 正則表達式提取出來的內容,返回的是列表,裡面的每個元素都是元組
# print(html_data)
# 統計榜單歌曲總數、下載成功及失敗的歌曲數
count = success = fail = 0
for music_id, title, artists in music_info_list:
try:
music_url = f'http://music.163.com/song/media/outer/url?id={
music_id}.mp3'
# 文件名不允許包含特殊字符,需進行替換
title = re.sub(r'[\/:*?"<>|]', '_', title)
count += 1
# 對於音樂播放地址發送請求,獲取二進制數據內容
music_content = requests.get(music_url, headers).content
# print(type(music_content))
# print(len(music_content))
with open(f'{
dir_name}{
title}--{
artists}.mp3', mode='wb') as f:
f.write(music_content)
success += 1
print(f'第{
count}首:{
title}--{
artists}-->下載完成')
time.sleep(0.2)
# 出現異常,捕獲並輸出
except Exception as e:
print(e)
print(f'第{
count}首:{
title}--{
artists}-->下載失敗')
fail += 1
# 繼續下載下一首
continue
print(f'{
rank_id}爬取完畢-->成功下載{
success}首')
else:
print('未匹配到該榜單id')
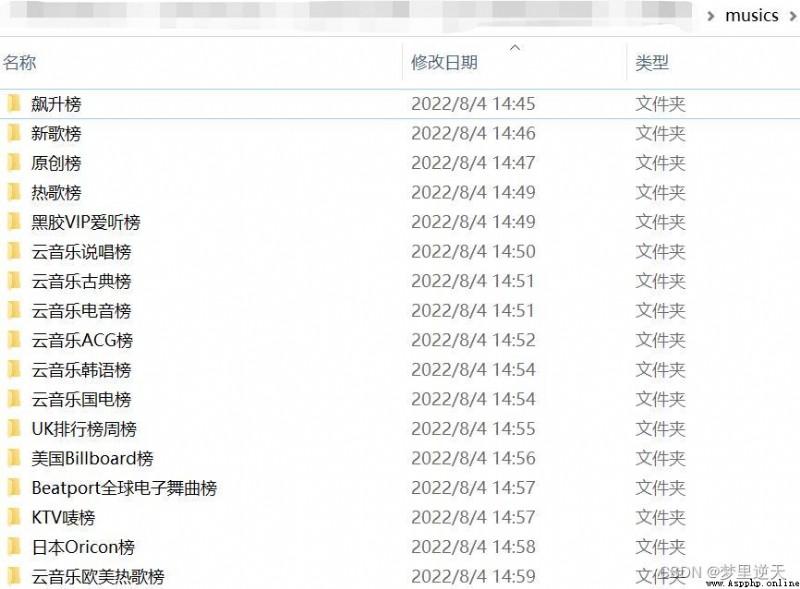
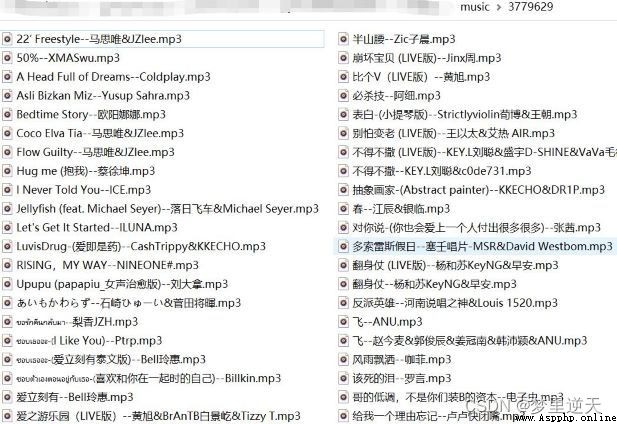
爬取效果:
""" 爬蟲思路: 一、數據來源分析: 1.確定內容、目標>>>音樂榜單數據--榜單id及標題 2.通過開發者工具進行抓包分析 1.先獲取所有榜單的id 2.獲取所有歌曲的id 3.把參數傳入引用數據包中,獲取音樂的url地址及標題 4.保存數據 二、代碼實現步驟: 1.發送請求,對榜單(排行榜)url地址發送請求 2.獲取數據,獲取服務器返回的響應數據 3.解析數據,提取榜單id及標題 4.發送請求,對榜單url地址發送請求 5.獲取數據,獲取服務器返回的響應數據 6.解析數據,提取id參數 7.發送請求,對音樂數據包發送請求 8.獲取數據,獲取服務器返回的響應數據 9.解析數據,提取音樂的url地址及標題 10.保存數據 """
# -- coding: utf-8 --
import time
import requests # 數據請求模塊
import os # 文件操作模塊
import re # 正則表達式模塊
# fake_useragent第三方庫,來實現隨機請求頭的設置 pip install fake-useragent
from fake_useragent import UserAgent
# 禁用服務器緩存,忽略ssl驗證
agent = UserAgent(use_cache_server=False, verify_ssl=False).random
def get_response(html_url):
"""發送請求"""
""" headers請求頭,將Python代碼偽裝成浏覽器對服務器發送請求, 服務器接收到請求後,返回響應數據response """
headers = {
'User-Agent': agent
}
response = requests.get(url=html_url, headers=headers)
return response
def get_rank_info_list(html_url):
"""獲取榜單信息--id及標題"""
# 發送請求,對榜單(排行榜)url地址發送請求
# 獲取數據,獲取服務器返回的響應數據
response = get_response(html_url)
# 解析數據,提取榜單id及標題
# 獲取所有榜單id \d+:匹配1個或多個數字
rank_info_list = re.findall('<p class="name"><a href="/discover/toplist\?id=(\d+)" class="s-fc0">(.*?)</a></p>',
response.text)
# 正則表達式提取出來的內容,返回的是列表,裡面的每個元素都是元組
# print(rank_info_list)
# print(len(rank_info_list))
return rank_info_list
def get_music_info_list(rank_id):
"""獲取音頻的id及標題"""
rank_link = f'https://music.163.com/discover/toplist?id={
rank_id}'
# 發送請求,對榜單url地址發送請求
# 獲取數據,獲取服務器返回的響應數據
# 解析數據,提取textarea裡面的內容
html_data = re.findall('<textarea id="song-list-pre-data" >(.*?)</textarea>', get_response(rank_link).text)
while True:
if len(html_data):
rank_data = html_data[0]
break
else:
html_data = re.findall('<textarea id="song-list-pre-data" >(.*?)</textarea>',
get_response(rank_link).text)
# print(rank_data)
# rank_data為字符串類型,裡面的數據是列表
# print(type(rank_data))
# NameError: name 'false' is not defined
# 遇到這個問題,一般是因為eval無法解析null, true, false之類的數據
false = null = true = ''
# 將字符串轉成列表
album_list = eval(rank_data)
# print(album_list)
music_info_list = []
for album in album_list:
# 列表album_list裡面的元素都是字典類型,可通過key取值
# print(album)
# 歌手可能有多個,將歌手列表轉換成字符串,歌手之間以&拼接
artists = '&'.join([album['artists'][i]['name'] for i in range(len(album['artists']))])
# print(artist)
music_id = album['id'] # 歌曲id
title = album['name'] # 歌曲標題
trans_names = album['transNames'] # 備注/別名
title = title + '-(' + '&'.join(trans_names) + ')' if trans_names != '' else title
# print(f'{title}--{music_id}--{artists}')
# 將歌曲id、標題及歌手以元組形式添加到列表
music_info_list.append((music_id, title, artists))
# print(music_info_list)
return music_info_list
def save(dir_name, title, song_id, artists):
"""保存數據"""
music_url = f'http://music.163.com/song/media/outer/url?id={
song_id}.mp3'
# 文件名不允許包含一些特殊字符,需要進行替換
title = re.sub(r'[\/:*?"<>|]', '_', title)
# 對於音樂播放地址發送請求,獲取二進制數據內容
music_content = get_response(html_url=music_url).content # 獲取音樂的二進制數據
with open(f'{
dir_name}{
title}--{
artists}.mp3', mode='wb') as f:
f.write(music_content)
def main(html_url):
"""主函數"""
# 1.創建文件保存目錄
filename = 'musics\\' # 文件保存目錄
# 判斷該文件夾是否存在
if not os.path.exists(filename):
# 不存在則創建
os.mkdir(filename)
# 2.獲取榜單信息--id及標題
rank_info_list = get_rank_info_list(html_url=html_url)
# print(rank_info_list)
# 4.遍歷榜單列表
for rank_id, rank_title in rank_info_list:
# 5.創建音頻文件保存目錄
# 文件名不允許包含特殊字符,需進行替換
rank_title = re.sub(r'[\/:*?"<>|]', '_', rank_title)
# 保存音頻文件的目錄,以榜單標題命名
dir_name = filename + rank_title + '\\'
# 判斷該文件夾是否存在
if not os.path.exists(dir_name):
# 不存在則創建
os.mkdir(dir_name)
print(f'正在爬取榜單---->{
rank_title}')
# print(rank_title, rank_id)
# 統計榜單歌曲總數、下載成功及失敗的歌曲數
count = success = fail = 0
# 6.獲取音頻的id及標題
music_info_list = get_music_info_list(rank_id)
for song_id, title, artists in music_info_list:
try:
# print(title, song_id)
count += 1
# 7.保存音頻
save(dir_name, title, song_id, artists)
success += 1
print(f'第{
count}首:{
title}--{
artists}-->下載完成')
time.sleep(0.2)
# 出現異常,捕獲並輸出
except Exception as e:
print(e)
print(f'第{
count}首:{
title}--{
artists}--下載失敗')
fail += 1
# 繼續下載下一首
continue
print(f'{
rank_title}爬取完畢-->成功下載{
success}首')
time.sleep(0.5)
if __name__ == '__main__':
url = "https://music.163.com/discover/toplist"
main(url)
爬取效果: