Before , Blogger completed GPU Configuration of the environment , Today, bloggers will try to use GPU To run our project
Use cmd Input nvidia-smi see GPU usage , Here is Linux A display inside 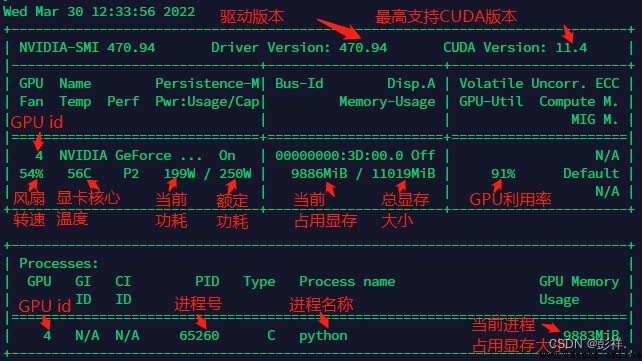
Here is my running status :
PS: Installation is required before operation tensflow-gpu And CUDA,cuDNN Correspond well , This place has tortured bloggers for a long time
https://tensorflow.google.cn/install/source_windows
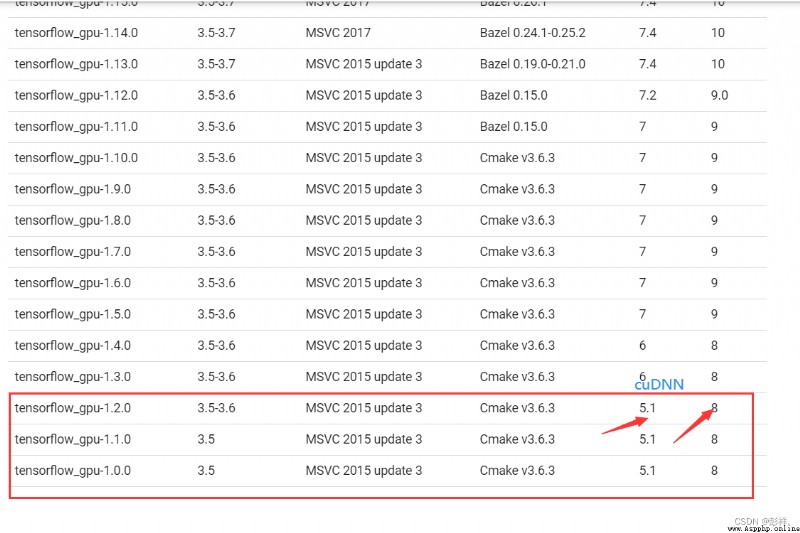
Install the corresponding tensorflow-gpu
pip install tensorflow_gpu==1.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
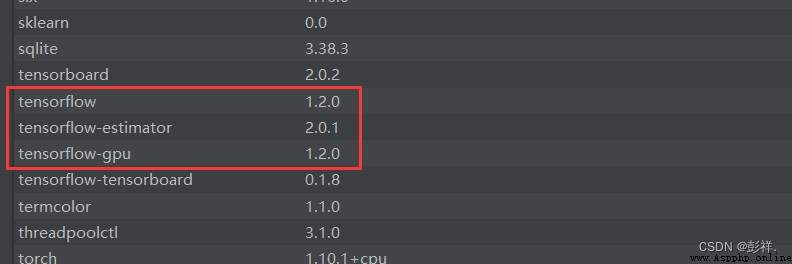
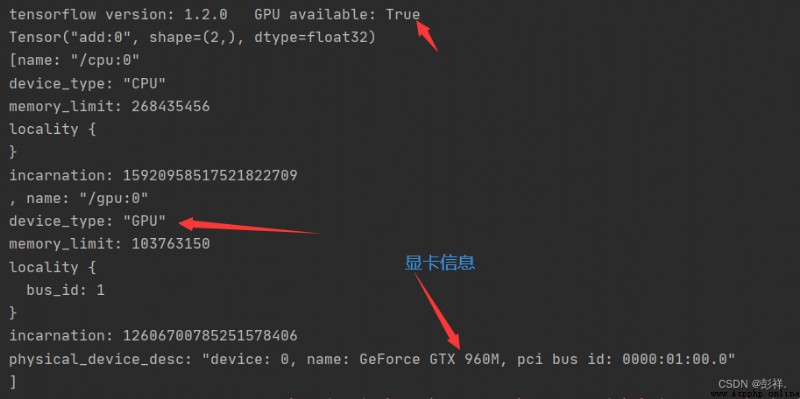
import tensorflow as tf
tensorflow_version = tf.__version__
gpu_available = tf.test.is_gpu_available()
print('tensorflow version:',tensorflow_version, '\tGPU available:', gpu_available)
a = tf.constant([1.0, 2.0], name='a')
b = tf.constant([1.0, 2.0], name='b')
result = tf.add(a,b, name='add')
print(result)
import os
from tensorflow.python.client import device_lib
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "99"
if __name__ == "__main__":
print(device_lib.list_local_devices())
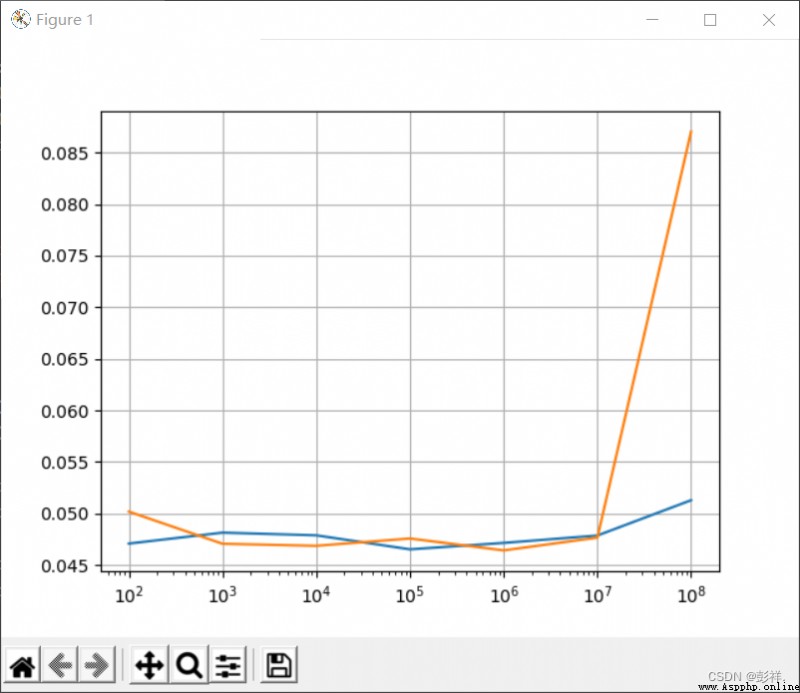
Next , Let's run a program to compare CPU and GPU Performance gap :
import tensorflow as tf
import timeit
import numpy as np
import matplotlib.pyplot as plt
def cpu_run(num):
with tf.device('/cpu:0'):
cpu_a=tf.random_normal([1,num])
cpu_b=tf.random_normal([num,1])
c=tf.matmul(cpu_a,cpu_b)
return c
def gpu_run(num):
with tf.device('/gpu:0'):
gpu_a=tf.random_normal([1,num])
gpu_b=tf.random_normal([num,1])
c=tf.matmul(gpu_a,gpu_b)
return c
k=10
m=7
cpu_result=np.arange(m,dtype=np.float32)
gpu_result=np.arange(m,dtype=np.float32)
x_time=np.arange(m)
for i in range(m):
k=k*10
x_time[i]=k
cpu_str='cpu_run('+str(k)+')'
gpu_str='gpu_run('+str(k)+')'
#print(cpu_str)
cpu_time=timeit.timeit(cpu_str,'from __main__ import cpu_run',number=10)
gpu_time=timeit.timeit(gpu_str,'from __main__ import gpu_run',number=10)
# Official calculation 10 Time , Take the average time
cpu_time=timeit.timeit(cpu_str,'from __main__ import cpu_run',number=10)
gpu_time=timeit.timeit(gpu_str,'from __main__ import gpu_run',number=10)
cpu_result[i]=cpu_time
gpu_result[i]=gpu_time
print(cpu_result)
print(gpu_result)
fig, ax = plt.subplots()
ax.set_xscale("log")
ax.set_adjustable("datalim")
ax.plot(x_time,cpu_result)
ax.plot(x_time,gpu_result)
ax.grid()
plt.draw()
plt.show()
In different CUDA Installation under version , Because the blogger's graphics card is too stretched CUDA The version is too low to support , Can only be installed CPU Version of
pip install torch1.10.1+cpu torchvision0.11.2+cpu torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
Other commands :
# CUDA 11.1
pip install torch==1.10.1+cu111 torchvision==0.11.2+cu111 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
# CUDA 10.2
pip install torch==1.10.1+cu102 torchvision==0.11.2+cu102 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
# CPU only
pip install torch==1.10.1+cpu torchvision==0.11.2+cpu torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
Dataset download address :
http://yann.lecun.com/exdb/mnist/

Handwritten numeral recognition is a relatively simple task , The numbers can only be 0-9 One of them , This is a 10 The problem of classification .
MNIST Handwritten numeral recognition project because of the small amount of data , The recognition task is simple and becomes the first lesson of image recognition ,MNIST Handwritten numeral recognition project has the following characteristics :
(1) Low recognition difficulty , Even if the picture is expanded into one-dimensional data , And more than... Can be achieved using only the full connection layer 98% The recognition accuracy of .
(2) A small amount of calculation , Unwanted GPU Acceleration can also be done quickly .
(3) Data is readily available , Tutorials are easy to get .
# coding=utf-8
import os
import torch
from torch import nn, optim
import torch.nn.functional as F
# from torch.autograd import Variable
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
trainset = datasets.MNIST('data', train=True, download=True, transform=transform)# download , Load data
testset = datasets.MNIST('data', train=False, download=True, transform=transform)
class LeNet(nn.Module):
# Definition Net Initialization function for , This function defines the basic structure of neural network
def __init__(self):
# Inherit the initialization method of the parent class , That is to run first nn.Module Initialization function for
super(LeNet, self).__init__()
# C1 Convolution layer : Input 1 A grayscale picture , Output 6 A feature map , Convolution kernel 5x5
self.c1 = nn.Conv2d(1, 6, (5, 5))
# C3 Convolution layer : Input 6 A feature map , Output 16 A feature map , Convolution kernel 5x5
self.c3 = nn.Conv2d(6, 16, 5)
# Fully connected layer S4->C5: from S4 To C5 It's full connection ,S4 Layer 16*4*4 All nodes are connected to C5 Layer of 120 A node
self.fc1 = nn.Linear(16 * 4 * 4, 120)
# Fully connected layer C5->F6:C5 Layer of 120 All nodes are connected to F6 Of 84 A node
self.fc2 = nn.Linear(120, 84)
# Fully connected layer F6->OUTPUT:F6 Layer of 84 All nodes are connected to OUTPUT Layer of 10 A node ,10 The output of nodes represents 0 To 9 Different scores .
self.fc3 = nn.Linear(84, 10)
# Define the forward propagation function
def forward(self, x):
# Input grayscale image x after c1 After convolution, we get 6 A feature map , And then use relu function , Enhance the nonlinear fitting ability of the network , Then use 2x2 Maximum pooling of windows , And then update to x
x = F.max_pool2d(F.relu(self.c1(x)), 2)
# Input x after c3 The convolution of is followed by the original 6 The feature map becomes 16 A feature map , after relu function , And update the results to... After using maximum pooling x
x = F.max_pool2d(F.relu(self.c3(x)), 2)
# Use view The function will tensor x(S4) Change to form a one-dimensional vector form , The total characteristic number remains unchanged , Prepare for the full connection layer
x = x.view(-1, self.num_flat_features(x))
# Input S4 Through the full connectivity layer fc1, after relu, Update to x
x = F.relu(self.fc1(x))
# Input C5 Through the full connectivity layer fc2, after relu, Update to x
x = F.relu(self.fc2(x))
# Input F6 Through the full connectivity layer fc3, Update to x
x = self.fc3(x)
return x
# Calculate the tensor x The total characteristic quantity of
def num_flat_features(self, x):
# Due to the default batch input , Of the zeroth dimension batch To eliminate
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
CUDA = torch.cuda.is_available()
if CUDA:
lenet = LeNet().cuda()
else:
lenet = LeNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(lenet.parameters(), lr=0.001, momentum=0.9)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)
def train(model, criterion, optimizer, epochs=1):
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
if CUDA:
inputs, labels = inputs.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 999:
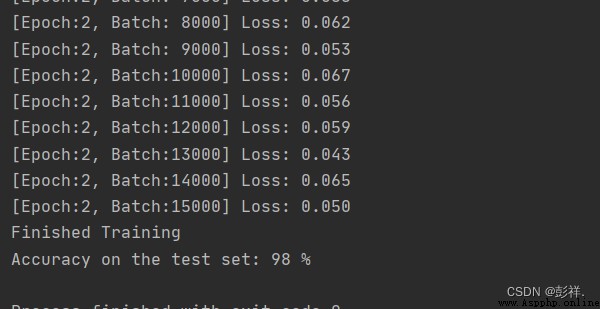
print('[Epoch:%d, Batch:%5d] Loss: %.3f' % (epoch + 1, i + 1, running_loss / 1000))
running_loss = 0.0
print('Finished Training')
def test(testloader, model):
correct = 0
total = 0
for data in testloader:
images, labels = data
if CUDA:
images = images.cuda()
labels = labels.cuda()
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy on the test set: %d %%' % (100 * correct / total))
def load_param(model, path):
if os.path.exists(path):
model.load_state_dict(torch.load(path))
def save_param(model, path):
torch.save(model.state_dict(), path)
if __name__ =="__main__":
load_param(lenet, 'model.pkl')
train(lenet, criterion, optimizer, epochs=2)
save_param(lenet, 'model.pkl')
test(testloader, lenet)