""" 實現步驟: 1.發送網絡請求 2.獲取數據 3.解析數據:提取視頻地址及標題 4.發送網絡請求:請求每一個視頻地址,獲取視頻二進制數據 5.保存視頻 6.通過關鍵詞下載視頻/指定一個用戶的視頻/翻頁下載 """
import os
import pprint
import time
import requests
import json
import re
# fake_useragent第三方庫,實現隨機請求頭的設置 pip install fake-useragent
from fake_useragent import UserAgent
dir_name = 'videos' # 視頻保存文件夾
# 判斷該文件夾是否存在,不存在則創建
if not os.path.exists(dir_name):
os.mkdir(dir_name)
# 1.發送請求 get post
# post 表單請求
# <Response [200]>:Response:響應體對象 200:訪問成功
# 禁用服務器緩存,忽略ssl驗證
ua = UserAgent(use_cache_server=False, verify_ssl=False).random
# 請求頭:偽裝 用來偽裝python代碼,防止被識別出是爬蟲程序
headers = {
'accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '1380',
'content-type': 'application/json',
'Cookie': 'kpf=PC_WEB; kpn=KUAISHOU_VISION; clientid=3; did=web_acb408fff3a5f7cd020782d58bb9caa9; ktrace-context=1|MS43NjQ1ODM2OTgyODY2OTgyLjI4ODYxOTgxLjE2MzczNzIwMzc5NTkuMTQ1NDUxNA==|MS43NjQ1ODM2OTgyODY2OTgyLjI3NzMzOTY1LjE2MzczNzIwMzc5NTkuMTQ1NDUxNQ==|0|graphql-server|webservice|false|NA; client_key=65890b29; userId=1232368006; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqABXhLnnN974NXDx7wxD7EXA0gUwiENGncAU1PMNvGRI8hgQVPES30K2a6e8FZ9L3yv89WVXIZ5I1HsDjjWJlzDijZgHPj64KgQ8dkTm8-Aq5monZejiGHAuenrIuDovugsUnncYRtFHLY_bmEtKpBDoaswti5UnDOkiVHAuhMMPlqdPBKYwV_LZ3SGFMeznHUrJv5Wg4o4C45yi-1iuOPyDRoSsmhEcimAl3NtJGybSc8y6sdlIiCHg_pUdXqAoXPplQJ-iHcM2h_MTI_3Wkdnw9ucUMR5UCgFMAE; kuaishou.server.web_ph=b3651a369fb9eb9f33d30ccc2cc691a5ecbf',
'Host': 'www.kuaishou.com',
'Origin': 'https://www.kuaishou.com',
'Referer': 'https://www.kuaishou.com/search/video?searchKey=%E6%85%A2%E6%91%87',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
"User-Agent": ua
}
# 關鍵詞
keyword = input("請輸入你想要查詢的關鍵詞:")
# 實現翻頁
for page_num in range(1, 6):
data = {
'operationName': "visionSearchPhoto",
'query': "query visionSearchPhoto($keyword: String, $pcursor: String, $searchSessionId: String, $page: String, $webPageArea: String) {\n visionSearchPhoto(keyword: $keyword, pcursor: $pcursor, searchSessionId: $searchSessionId, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n type\n author {\n id\n name\n following\n headerUrl\n headerUrls {\n cdn\n url\n __typename\n }\n __typename\n }\n tags {\n type\n name\n __typename\n }\n photo {\n id\n duration\n caption\n likeCount\n realLikeCount\n coverUrl\n photoUrl\n liked\n timestamp\n expTag\n coverUrls {\n cdn\n url\n __typename\n }\n photoUrls {\n cdn\n url\n __typename\n }\n animatedCoverUrl\n stereoType\n videoRatio\n __typename\n }\n canAddComment\n currentPcursor\n llsid\n status\n __typename\n }\n searchSessionId\n pcursor\n aladdinBanner {\n imgUrl\n link\n __typename\n }\n __typename\n }\n}\n",
'variables': {
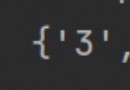
'keyword': keyword, 'pcursor': f'{
page_num}', 'page': "search"}
}
# 'content-type' :'application/json' 要求返回的data是一個json字符串-->字典類型
# print(type(data))
data = json.dumps(data) # 將字典類型轉換為字符串類型
# print(type(data))
time.sleep(2)
try:
url = "https://www.kuaishou.com/graphql"
# 發送一個post請求,url:鏈接地址,headers:偽裝,data:查詢參數
# 1.發送網絡請求
response = requests.post(url=url, headers=headers, data=data)
# 2.獲取數據
json_data = response.json()
# pprint.pprint(json_data)
# 3.解析數據--提取視頻地址及標題
# 字典類型--鍵值對的方式取值
feeds_list = json_data['data']['visionSearchPhoto']['feeds']
# print(len(feeds_list))
# print(feeds_list)
for feeds in feeds_list:
# feeds是字典類型
# 獲取視頻標題
title = feeds['photo']['caption']
photoUrl = feeds['photo']['photoUrl']
# print(title, photoUrl)
# 在Windows操作系統中,文件名不能包含一些特殊字符,需要進行替換
new_title = re.sub(r'[\/:*?"<>|\n]', '_', title)
# 4.發送網絡請求:請求每一個視頻地址,獲取視頻二進制數據
mp4_data = requests.get(photoUrl).content
# 5.保存視頻
with open(dir_name + "/" + new_title + '.mp4', mode='wb') as f:
f.write(mp4_data)
print(f'{
new_title}--下載完成')
if len(feeds_list) < 20:
break
except Exception as e:
print(e)
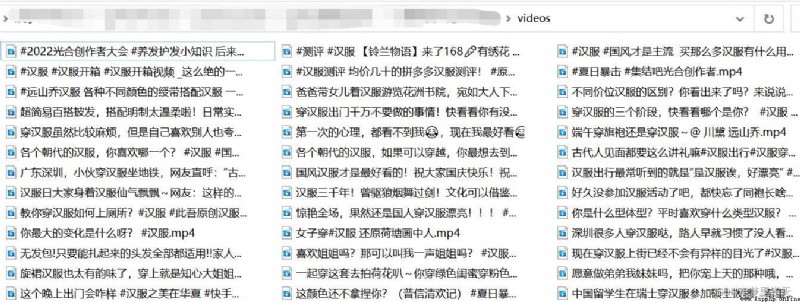
爬取效果: