序列是一種數據存儲方式,用來存儲一系列的數據。在內存中,序列就是一塊用來存放多個值的連續空間。比如一個整數序列:[10,20,30,40]。可以這樣表示:
由於Python3中一切皆對象,在內存中實際是按照如下方式儲存的:
a=[10,20,30,40]

從圖示中我們可以看出,序列中存儲的是整數對象的地址,而不是整數對象的值。
Python3常用的序列對象有:
字符串、元組、列表、字典、集合
列表:用於存儲任意數目、任意類型的數據集合。
列表是內置可變序列,包含多個元素的有序連續的內存空間。
列表的標准語法格式:a=[10,20,30,40]
其中,10,20,30,40這些稱為:列表a的元素。
列表中的元素可以各不相同,可以是任意類型。比如:a=[10,'20','abc',True]
列表對象常用方法如下:
Python的列表大小可變,根據需要隨時增加或縮小。
字符串和列表都是序列類型,一個字符串是一個字符序列,一個列表是任何元素的序列。在字符串中的很多方法,在列表中也有類似的用法,幾乎一模一樣。

使用list()可以將任何可迭代的數據類型裝換為列表。

range()可以幫助我們非常方便的創建整數列表,這個在開發中極具作用。語法格式為:
range([start,] end [,step])
start參數:可選,表示起始數字。默認是0
end參數:必選,表示結尾數字(不包括該數字,左閉右開)
step參數:可選,表示步長,默認為1
Python3中range()返回的是一個range對象,而不是列表。我們需要通過list()方法將其轉換成列表對象。

使用推導式可以非常方便的創建列表,在開發中經常使用,需要涉及到for和if語句。

當列表增加和刪除元素是,列表會自動進行內存管理,大大減少了程序員的負擔,但這個特點設計列表元素的大量移動,效率較低。除非必要我們一般只在列表的尾部添加元素或刪除元素,這樣會大大提高變成效率。
原地修改列表對象,真正在列表尾部添加新的元素,速度最快,推薦使用。
此方法不創建新的對象!

並不是真正的尾部添加元素,而是創建新的列表對象;將原列表的元素的新列表的元素依次復制到新的列表中。這樣,會涉及大量的復制操作,對於操作大量元素不建議使用。

通過如上測試,我們發現變量a的地址發生了變化。也就是創建了新的列表對象。
將目標列表的所有元素添加到原列表的尾部,屬於原地操作,不創建新的列表對象。

使用insert()方法可以將指定位置元素插入到列表對象的任意指定位置。這樣會讓插入位置後面所有的元素進行移動,會影響處理速度。設計大量元素移動是,盡量表面使用。
list.insert(index,x)
在列表list的index位置處插入元素x
注:指定位置index既可以正向搜索,也可以反向搜索。
index >= len(list),此時是在隊尾插入;
index < -len(list),此時是在隊頭插入。

類似發生這種移動的函數還有remove()、pop()、del()。它們在刪除非尾部元素時也會發生操作位置後面元素的移動。
使用乘法擴展列表,生成一個新列表,新列表元素為原列表的多次重復,返回該新列表。

適用於乘法擴展的,還有字符串、元組等。

del list[index]
刪除原列表中指定位置的元素。

注:index可以是正向搜索,也可以是反向搜索,但要求index合法,否者拋出異常。

pop()刪除院原列表指定位置元素,如果未指定則默認操作列表最後一個元素,返回被刪除的元素。指定位置同樣既可以正向搜索,也可以反向搜索,要求合法,否者拋出異常。
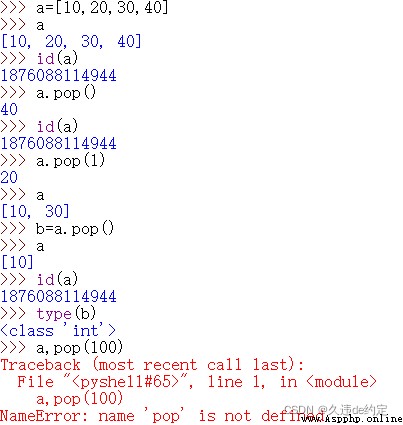
刪除首次出現的指定元素,若該元素不存在則拋出異常。
remove()方法沒有返回值!!!即返回的是None

我們可以直接通過索引直接訪問元素。索引的區間長度在[0,列表長度-1]或[-列表長度,-1]這個范圍。超過這個范圍則會拋出異常。

index()可以獲得指定元素在列表中首次出現的索引。若指定元素不出現則拋出異常。
語法是:index(value,[start,[end]])
其中start和end指定了搜索的范圍,遵循著左閉右開的原則,[start,end)。
注:搜索范圍同樣可以正向搜索,也可以反向搜索。

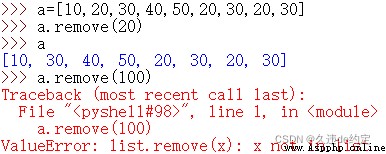
count()可以返回指定元素在列表中出現的次數。
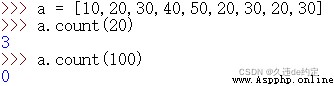
判斷列表中是否存在指定的元素,我們可以使用count()方法,返回0則表示不存在,返回大於0則表示存在。但是,一般我們會使用更簡潔的in關鍵字來判斷,直接返回True或False。
列表的切片操作和字符串類似。
切片slice操作可以讓我們快速提取子列表或修改。標准格式為:
[起始偏移量start:終止偏移量end[:步長]]
注:當步長省略時數遍你可以省略第二個冒號。左閉右開,也可以說是包頭不包尾。
典型操作(三個數為正數):
[20, 40, 60]
其它操作(三個量為負數)的情況:
倒數第五個到倒數第四個
(包頭不包尾)
[30, 40][10,20,30,40,50,60,70][::-1]步長為負,從右到左反向提取[70, 60, 50, 40, 30, 20, 10]切片操作時,起始偏移量和終止偏移量不在[0:字符串長度]這個范圍,也不會報錯。起始偏移量小於0則會被當作0,終止偏移量大於“長度”會被當成“長度”。例如:
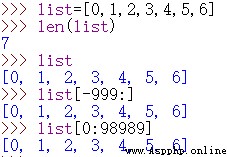
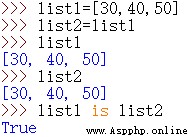
如下代碼是否實現列表元素復制?
list1=[30,40,50]
list2=list1只是將list2也指向了list1指向的對象,也就是說list1和list2持有地址值是相同的,列表元素本身並沒有復制。
可以通過如下簡單方式,實現列表元素內容的復制:
list1=[30,40,50,60]
list2=[]+list1
還可以使用copy模塊,使用淺復制或深復制實現復制操作。
使用sort()方法,修改原列表,不新建列表的排序。sort()方法無返回值。

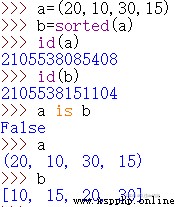
通過使用內置函數sorted()進行排序,這個方法返回新列表,不對原列表進行修改。

通過上面操作,可以看出生成的列表對象b和c都是完全新的列表對象。
內置函數reversed()也支持逆序排序嗎,與列表對象reverse()方法不同的是,內置函數reversed()不對原列表做任何修改,只是返回一個逆序列表的迭代器對象。

用於返回列表中的最大值和最小值

對數值型列表的所有元素進行求和操作,對非數值列表則會報錯。

一維列表可以幫助我們存儲一維、線性的數據。
二維列表可以幫助我們存儲而二維、表格的數據。
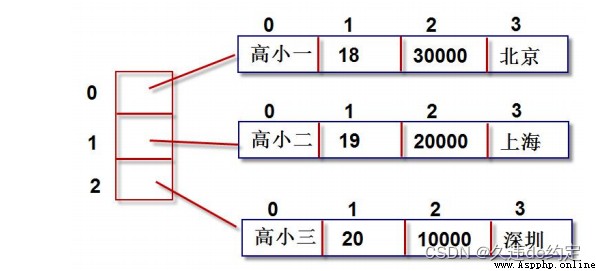
例如下表的數據:
源碼:
a=[
["高小一",18,30000,"北京"],
["高小二",19,20000,"上海"],
["高小一",20,10000,"深圳"]
]內存結構圖:

列表屬於可變序列,可以任意修改列表中的元素。元組屬於不可變序列,不能修改元組中的元素。因此,元組沒有增加元素、修改元素、刪除元素相關的方法。
在元組中重點掌握元組的創建和刪除,元組中元素的訪問和計數即可。
元組支持以下操作:
1.索引訪問
2.切片操作
3.連接操作
4.成員關系操作
5.比較運算操作
6.計數:元組長度len()、最大值max()、最小值min()、求和sum()等。
1.通過()創建元組。小括號可以省去。
a=(10,20,30) 或者 a= 10,20,30
如果元組只有一個元素,則必須後面加逗號。這時因為解釋器會把(1)解釋我整數1,(1,)解釋為元組。

2.通過tuple()創建元組
tuple(可迭代的對象)
例如:

總結:
tuple()可以接受列表、字符串、其他序列類型、迭代器等生成組。
list()可以接受元組、字符串、其他序列類型、迭代器生成列表。
1.元組的元素不能修改
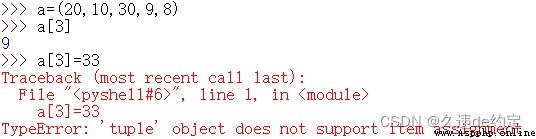
2.元組的元素訪問和列表一樣,只不過返回的依然是元組對象。

3.列表關於排序的方法list.sort()是修改原列表對象,元組沒有該方法。如果要對元組排序,只能使用內置函數sorted(tupleObj),並生成新的列表對象。
zip(列表1,列表2,……)將多個列表對應位置的元素組合成為元組,並返回這個zip對象。

從形式上看,生成器推導和列表推導類似,只是生成器推導式使用小括號。列表推導式直接生成列表對象,生成器推導式生成的不是列表也不是元組,而是一個生成器對象。
我們可以通過生成器對象,轉化成列表或者元組。也可以使用生成器對象_next_()方法進行遍歷,或者直接作為迭代器對象來使用。不管什麼方式使用,元素訪問結束後,如果需要重新訪問其中元素,必須重新創建生成器對象。
生成器使用測試:

1.元組的核心是不可變序列。
2.元組的訪問和處理速度比列表快。
3.與整數和字符串一樣,元組可以作為字典的鍵,列表則永遠不能作為字典的鍵使用。
字典是“鍵值對”的無序可變序列,字典中的每一元素都是一個“鍵值對”,包含:“鍵對象”和“值對象”。我們可以通過“鍵對象”實現快速獲取、刪除、更新對應的“值對象”。
列表中我們通過“下標數字”找到對應的對象。字典中通過“鍵對象”找到對應的“值對象”。“鍵”是任意不可變數據類型,比如:整數、浮點數、字符串、元組。但是:列表、字典、集合這些可變對象,不能作為“鍵”。並且“鍵”不可重復。
一個典型的字典的定義方式:
a={'name':'phh','age':18,'job':'programmer'}
1.我們可以通過{}、dict()來創建字典對象。

2.通過zip()創建字典對象

3.通過fromkeys創建值為空的字典

為了測試各種訪問方法,我們這裡設定一個字典對象:
a={'name':'phh','age':18,'job':'programmer'}
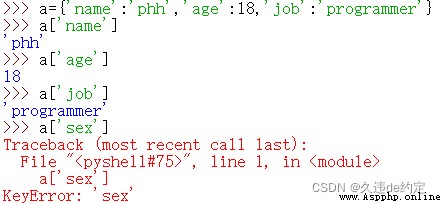
1.通過 [鍵] 獲得 “值”。若鍵不存在,則拋出異常。
2.通過get()方法獲得“值”。推薦使用。優點是:指定鍵不存在,返回None;也可以設定指定鍵不存在是默認返回的對象。推薦使用get()獲取“值對象”。

3.列出所有的鍵值對
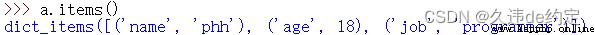
4.列出所有的鍵,列出所有的值。

5.len() 鍵值的數目
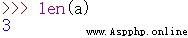
6.檢測一個“鍵”是否在字典中。
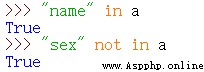
1.給字典新增“鍵值對”。
如果“鍵”已經存在,則覆蓋舊的鍵值對;如果“鍵”不存在,則新增“鍵值對”。

2.如果使用update()將字典中所有鍵值對全圖添加到舊字典上。如果key值有重復,則直接覆蓋。

3.字典中元素的刪除,可以使用del()方法;或者使用clear()刪除所有鍵值對;pop()刪除指定鍵值對,並返回對應的“值對象”。

4.popitem()隨機刪除和返回該鍵值對。字典是“無序可變序列”,因此沒有第一個元素、最後一個元素的概念;popitem彈出隨機的項,因為字典並沒有“最後的元素”或則其它有關順序的概念。若想一個接一個地移除處理項,這個方法就非常有效(因為不用獲取鍵的列表)。
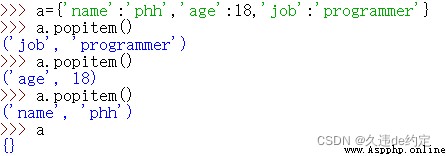
序列解包可以用於元組、列表、字典。序列解可以讓我們方便對多個變量賦值。

序列解包用於字典時,默認是對'“鍵”進行操作;如果需要對鍵值進行操作,則需要使用items();如果需要對“值”進行操作,則需要使用values()。

源代碼:
r1 = {"name":"高小一","age":18,"salary":30000,"city":"北京"}
r2 = {"name":"高小二","age":19,"salary":20000,"city":"上海"}
r3 = {"name":"高小五","age":20,"salary":10000,"city":"深圳"}
tb = [r1,r2,r3]
#獲得第二行的人的薪資
print(tb[1].get("salary"))
#打印表中所有的的薪資
for i in range(len(tb)): # i -->0,1,2
print(tb[i].get("salary"))
#打印表的所有數據
for i in range(len(tb)):
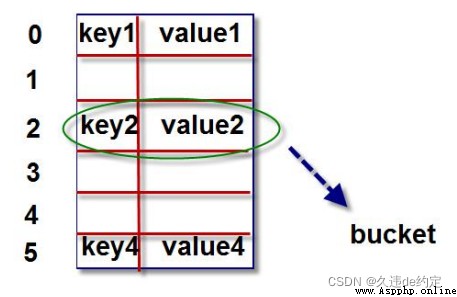
print(tb[i].get("name"),tb[i].get("age"),tb[i].get("salary"),tb[i].get("city"))字典的核心是散列表。散列表是一個稀疏數組(總是有空白的數組),數組的每個單元叫做bucket有兩部分:一個是鍵對象的引用,一個是值對象的引用。
由於,所有bucket結構和大小一致,我們可以通過偏移量來讀取指定
明白一個鍵值對是如何存儲到數組中,根據鍵對象取到值對象,理解起來就簡單了。

當我們a.get('name'),就是根據鍵‘name'查找到“鍵值對”,從而找到值對象'phh'。
第一步,計算‘name’對象的散列值:
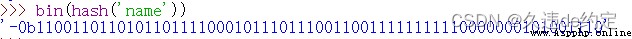
用法總結:
1.鍵必須可散列
(1) 數字、字符串、元組,都是可散列的。
(2) 自定義對象需要支持下面三點:
支持hash()函數
支持通過__eq__()方法檢測相等性。
若a==b為真,則hash(a)==hash(b)為真。
2.字典在內存中開銷巨大,典型的空間換時間。
3.鍵查詢速度很快。
4.往字典添加新鍵可能導致擴容,導致散列中鍵的次序變化。因此,不要在遍歷字典的同時進行字典的修改。
集合是無序可變,元素不能重復。實際上,集合底層是字典實現,集合所有元素都是字典中的“鍵對象”,因此是不能重復且唯一的。
1.使用{}創建對象,並使用add()方法添加元素。
在使用add()方法時,添加已經存在集合中元素不會拋出異常。

2.使用set(),將列表、元組等可迭代對象轉為集合。如果原數據存在重復數據,則值保留一個。

3.remove()刪除指定元素;clear()清空整個集合。

像數學中概念一樣,Python對集合也提供了並集、交集、差集等運算。