基本思想:一直想學tensorRT開發,沒時間,最近有時間,學習一下TensorRT開發,Most of the information for this article comes from the Internet and manuals,for the purpose of learning,Facilitate the achievement of your mission goals
測試環境 筆記本 11th Gen Intel Core i5-11260H @ 2.60GHz × 12 RTX3050 4G顯存
第一步:基本的tensorRT結構分析.參考https://www.jianshu.com/p/3c2fb7b45cc7
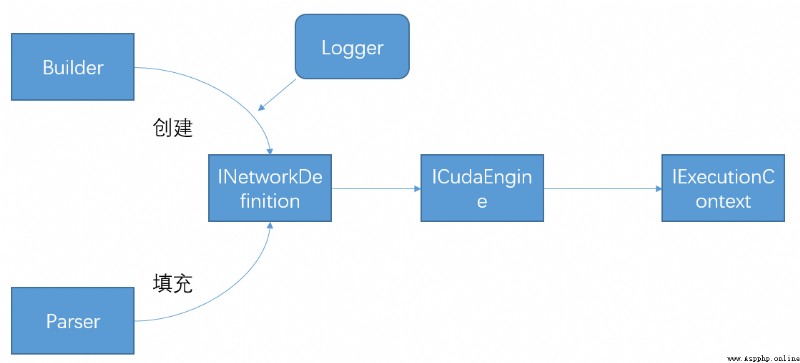
1)首先以trt的Logger為參數,使用builderCreate a computational graph typeINetworkDefinition. 2)然後使用Parsers將onnxUnder the framework of network structure such as filling calculation chart,當然也可以使用tensorrt的API進行構建. 3)Created from Computational Graphscudaengine in the environment 4)The final reasoning is thatcuda引擎生成的ExecutionContext.engine.create_execution_context()
add a testonnxtest time code
import matplotlib.pyplot as plt
from torch.autograd import Variable
from argparse import ArgumentParser
import torch
import torch.utils.data
import onnxruntime
import cv2
import numpy as np
from onnxruntime.datasets import get_example
import torch.nn.functional as F
import math
from model.orienmask_yolo_fpnplus import OrienMaskYOLOFPNPlus
from utils.visualizer import InferenceVisualizer
from torch.nn.modules.utils import _pair
from eval.function import batched_nms
from eval.orienmask_yolo_postprocess import OrienMaskYOLOPostProcess
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
import os
envpath = '/home/ubuntu/.local/lib/python3.8/site-packages/cv2/qt/plugins/platforms'
os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = envpath
def pad(image, size_divisor=32, pad_value=0):
height, width = image.shape[-2:]
new_height = int(math.ceil(height / size_divisor) * size_divisor)
new_width = int(math.ceil(width / size_divisor) * size_divisor)
pad_left, pad_top = (new_width - width) // 2, (new_height - height) // 2
pad_right, pad_down = new_width - width - pad_left, new_height - height - pad_top
padding = [pad_left, pad_right, pad_top, pad_down]
image = F.pad(image, padding, value=pad_value)
pad_info = padding + [new_height, new_width]
return image, pad_info
def torch2onnx(args, model):
import datetime
start_load_data = datetime.datetime.now()
img_src=cv2.imread(args.img)
img_color = cv2.cvtColor(img_src, cv2.COLOR_BGR2RGB)
src_tensor = torch.tensor(img_color, device=device,dtype=torch.float32)
img_resize = cv2.resize(img_color, (544, 544),cv2.INTER_LINEAR)
input = np.transpose(img_resize, (2, 0, 1)).astype(np.float32)
input[0, ...] = (input[0, ...] - 0) / 255 # la
input[1, ...] = (input[1, ...] - 0) / 255
input[2, ...] = (input[2, ...] - 0) / 255
now_image= Variable(torch.from_numpy(input))
dummy_input = now_image.unsqueeze(0).to(device)
dummy_input, pad_info = pad(dummy_input)
end_load_data = datetime.datetime.now()
print("load data:", (end_load_data - start_load_data).microseconds / 1000, "ms")
start_convert = datetime.datetime.now()
torch.onnx.export(model, dummy_input, args.onnx_model_path, input_names=["input"],
export_params=True,
keep_initializers_as_inputs=True,
do_constant_folding=True,
verbose=False,
opset_version=11)
end_convert = datetime.datetime.now()
print("convert model:", (end_convert - start_convert).microseconds / 1000, "ms")
start_load = datetime.datetime.now()
example_model = get_example(args.onnx_model_path)
end_load = datetime.datetime.now()
print("load model:", (end_load - start_load).microseconds / 1000, "ms")
start_Forward = datetime.datetime.now()
session = onnxruntime.InferenceSession(example_model)
input_name = session.get_inputs()[0].name
result = session.run([], {input_name: dummy_input.data.cpu().numpy()})
result_tuple=((torch.tensor(result[0],device=device),torch.tensor(result[1],device=device)),
(torch.tensor(result[2],device=device),torch.tensor(result[3],device=device)),
(torch.tensor(result[4],device=device),torch.tensor(result[5],device=device)))
pred_bbox_batch=[torch.tensor(result[0],device=device),torch.tensor(result[2],device=device),torch.tensor(result[4],device=device)]
pred_orien_batch=[torch.tensor(result[6],device=device),torch.tensor(result[7],device=device),torch.tensor(result[8],device=device)]
self_grid_size = [[17, 17], [34, 34], [68, 68]]
self_image_size = [544, 544]
self_anchors = [[12, 16], [19, 36], [40, 28], [36, 75], [76, 55], [72, 146], [142, 110], [192, 243], [459, 401]]
self_anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
self_num_classes = 80
self_conf_thresh = 0.05
self_nms_func = None
self_nms_pre = 400
self_nms_post = 100
self_orien_thresh = 0.3
item_Orien=OrienMaskYOLOPostProcess(self_grid_size, self_image_size, self_anchors, self_anchor_mask, self_num_classes,
self_conf_thresh, self_nms_func, self_nms_pre,
self_nms_post, self_orien_thresh, device)
predictions =item_Orien.apply(result_tuple,pred_bbox_batch,pred_orien_batch)
end_Forward = datetime.datetime.now()
print("Forward & Postprocess:", (end_Forward - start_Forward).microseconds / 1000, "ms")
start_visual = datetime.datetime.now()
dataset='COCO'
with_mask=True
conf_thresh=0.3
alpha=0.6
line_thickness=1
ifer_item=InferenceVisualizer(dataset,device, with_mask,conf_thresh,alpha,line_thickness)
show_image = ifer_item.__call__(predictions[0], src_tensor,pad_info)
plt.imsave(args.onnxoutput, show_image)
end_visual =datetime.datetime.now()
print("Visualize::", (end_visual - start_visual).microseconds/1000, "ms")
def main():
"""Test a single image."""
parser = ArgumentParser()
parser.add_argument('--img', default="/home/ubuntu/OrienMask/assets/000000163126.jpg",
help='Image file')
parser.add_argument('--weights', default="/home/ubuntu/CLionProjects/D435_OrienMask/model/orienmask_yolo.pth",
help='Checkpoint file')
parser.add_argument('--onnx_model_path',
default="/home/ubuntu/CLionProjects/D435_OrienMask/model/orienmask_yolo.onnx",
help='onnx_model_path')
parser.add_argument('--device', default='cuda:0', help='Device used for inference')
parser.add_argument('--onnxoutput', default=r'onnxsxj731533730.jpg', help='Output image')
parser.add_argument('--num_anchors', type=int, default=3, help='num_anchors')
parser.add_argument('--num_classes', type=int, default=80, help='num_classes')
args = parser.parse_args()
model=OrienMaskYOLOFPNPlus(args.num_anchors,args.num_classes).to(device)
weights = torch.load(args.weights, map_location=device)
weights = weights['state_dict'] if 'state_dict' in weights else weights
model.load_state_dict(weights, strict=True)
torch2onnx(args, model)
if __name__ == '__main__':
main()第一步:轉模型
import tensorrt as trt
def build_engine(onnx_file_path,engine_file_path,half=False):
"""Takes an ONNX file and creates a TensorRT engine to run inference with"""
logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(logger)
config = builder.create_builder_config()
config.max_workspace_size = 4 * 1 << 30
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
network = builder.create_network(flag)
parser = trt.OnnxParser(network, logger)
if not parser.parse_from_file(str(onnx_file_path)):
raise RuntimeError(f'failed to load ONNX file: {onnx_file_path}')
half &= builder.platform_has_fast_fp16
if half:
config.set_flag(trt.BuilderFlag.FP16)
with builder.build_engine(network, config) as engine, open(engine_file_path, 'wb') as t:
t.write(engine.serialize())
return engine_file_path
if __name__ =="__main__":
onnx_file_path = "/home/ubuntu/CLionProjects/D435_OrienMask/model/orienmask_yolo_sim.onnx"
engine_file_path = "/home/ubuntu/CLionProjects/D435_OrienMask/model/orienmask_yolo_sim.engine"
build_engine(onnx_file_path,engine_file_path,True)轉換結果 注意 If there is not enough space,需要修改配置項,將30 改小一點
config.max_workspace_size = 4 * 1 << 30轉換過程
/usr/bin/python3.8 /home/ubuntu/OrienMask/onnx2trt.py
[TensorRT] WARNING: TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
[TensorRT] INFO: Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
[TensorRT] INFO: Detected 1 inputs and 9 output network tensors.
[TensorRT] WARNING: TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
Process finished with exit code 0
Test result data comparison
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
from pycuda.tools import make_default_context
import torch
import numpy as np
import math
import torch.nn.functional as F
import cv2
from torch.autograd import Variable
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def load_engine(engine_path):
# TRT_LOGGER = trt.Logger(trt.Logger.WARNING) # INFO
TRT_LOGGER = trt.Logger(trt.Logger.ERROR)
with open(engine_path, 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def pad(image, size_divisor=32, pad_value=0):
height, width = image.shape[-2:]
new_height = int(math.ceil(height / size_divisor) * size_divisor)
new_width = int(math.ceil(width / size_divisor) * size_divisor)
pad_left, pad_top = (new_width - width) // 2, (new_height - height) // 2
pad_right, pad_down = new_width - width - pad_left, new_height - height - pad_top
padding = [pad_left, pad_right, pad_top, pad_down]
image = F.pad(image, padding, value=pad_value)
pad_info = padding + [new_height, new_width]
return image, pad_info
img_src = cv2.imread('/home/ubuntu/OrienMask/assets/000000163126.jpg')
img_color = cv2.cvtColor(img_src, cv2.COLOR_BGR2RGB)
img_resize = cv2.resize(img_color, (544, 544), cv2.INTER_LINEAR)
input = np.transpose(img_resize, (2, 0, 1)).astype(np.float32)
input[0, ...] = (input[0, ...] - 0) / 255 # la
input[1, ...] = (input[1, ...] - 0) / 255
input[2, ...] = (input[2, ...] - 0) / 255
now_image = Variable(torch.from_numpy(input))
dummy_input = now_image.unsqueeze(0)
dummy_input, pad_info = pad(dummy_input)
image=np.array(dummy_input.contiguous())
path = "/home/ubuntu/CLionProjects/D435_OrienMask/model/orienmask_yolo_sim.engine"
# 1. 建立模型,構建上下文管理器
engine = load_engine(path)
context = engine.create_execution_context()
context.active_optimization_profile = 0
# 3.分配內存空間,並進行數據cpu到gpu的拷貝
# 動態尺寸,每次都要set一下模型輸入的shape,0代表的就是輸入,輸出根據具體的網絡結構而定,可以是0,1,2,3...其中的某個頭.
context.set_binding_shape(0, image.shape)
d_input = cuda.mem_alloc(image.nbytes) # 分配輸入的內存.
output_shape_1 = context.get_binding_shape(1)
output_shape_2 = context.get_binding_shape(2)
output_shape_3 = context.get_binding_shape(3)
output_shape_4 = context.get_binding_shape(4)
output_shape_5 = context.get_binding_shape(5)
output_shape_6 = context.get_binding_shape(6)
output_shape_7 = context.get_binding_shape(7)
output_shape_8 = context.get_binding_shape(8)
output_shape_9 = context.get_binding_shape(9)
buffer_1 = np.empty(output_shape_1, dtype=np.float32)
buffer_2 = np.empty(output_shape_2, dtype=np.float32)
buffer_3 = np.empty(output_shape_3, dtype=np.float32)
buffer_4 = np.empty(output_shape_4, dtype=np.float32)
buffer_5 = np.empty(output_shape_5, dtype=np.float32)
buffer_6 = np.empty(output_shape_6, dtype=np.float32)
buffer_7 = np.empty(output_shape_7, dtype=np.float32)
buffer_8 = np.empty(output_shape_8, dtype=np.float32)
buffer_9 = np.empty(output_shape_9, dtype=np.float32)
d_output_1 = cuda.mem_alloc(buffer_1.nbytes) # 分配輸出內存.
d_output_2 = cuda.mem_alloc(buffer_2.nbytes) # 分配輸出內存
d_output_3 = cuda.mem_alloc(buffer_3.nbytes) # 分配輸出內存
d_output_4 = cuda.mem_alloc(buffer_4.nbytes) # 分配輸出內存
d_output_5 = cuda.mem_alloc(buffer_5.nbytes) # 分配輸出內存
d_output_6 = cuda.mem_alloc(buffer_6.nbytes) # 分配輸出內存
d_output_7 = cuda.mem_alloc(buffer_7.nbytes) # 分配輸出內存
d_output_8 = cuda.mem_alloc(buffer_8.nbytes) # 分配輸出內存
d_output_9 = cuda.mem_alloc(buffer_9.nbytes) # 分配輸出內存
cuda.memcpy_htod(d_input, image)
bindings = [d_input, d_output_1,d_output_2,d_output_3,d_output_4,d_output_5,d_output_6,d_output_7,d_output_8,d_output_9]
# 4.進行推理,並將結果從gpu拷貝到cpu.
context.execute_v2(bindings) # 可異步和同步
cuda.memcpy_dtoh(buffer_1, d_output_1)
output_1 = buffer_1.reshape(output_shape_1)
print(output_1.shape)
cuda.memcpy_dtoh(buffer_2, d_output_2)
output_2 = buffer_2.reshape(output_shape_2)
print(output_2.shape)
cuda.memcpy_dtoh(buffer_3, d_output_3)
output_3 = buffer_3.reshape(output_shape_3)
print(output_3.shape)
cuda.memcpy_dtoh(buffer_4, d_output_4)
output_4 = buffer_4.reshape(output_shape_4)
print(output_4.shape)
cuda.memcpy_dtoh(buffer_5, d_output_5)
output_5 = buffer_5.reshape(output_shape_5)
print(output_5.shape)
cuda.memcpy_dtoh(buffer_6, d_output_6)
output_6 = buffer_6.reshape(output_shape_6)
print(output_6.shape)
cuda.memcpy_dtoh(buffer_7, d_output_7)
output_7 = buffer_7.reshape(output_shape_7)
print(output_7.shape)
cuda.memcpy_dtoh(buffer_8, d_output_8)
output_8 = buffer_8.reshape(output_shape_8)
print(output_8.shape)
cuda.memcpy_dtoh(buffer_9, d_output_9)
output_9 = buffer_9.reshape(output_shape_9)
print(output_9.shape)
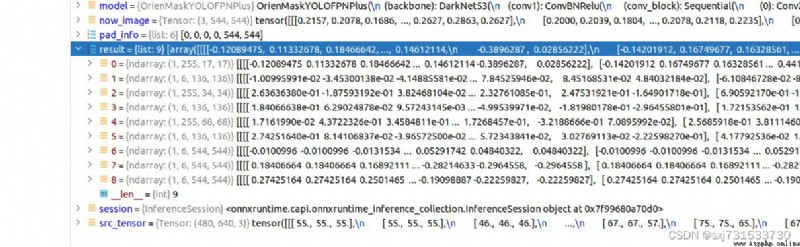
數據比對onnx和tengine是一致的,onnx的數據
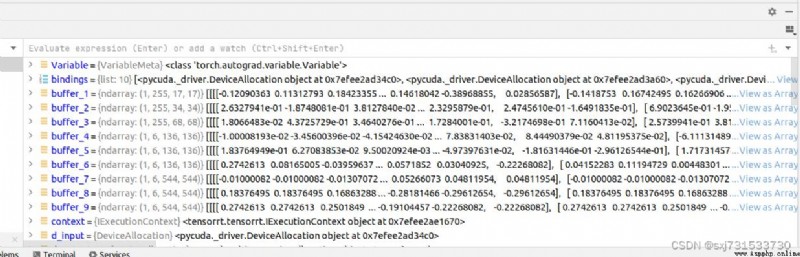
engine的數據
測試一下時間,Comparing only inference time,post-processing consistent engineComplete inference code(model with rotation)
import datetime
import tensorrt as trt
import matplotlib.pyplot as plt
import pycuda.driver as cuda
import pycuda.autoinit
from pycuda.tools import make_default_context
import torch
import numpy as np
import math
import torch.nn.functional as F
import cv2
from torch.autograd import Variable
from argparse import ArgumentParser
from eval.orienmask_yolo_postprocess import OrienMaskYOLOPostProcess
from utils.visualizer import InferenceVisualizer
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def build_engine(onnx_file_path,engine_file_path,half=False):
"""Takes an ONNX file and creates a TensorRT engine to run inference with"""
logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(logger)
config = builder.create_builder_config()
config.max_workspace_size = 4 * 1 << 20
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
network = builder.create_network(flag)
parser = trt.OnnxParser(network, logger)
if not parser.parse_from_file(str(onnx_file_path)):
raise RuntimeError(f'failed to load ONNX file: {onnx_file_path}')
half &= builder.platform_has_fast_fp16
if half:
config.set_flag(trt.BuilderFlag.FP16)
with builder.build_engine(network, config) as engine, open(engine_file_path, 'wb') as t:
t.write(engine.serialize())
return engine_file_path
def load_engine(engine_path):
# TRT_LOGGER = trt.Logger(trt.Logger.WARNING) # INFO
TRT_LOGGER = trt.Logger(trt.Logger.ERROR)
with open(engine_path, 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def pad(image, size_divisor=32, pad_value=0):
height, width = image.shape[-2:]
new_height = int(math.ceil(height / size_divisor) * size_divisor)
new_width = int(math.ceil(width / size_divisor) * size_divisor)
pad_left, pad_top = (new_width - width) // 2, (new_height - height) // 2
pad_right, pad_down = new_width - width - pad_left, new_height - height - pad_top
padding = [pad_left, pad_right, pad_top, pad_down]
image = F.pad(image, padding, value=pad_value)
pad_info = padding + [new_height, new_width]
return image, pad_info
def onnx2engine(args):
start_convert = datetime.datetime.now()
build_engine(args.onnx_model_path, args.engine_file_path, args.fp16)
end_convert = datetime.datetime.now()
print("convert model:",(end_convert - start_convert).microseconds/1000,"ms")
start_load_data = datetime.datetime.now()
img_src = cv2.imread(args.img)
img_color = cv2.cvtColor(img_src, cv2.COLOR_BGR2RGB)
img_resize = cv2.resize(img_color, (544, 544), cv2.INTER_LINEAR)
input = np.transpose(img_resize, (2, 0, 1)).astype(np.float32)
input[0, ...] = (input[0, ...] - 0) / 255 # la
input[1, ...] = (input[1, ...] - 0) / 255
input[2, ...] = (input[2, ...] - 0) / 255
now_image = Variable(torch.from_numpy(input))
dummy_input = now_image.unsqueeze(0)
dummy_input, pad_info = pad(dummy_input)
image=np.array(dummy_input.contiguous())
end_load_data = datetime.datetime.now()
print("load data:", (end_load_data - start_load_data).microseconds / 1000, "ms")
start_load = datetime.datetime.now()
# 1. 建立模型,構建上下文管理器
engine = load_engine(args.engine_file_path)
end_load = datetime.datetime.now()
print("load model:", (end_load - start_load).microseconds/1000, "ms")
start_Forward = datetime.datetime.now()
context = engine.create_execution_context()
context.active_optimization_profile = 0
# 3.分配內存空間,並進行數據cpu到gpu的拷貝
# 動態尺寸,每次都要set一下模型輸入的shape,0代表的就是輸入,輸出根據具體的網絡結構而定,可以是0,1,2,3...其中的某個頭.
context.set_binding_shape(0, image.shape)
d_input = cuda.mem_alloc(image.nbytes) # 分配輸入的內存.
output_shape_1 = context.get_binding_shape(1)
output_shape_2 = context.get_binding_shape(2)
output_shape_3 = context.get_binding_shape(3)
output_shape_4 = context.get_binding_shape(4)
output_shape_5 = context.get_binding_shape(5)
output_shape_6 = context.get_binding_shape(6)
output_shape_7 = context.get_binding_shape(7)
output_shape_8 = context.get_binding_shape(8)
output_shape_9 = context.get_binding_shape(9)
buffer_1 = np.empty(output_shape_1, dtype=np.float32)
buffer_2 = np.empty(output_shape_2, dtype=np.float32)
buffer_3 = np.empty(output_shape_3, dtype=np.float32)
buffer_4 = np.empty(output_shape_4, dtype=np.float32)
buffer_5 = np.empty(output_shape_5, dtype=np.float32)
buffer_6 = np.empty(output_shape_6, dtype=np.float32)
buffer_7 = np.empty(output_shape_7, dtype=np.float32)
buffer_8 = np.empty(output_shape_8, dtype=np.float32)
buffer_9 = np.empty(output_shape_9, dtype=np.float32)
d_output_1 = cuda.mem_alloc(buffer_1.nbytes) # 分配輸出內存.
d_output_2 = cuda.mem_alloc(buffer_2.nbytes) # 分配輸出內存
d_output_3 = cuda.mem_alloc(buffer_3.nbytes) # 分配輸出內存
d_output_4 = cuda.mem_alloc(buffer_4.nbytes) # 分配輸出內存
d_output_5 = cuda.mem_alloc(buffer_5.nbytes) # 分配輸出內存
d_output_6 = cuda.mem_alloc(buffer_6.nbytes) # 分配輸出內存
d_output_7 = cuda.mem_alloc(buffer_7.nbytes) # 分配輸出內存
d_output_8 = cuda.mem_alloc(buffer_8.nbytes) # 分配輸出內存
d_output_9 = cuda.mem_alloc(buffer_9.nbytes) # 分配輸出內存
cuda.memcpy_htod(d_input, image)
bindings = [d_input, d_output_1,d_output_2,d_output_3,d_output_4,d_output_5,d_output_6,d_output_7,d_output_8,d_output_9]
# 4.進行推理,並將結果從gpu拷貝到cpu.
context.execute_v2(bindings) # 可異步和同步
cuda.memcpy_dtoh(buffer_1, d_output_1)
output_1 = buffer_1.reshape(output_shape_1)
print(output_1.shape)
cuda.memcpy_dtoh(buffer_2, d_output_2)
output_2 = buffer_2.reshape(output_shape_2)
print(output_2.shape)
cuda.memcpy_dtoh(buffer_3, d_output_3)
output_3 = buffer_3.reshape(output_shape_3)
print(output_3.shape)
cuda.memcpy_dtoh(buffer_4, d_output_4)
output_4 = buffer_4.reshape(output_shape_4)
print(output_4.shape)
cuda.memcpy_dtoh(buffer_5, d_output_5)
output_5 = buffer_5.reshape(output_shape_5)
print(output_5.shape)
cuda.memcpy_dtoh(buffer_6, d_output_6)
output_6 = buffer_6.reshape(output_shape_6)
print(output_6.shape)
cuda.memcpy_dtoh(buffer_7, d_output_7)
output_7 = buffer_7.reshape(output_shape_7)
print(output_7.shape)
cuda.memcpy_dtoh(buffer_8, d_output_8)
output_8 = buffer_8.reshape(output_shape_8)
print(output_8.shape)
cuda.memcpy_dtoh(buffer_9, d_output_9)
output_9 = buffer_9.reshape(output_shape_9)
print(output_9.shape)
result_tuple=((torch.tensor(output_1,device=device),torch.tensor(output_4,device=device)),
(torch.tensor(output_2,device=device),torch.tensor(output_5,device=device)),
(torch.tensor(output_3,device=device),torch.tensor(output_6,device=device)))
pred_bbox_batch=[torch.tensor(output_1,device=device),torch.tensor(output_2,device=device),torch.tensor(output_3,device=device)]
pred_orien_batch=[torch.tensor(output_7,device=device),torch.tensor(output_8,device=device),torch.tensor(output_9,device=device)]
self_grid_size = [[17, 17], [34, 34], [68, 68]]
self_image_size = [544, 544]
self_anchors = [[12, 16], [19, 36], [40, 28], [36, 75], [76, 55], [72, 146], [142, 110], [192, 243], [459, 401]]
self_anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
self_num_classes = 80
self_conf_thresh = 0.05
self_nms_func = None
self_nms_pre = 400
self_nms_post = 100
self_orien_thresh = 0.3
item_Orien=OrienMaskYOLOPostProcess(self_grid_size, self_image_size, self_anchors, self_anchor_mask, self_num_classes,
self_conf_thresh, self_nms_func, self_nms_pre,
self_nms_post, self_orien_thresh, device)
predictions =item_Orien.apply(result_tuple,pred_bbox_batch,pred_orien_batch)
end_Forward =datetime.datetime.now()
print("Forward & Postprocess:", (end_Forward - start_Forward ).microseconds/1000, "ms")
start_visual =datetime.datetime.now()
dataset='COCO'
with_mask=True
conf_thresh=0.3
alpha=0.6
line_thickness=1
ifer_item=InferenceVisualizer(dataset,device, with_mask,conf_thresh,alpha,line_thickness)
show_image = ifer_item.__call__(predictions[0], torch.tensor(img_color, device=device, dtype=torch.float32),pad_info)
plt.imsave(args.engineoutput, show_image)
end_visual =datetime.datetime.now()
print("Visualize::", (end_visual - start_visual).microseconds/1000, "ms")
def main():
"""Test a single image."""
parser = ArgumentParser()
parser.add_argument('--img', default="/home/ubuntu/OrienMask/assets/000000163126.jpg",
help='Image file')
parser.add_argument('--onnx_model_path',
default="/home/ubuntu/CLionProjects/D435_OrienMask/model/orienmask_yolo_sim.onnx",
help='onnx_model_path')
parser.add_argument('--engine_file_path',
default="/home/ubuntu/CLionProjects/D435_OrienMask/model/orienmask_yolo_sim.engine",
help='Checkpoint file')
parser.add_argument('--fp16', default=False, help='Device used for inference')
parser.add_argument('--device', default='cuda:0', help='Device used for inference')
parser.add_argument('--engineoutput', default=r'enginesxj731533730.jpg', help='Output image')
parser.add_argument('--num_anchors', type=int, default=3, help='num_anchors')
parser.add_argument('--num_classes', type=int, default=80, help='num_classes')
args = parser.parse_args()
onnx2engine(args)
if __name__ == '__main__':
main()python 對應infer.py pt模型時間
100%|██████████| 1/1 [00:00<00:00, 1.73it/s]
[406, 194, 623, 435] 0.9981989860534668 person
[114, 96, 401, 458] 0.9951344728469849 person
[399, 292, 450, 343] 0.891899049282074 baseball-glove
[379, 61, 531, 178] 0.7934691309928894 baseball-bat
The inference takes 0.5795696411132812 seconds.
The average inference time is 579.57 ms (1.73 fps)
Load data: 7.14ms (140.15fps)
Forward & Postprocess: 543.60ms (1.84fps)
Visualize: 27.46ms (36.42fps)
Process finished with exit code 0onnx的時間
/usr/bin/python3.8 /home/ubuntu/OrienMask/pytorch2onnx.py
load data: 8.894 ms
convert model: 284.689 ms
load model: 0.039 ms
Forward & Postprocess: 610.724 ms
[406, 194, 623, 435] 0.9981685876846313 person
[114, 96, 401, 458] 0.9952691793441772 person
[399, 292, 450, 343] 0.8922784328460693 baseball-glove
[379, 61, 531, 178] 0.7953709363937378 baseball-bat
Visualize:: 17.771 ms
Process finished with exit code 0tensorRT的時間fp32
/usr/bin/python3.8 /home/ubuntu/OrienMask/append_onnx.py
[TensorRT] WARNING: TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
[TensorRT] INFO: Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
[TensorRT] INFO: Detected 1 inputs and 9 output network tensors.
[TensorRT] WARNING: TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
convert model: 904.367 ms
load data: 51.773 ms
load model: 154.13 ms
(1, 255, 17, 17)
(1, 255, 34, 34)
(1, 255, 68, 68)
(1, 6, 136, 136)
(1, 6, 136, 136)
(1, 6, 136, 136)
(1, 6, 544, 544)
(1, 6, 544, 544)
(1, 6, 544, 544)
Forward & Postprocess: 259.426 ms
[406, 194, 623, 435] 0.9981685876846313 person
[114, 96, 401, 458] 0.9952630400657654 person
[399, 292, 450, 343] 0.8922533392906189 baseball-glove
[379, 61, 531, 178] 0.7952889800071716 baseball-bat
Visualize:: 74.835 ms
Process finished with exit code 0tensorRT的時間fp16
/usr/bin/python3.8 /home/ubuntu/OrienMask/append_onnx.py
[TensorRT] WARNING: TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
[TensorRT] INFO: Some tactics do not have sufficient workspace memory to run. Increasing workspace size may increase performance, please check verbose output.
[TensorRT] INFO: Detected 1 inputs and 9 output network tensors.
[TensorRT] WARNING: TensorRT was linked against cuBLAS/cuBLAS LT 11.3.0 but loaded cuBLAS/cuBLAS LT 11.2.1
convert model: 345.526 ms
load data: 40.72 ms
load model: 510.729 ms
(1, 255, 17, 17)
(1, 255, 34, 34)
(1, 255, 68, 68)
(1, 6, 136, 136)
(1, 6, 136, 136)
(1, 6, 136, 136)
(1, 6, 544, 544)
(1, 6, 544, 544)
(1, 6, 544, 544)
Forward & Postprocess: 221.026 ms
[406, 194, 623, 435] 0.9981628656387329 person
[114, 96, 400, 458] 0.9952174425125122 person
[399, 292, 450, 343] 0.8911451101303101 baseball-glove
[379, 61, 531, 178] 0.7952533960342407 baseball-bat
Visualize:: 62.321 ms
Process finished with exit code 0
c++Code to be learned and added
參考:
https://www.jianshu.com/p/3c2fb7b45cc7
Also in trouble for the model to accelerate the reasoning?Might as well look at this article.手把手教你把pytorch模型轉化為TensorRT,加速推理_AI浩的博客-CSDN博客_模型推理加速