能將數據進行可視化,更直觀的呈現
使數據更加客觀,更有說服力
matplotlib:最流行的Python底層繪圖庫,主要做數據可視化圖表,名字取材於MATLAB,模仿MATLAB構建
format_string 由顏色字符、風格字符、標記字符組成
顏色字符
'b' 藍色 'm' 洋紅色 magenta'g' 綠色 'y' 黃色'r' 紅色 'k' 黑色'w' 白色 'c' 青綠色 cyan'#008000' RGB某顏色 '0.8' 灰度值字符串風格字符
'‐' 實線'‐‐' 破折線'‐.' 點劃線':' 虛線'' ' ' 無線條標記字符
'.' 點標記
',' 像素標記(極小點)
'o' 實心圈標記
'v' 倒三角標記
'^' 上三角標記
'>' 右三角標記
'<' 左三角標記…等等
例1:假設一天中每隔兩個小時(range(2,26,2))的氣溫(℃)分別是[15,13,14.5,17,20,25,26,26,27,22,18,15]
from matplotlib import pyplot as plt
# figure圖形圖標的意思,在這裡指的是我們要畫的圖
# 通過實例化一個figure並且傳遞參數,能夠在後台自動使用該figure實例
# 在圖形模糊的時候可以傳入dpi參數,讓圖片更加清晰
# 設置圖片大小
fig = plt.figure(figsize=(20,8),dpi=80)
x = range(2,26,2)
y = [15,13,14.5,17,20,25,26,26,27,22,18,15]
# 繪圖
plt.plot(x,y)
# 設置x軸的刻度
_xtick_lables = [i/2 for i in range(2,49)]
# ::3 代表步長
plt.xticks(_xtick_lables[::3])
plt.yticks(range(min(y),max(y)+1))
# 保存在本地
# 可以保存為svg這種矢量圖格式,放大後不會有鋸齒
# plt.savefig("./t1.png")
# 展示圖形
plt.show()
例2:如果列表a表示10點到12點的每一分鐘的氣溫,如何繪制折線圖觀察每分鐘氣溫的變化情況?
# _*_ coding : utf-8 _*_
# @Time : 2022/7/22
# @Author : 代浩楠
# @File : 02_matplotlib_繪制10點到12點的氣溫
# @Project : PycharmSpace
from matplotlib import pyplot as plt
import random
import matplotlib
from matplotlib import font_manager
# font = {
# 'family': 'MicroSoft YaHei',
# 'weight': 'bold',
# 'size': 'larger'
# }
# matplotlib.rc("font",**font)
# matplotlib.rc("font",family=font.get('family'),weight=font.get('weight'))
# 設置字體
my_font = font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttc')
x = range(0, 120)
y = [random.randint(20, 35) for i in range(120)]
plt.figure(figsize=(20, 8), dpi=80)
plt.plot(x, y)
# 調整x軸的刻度
_x = list(x)
_xtick_lables = ["10點{}分".format(i) for i in range(60)]
_xtick_lables += ["11點{}分".format(i) for i in range(60)]
# 第一個參數:代表著x坐標軸120個刻度,步長為三
# 第二個參數:根據第一個參數來寫出lable值
# rotation表示旋轉的度數
plt.xticks(_x[::3], _xtick_lables[::3], rotation=45,fontproperties=my_font)
# 添加描述信息
plt.xlabel("時間",fontproperties=my_font)
plt.ylabel("溫度 單位(℃)",fontproperties=my_font)
plt.title("10點到12點每分鐘的氣溫變化情況",fontproperties=my_font)
plt.show()
例3:假設大家在30歲的時候,根據自己的實際情況,統計出來了你和你同桌各自從11歲到30歲每年交的女(男)朋友的數量如列表a和b,請在一個圖中繪制出該數據的折線圖,以便比較自己和同桌20年間的差異,同時分析每年交女(男)朋友的數量走勢
# _*_ coding : utf-8 _*_
# @Time : 2022/7/22
# @Author : 代浩楠
# @File : 03_matplotlib_分析數據
# @Project : PycharmSpace
from matplotlib import pyplot as plt
import random
import matplotlib
from matplotlib import font_manager
# 假設大家在30歲的時候,根據自己的實際情況,統計出來了你和你同桌各自從11歲到30歲每年交的女(男)朋友的數量如列表a
# 和b,請在一個圖中繪制出該數據的折線圖,以便比較自己和同桌20年間的差異,同時分析每年交女(男)朋友的數量走勢
my_font = font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttc')
y_1 = [1, 0, 1, 1, 2, 4, 3, 2, 3, 4, 4, 5, 6, 5, 4, 3, 3, 1, 1, 1]
y_2 = [1, 0, 3, 1, 2, 2, 3, 3, 2, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1]
x = range(11, 31)
plt.figure(figsize=(30,8),dpi=80)
# color表示線條顏色 linestyle表示線條形式 : 表示虛線,linewidth線條的粗細
plt.plot(x,y_1,label='自己',color='r',linestyle=':')
plt.plot(x,y_2,label='同桌',color='g')
# 設置x格式
_xticks_lables = ["{}歲".format(i) for i in range(11,31)]
plt.xticks(x,_xticks_lables,fontproperties=my_font)
# 繪制網格
plt.grid(alpha=0.4) # alpha表示透明度 網格中也可以指定線條的形狀
# 添加圖例
plt.legend(prop=my_font, loc=0) # 那條先表示什麼,跟上面label一起用,prop=my_font顯示中文,loc代表位置,根據自己和同桌來分離數據
plt.show()
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-KFXNtcxd-1659168233347)(D:\Desktop\CSDN博客\Python數據分析\image-20220723130828060.png)]
例1 假設通過爬蟲你獲取到了北京2016年3,10月份每天白天的最高氣溫(分別位於列表a,b),那麼此時如何尋找出氣溫和隨時間(天)變化的某種規律?
from matplotlib import pyplot as plt
from matplotlib import font_manager
# 假設通過爬蟲你獲取到了北京2016年3,10月份每天白天的最高氣溫(分別位於列表a,b),那麼此時如何尋找出氣溫和隨時間(天)變化的某種規律?
my_font = font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttc')
y_3 = [11, 17, 16, 11, 12, 11, 12, 6, 6, 7, 8, 9, 12, 15, 14, 17, 18, 21, 16, 17, 20, 14, 15, 15, 15, 19, 21, 22, 22,
22, 23]
y_10 = [26, 26, 28, 19, 21, 17, 16, 19, 18, 20, 20, 19, 22, 23, 17, 20, 21, 20, 22, 15, 11, 15, 5, 13, 17, 10, 11, 13,
12, 13, 6]
x_3 = range(1, 32)
x_10 = range(51, 82)
# 設置圖片大小
plt.figure(figsize=(20, 8), dpi=80)
# 使用scatter方法繪制散點圖,和之前繪制折線圖的唯一區別
plt.scatter(x_3, y_3,label='三月份')
plt.scatter(x_10, y_10,label='十月份')
# 調整x軸的刻度
_x = list(x_3)+list(x_10)
_xtick_labels = ["3月{}日".format(i) for i in x_3]
_xtick_labels += ["十月{}日".format(i) for i in x_10]
plt.xticks(_x[::3],_xtick_labels[::3],fontproperties=my_font,rotation=45)
# 添加圖例
plt.legend(loc='upper left',prop=my_font)
# 添加描述信息
plt.xlabel("時間",fontproperties=my_font)
plt.ylabel("溫度",fontproperties=my_font)
plt.title("標題",fontproperties=my_font)
# 展示
plt.show()

例1:假設你獲取到了2017年內地電影票房前20的電影(列表a)和電影票房數據(列表b),那麼如何更加直觀的展示該數據?
a = [“戰狼2”,“速度與激情8”,“功夫瑜伽”,“西游伏妖篇”,“變形金剛5:最後的騎士”,“摔跤吧!爸爸”,“加勒比海盜5:死無對證”,“金剛:骷髅島”,“極限特工:終極回歸”,“生化危機6:終章”,“乘風破浪”,“神偷奶爸3”,“智取威虎山”,“大鬧天竺”,“金剛狼3:殊死一戰”,“蜘蛛俠:英雄歸來”,“悟空傳”,“銀河護衛隊2”,“情聖”,“新木乃伊”,]
b=[56.01,26.94,17.53,16.49,15.45,12.96,11.8,11.61,11.28,11.12,10.49,10.3,8.75,7.55,7.32,6.99,6.88,6.86,6.58,6.23] 單位:億
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttc')
x = ["戰狼2", "速度與激情8", "功夫瑜伽", "西游伏妖篇", "變形金剛5:最後的騎士",
"摔跤吧!爸爸", "加勒比海盜5:死無對證", "金剛:骷髅島", "極限特工:終極回歸",
"生化危機6:終章", "乘風破浪", "神偷奶爸3", "智取威虎山", "大鬧天竺",
"金剛狼3:殊死一戰", "蜘蛛俠:英雄歸來", "悟空傳", "銀河護衛隊2", "情聖", "新木乃伊", ]
y = [56.01, 26.94, 17.53, 16.49, 15.45,
12.96, 11.8, 11.61, 11.28, 11.12, 10.49, 10.3, 8.75, 7.55, 7.32, 6.99, 6.88, 6.86, 6.58, 6.23]
# 設置圖形大小
plt.figure(figsize=(20,10),dpi=80)
# 繪制條形圖
plt.bar(x,y,width=0.13)
# 設置x軸
plt.xticks(range(len(x)),x,fontproperties=my_font,rotation=45)
plt.show()
例2:假設你知道了列表a中電影分別在2017-09-14(b_14), 2017-09-15(b_15), 2017-09-16(b_16)三天的票房,為了展示列表中電影本身的票房以及同其他電影的數據對比情況,應該如何更加直觀的呈現該數據?
a = [“猩球崛起3:終極之戰”,“敦刻爾克”,“蜘蛛俠:英雄歸來”,“戰狼2”]
b_16 = [15746,312,4497,319]
b_15 = [12357,156,2045,168]
b_14 = [2358,399,2358,362]
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttc')
a = ["猩球崛起3:終極之戰","敦刻爾克","蜘蛛俠:英雄歸來","戰狼2"]
b_16 = [15746,312,4497,319]
b_15 = [12357,156,2045,168]
b_14 = [2358,399,2358,362]
plt.figure(figsize=(20,8),dpi=80)
bar_width = 0.2
x_14 = list(range(len(a)))
x_15 = [i+bar_width for i in x_14]
x_16 = [i+bar_width*2 for i in x_14]
plt.bar(range(len(a)),b_14,width=bar_width,label='9月14日')
plt.bar(x_15,b_15,width=bar_width,label='9月15日')
plt.bar(x_16,b_16,width=bar_width,label='9月16日')
# 設置x軸的刻度
plt.xticks(x_15,a,fontproperties=my_font)
plt.legend(prop=my_font)
plt.show()

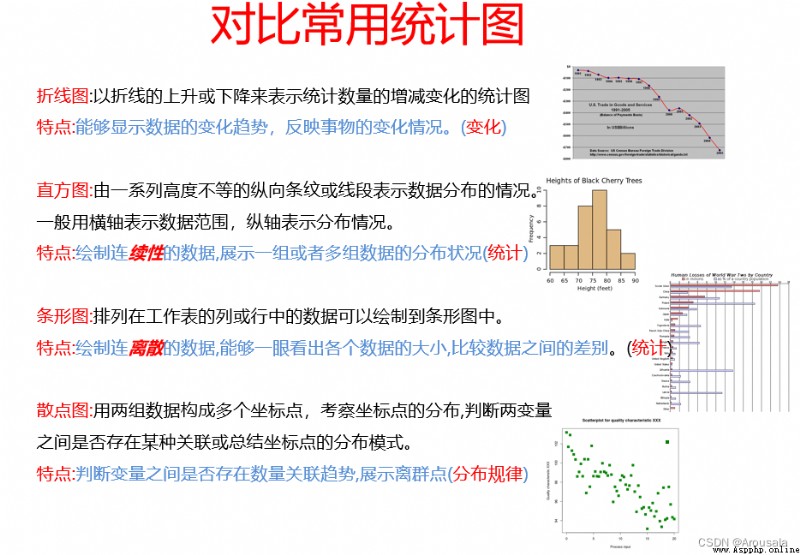
舉例:
假設你獲取了250部電影的時長(列表a中),希望統計出這些電影時長的分布狀態(比如時長為100分鐘到120分鐘電影的數量,出現的頻率)等信息,你應該如何呈現這些數據?
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttc')
a = [131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138,
131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124, 101,
110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138,
117, 111, 78, 132, 124, 113, 150, 110, 117, 86, 95, 144, 105, 126,
130, 126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99,
136, 123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125,
127, 105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120,
114, 105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132,
134, 156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,
123, 107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119,
133, 112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112,
135, 115, 146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100,
154, 136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109,
141, 120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125,
126, 114, 140, 103, 130, 141, 117, 106, 114, 121, 114, 133, 137,
92, 121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139,
113, 134, 106, 144, 110, 137, 137, 111, 104, 117, 100, 111, 101,
110, 105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133,
101, 131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111, 111, 133, 150]
# 計算組數
d = 3 # 組距
num_bins = (max(a) - min(a)) // d
plt.figure(figsize=(20, 8), dpi=80)
# density分布占比
plt.hist(a, num_bins,density=True)
# 設置x軸的刻度
plt.xticks(range(min(a), max(a) + d, d))
# 繪制網格線
plt.grid()
plt.show()
例:在美國2004年人口普查發現有124 million的人在離家相對較遠的地方工作。根據他們從家到上班地點所需要的時間,通過抽樣統計(最後一列)出了下表的數據,這些數據能夠繪制成直方圖麼?
from matplotlib import pyplot as plt
from matplotlib import font_manager
interval = [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 60, 90] # 時間段
width = [5, 5, 5, 5, 5, 5, 5, 5, 5, 15, 30, 60] # 組距
quantity = [836, 2737, 3723, 3926, 3596, 1438, 3273, 642, 824, 613, 215, 47] # 數據
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(quantity)),quantity,width=1)
_x = [i-0.5 for i in range(13)]
plt.xticks(_x,interval+[150])
plt.grid(alpha=0.4)
plt.show()
numpy一個在Python中做科學計算的基礎庫,重在數值計算,也是大部分PYTHON科學計算庫的基礎庫,多用於在大型、多維數組上執行數值運算。

import random
import numpy as np
# 使用numpy生成數組,得到ndarray數據類型
t1 = np.array([1,2,3,])
# [1 2 3]
print(t1)
# <class 'numpy.ndarray'>
print(type(t1))
t2 = np.array(range(10))
# [0 1 2 3 4 5 6 7 8 9]
print(t2)
t3 = np.arange(10)
# [0 1 2 3 4 5 6 7 8 9]
print(t3)
# <class 'numpy.ndarray'>
print(type(t3))
# int32
print(t3.dtype)
t4 = np.array(range(1,4),dtype=float)
# [1. 2. 3.]
print(t4)
# float64
print(t4.dtype)
t5 = np.array([1,1,0,1,0,0],dtype=bool)
# [ True True False True False False]
print(t5)
# <class 'numpy.ndarray'>
print(type(t5))
# 調整數據類型
t6 = t5.astype('int8')
# [1 1 0 1 0 0]
print(t6)
# <class 'numpy.ndarray'>
print(type(t6))
# numpy中的小數
t7 = np.array([random.random() for i in range(10)])
# [0.73593078 0.71967357 0.1779758 0.40511636 0.48492761 0.59916313
# 0.92514657 0.54853781 0.17200714 0.63195203]
print(t7)
# float64
print(t7.dtype)
# round取小數,2是兩位
# [0.14 0.1 0.63 0.75 0.29 0.9 0.7 0.78 0.17 0.06]
t8 = np.round(t7,2)
print(t8)
# 當數組是一維時
import numpy as np
a = np.array([1, 2, 3, 4])
a.shape
a.shape[0] #數組的數量
# 當數組是二維時
c1 = np.array([[1, 2],[3,4], [5,6]])
c1.shape #行列形成元組直接輸出
c1.shape[0] #讀取行數
c1.shape[1] #讀取列數
# 當數組是三維時
a = np.array(range(24)).reshape(2,3,4) #構建一個2×3×4的三維數組
a.shape[0]
a.shape[1]
a.shape[2]
import numpy as np
t1 = np.array([[3,4,5,6,7,8],[4,5,6,7,8,9]])
# (2, 6)
# print(t1.shape)
t2 = np.array([0,1,2,3,4,5,6,7,8,9,10,11])
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# print(t2.reshape((3,4)))
t3 = np.arange(24)
t3 = t3.reshape(2,3,4)
# -1變為一維
t3 = t3.reshape(-1)
print(t3)
import numpy as np
t1 = np.arange(24).reshape(4,6)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
print(t1)
t1 = t1+2
# [[ 2 3 4 5 6 7]
# [ 8 9 10 11 12 13]
# [14 15 16 17 18 19]
# [20 21 22 23 24 25]]
print(t1)
4.numpy讀取和存儲數據
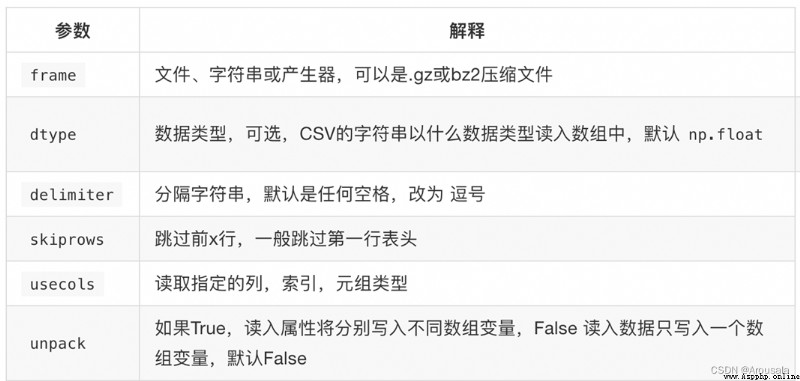

import numpy as np
us_file_path = './youtube_video_data/US_video_data_numbers.csv'
uk_file_path = './youtube_video_data/GB_video_data_numbers.csv'
# delimiter分割數據
# dtype給出數據類型,默認數值大為科學計數法
# unpack如果為True,讀入屬性將寫入不同數組變量,False只寫入一個數組變量(數組轉置)
t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
t2 = np.loadtxt(us_file_path,delimiter=",",dtype=int)
print(t1)
print("=================")
print(t2)
t3 = np.arange(24).reshape(4,6)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
print(t3)
# [[ 0 6 12 18]
# [ 1 7 13 19]
# [ 2 8 14 20]
# [ 3 9 15 21]
# [ 4 10 16 22]
# [ 5 11 17 23]]
# 第一種方法:t3.transpose()轉置數組
# print(t3.transpose())
# 第二種方法:t3.T
# print(t3.T)
# 第三種方法:t3.swapaxes(1,0)
print(t3.swapaxes(1,0))
# 取行
# print(t2[2])
# 取連續的多行
# print(t2[2:])
# 取不連續的多行
# print(t2[[2,8,10]])
# 取列 第一列
# print(t2[:,0])
# 取連續的多列 從第二列開始取
# print(t2[:,2:])
# 取不連續的多列
# print(t2[:,[0,2]])
# 取多行多列 取第三行第四列的值
# print(t2[2,3])
# 取多行和多列,取第三行到第五行,第二列到第四列
# print(t2[2:5,1:4])
# 取多個不鄰的點
# [4394029 576597]
# print(t2[[0,2],[0,1]])
print(t2[[0,2,2],[0,1,3]])



# [[False False False False]
# [False False False True]
# [False False False False]
# print(t2<10)
# t2中小於10的替換為3
# t2[t2<10] = 3
# where(t2<10,0,10) t2中小於10的替換為0,否則替換為10
# np.where(t2 < 10, 0, 10) # numpy的三元運算符
# clip(10,18),小於10的替換為10,大於18的替換為18
# np.clip(10,18)
# 將指定數組替換為nan類型
t2 = t2.astype(float)
t2[3,3] = np.nan


import numpy as np
# False
print(np.nan == np.nan)
t1 = np.arange(24).reshape(4, 6)
print(t1)
# 把第一列替換為0
t1[:, 0] = 0
print(t1)
t1 = t1.astype(float)
t1[3,3] = np.nan
# 查看不為0的數目
print(np.count_nonzero(t1))
# 可以統計出nan的數量
print(np.count_nonzero(t1!=t1))
# 也可以統計nan的數量
print(np.count_nonzero(np.isnan(t1)))
填充nan為列的平均值
import numpy as np
# 遍歷每一列
def fill_ndarray(t1):
for i in range(t1.shape[1]):
# 將列切片
# [0. 4. 8.]
# [False False False]
# 0
# [1. 5. 9.]
# [False False False]
# 0
# [ 2. nan 10.]
# [False True False]
# 1
# [ 3. nan 11.]
# [False True False]
# 1
# 將數組的列切片
temp_col = t1[:, i]
# temp_col!=temp_col:自我判斷,如果為nan就為True
# np.count_nonzero(temp_col!=temp_col) 沒有true就為0,有true就為1
nan_num = np.count_nonzero(temp_col != temp_col)
if nan_num != 0: # 不為0,說明當前這一列中有nan
temp_not_nan_col = temp_col[temp_col == temp_col] # 當前一列不為nan的array
# 選中當前為nan的位置,把值賦值為不為nan的均值
temp_col[np.isnan(temp_col)] = temp_not_nan_col.mean()
return t1
if __name__ == '__main__':
t1 = np.arange(12).reshape(3, 4).astype("float")
t1[1, 2:] = np.nan
print(t1)
t1 = fill_ndarray(t1)
print(t1)
import numpy as np
t1 = np.arange(12).reshape(2,6)
print(t1)
t2 = np.array(range(12,24)).reshape(2,6)
print(t2)
# 豎直拼接
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]
# [12 13 14 15 16 17]
# [18 19 20 21 22 23]]
print(np.vstack((t1,t2)))
# 水平拼接
# [[ 0 1 2 3 4 5 12 13 14 15 16 17]
# [ 6 7 8 9 10 11 18 19 20 21 22 23]]
print(np.hstack((t1,t2)))
# 行交換
# t1[[0,1],:] = t2[[1,0],:]
# [[18 19 20 21 22 23]
# [12 13 14 15 16 17]]
# print(t1)
# 列交換
# [[13 12 2 3 4 5]
# [19 18 8 9 10 11]]
t1[:,[0,1]] = t2[:,[1,0]]
print(t1)


現在希望把之前案例中兩個國家的數據放到一起來研究分析,同時保留國家的信息(每條數據的國家來源),應該怎麼辦
import numpy as np
us_data = "./youtube_video_data/US_video_data_numbers.csv"
uk_data = "./youtube_video_data/GB_video_data_numbers.csv"
# 加載國家數據
us_data = np.loadtxt(us_data,delimiter=',',dtype=int)
uk_data = np.loadtxt(uk_data,delimiter=',',dtype=int)
# 添加國家信息
# 構造全為0的數據
# zeros((結構)),創建一個全為0的數組
# us_data.shape[0]讀取行數 us_data.shape[1] 讀取列數
zeros_data = np.zeros((us_data.shape[0],1))
# 創建一個全為1的數組
ones_data = np.ones((uk_data.shape[0],1))
# 分別添加一列全為0,1的數組
us_data = np.hstack((us_data,zeros_data))
uk_data = np.hstack((uk_data,ones_data))
# 拼接兩組數據
final_data = np.vstack((us_data,uk_data)).astype(int)
print(final_data)
使用numpy中的隨機方法
# 可以設定隨機的相同種子數
np.random.seed(10)
# 0-20間的隨機數,(3,4)的結構
t = np.random.randint(0,20,(3,4))
print(t)

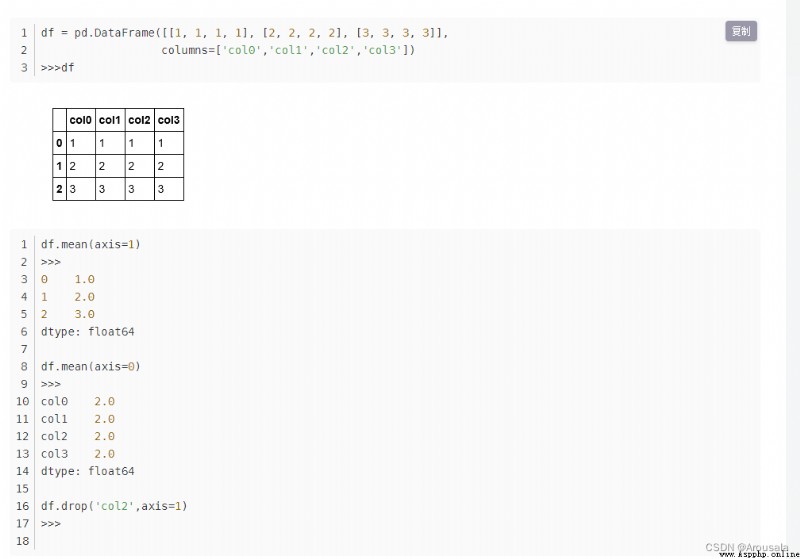
t2 = np.arange(12).reshape(3,4)
print(t2)
print(np.sum(t2))
print(np.sum(t2,axis=0))
# 計算每列的均值
print(t2.mean(axis=0))
# 計算數組的均值
print(np.median(t2))
# 計算極值
print(np.ptp(t2))
# 標准差
print(np.std(t2))
英國和美國各自youtube1000的數據結合之前的matplotlib繪制出各自的評論數量直方圖
import numpy as np
from matplotlib import pyplot as plt
us_file_path = './youtube_video_data/US_video_data_numbers.csv'
uk_file_path = './youtube_video_data/GB_video_data_numbers.csv'
t_us = np.loadtxt(us_file_path,delimiter=',',dtype='int')
t_uk = np.loadtxt(uk_file_path,delimiter=',',dtype='int')
# 取評論的數據 -1為最後一列
t_us_comments = t_us[:,-1]
# 選擇比5000小的數據
t_us_comments = t_us_comments[t_us_comments<=5000]
# 使用matplotlib畫出直方圖
d = 250
bin_nums = (np.max(t_us_comments)-np.min(t_us_comments))//d
# 繪圖
plt.figure(figsize=(20,8),dpi=80)
plt.hist(t_us_comments,bin_nums)
plt.show()
了解英國的youtube中視頻的評論數和喜歡數的關系
from matplotlib import pyplot as plt
import numpy as np
us_file_path = './youtube_video_data/US_video_data_numbers.csv'
uk_file_path = './youtube_video_data/GB_video_data_numbers.csv'
t_us = np.loadtxt(us_file_path, delimiter=',', dtype='int')
t_uk = np.loadtxt(uk_file_path, delimiter=',', dtype='int')
t_uk = t_uk[t_uk[:, 1] <= 500000]
t_uk_comment = t_uk[:, -1]
t_uk_like = t_uk[:, 1]
plt.figure(figsize=(20, 8), dpi=80)
plt.scatter(t_uk_like, t_uk_comment)
plt.show()

pandas是python中的第三方庫,主要用來處理數據,類似於excel。
1.Series 一維,帶標簽數組(索引)
2.DataFrame 二維
import pandas as pd
t1 = pd.Series([12,3,45,6,2])
# 0 12
# 1 3
# 2 45
# 3 6
# 4 2
# dtype: int64
# print(t1)
t2 = pd.Series([1,22,33,45,6],index=list('abcde'))
# a 1
# b 22
# c 33
# d 45
# e 6
# dtype: int64
# print(t2)
t3 = {
"name":"小紅",
"age":30,
"tel":10086
}
t3 = pd.Series(t3)
# print(t3["name"])
# print(t3[0])
# print(t3[[1,2]])
print(t3[["age","tel"]])
# Index(['name', 'age', 'tel'], dtype='object')
print(t3.index)
# ['name', 'age', 'tel']
print(list(t3.index))
# ['name', 'age']
print(list(t3.index)[:2])
# ['小紅' 30 10086]
print(t3.values)
# <class 'numpy.ndarray'>
print(type(t3.values))
import pandas as pd
# pandas讀取csv中的文件
df = pd.read_csv("./dogNames2.csv")
# 讀取sql
# pd.read_sql()
print(df)

import pandas as pd
import numpy as np
# index列索引,columns行索引
t1 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))
# W X Y Z
# a 0 1 2 3
# b 4 5 6 7
# c 8 9 10 11
print(t1)
d1 = {
"name":["xiaoming","xiaogang"],"age":[20,22],"tel":[10086,10010]}
d1 = pd.DataFrame(d1)
# name age tel
# 0 xiaoming 20 10086
# 1 xiaogang 22 10010
print(d1)
d2 = [{
"name":"小剛","age":22,"tel":10086},{
"name":"小紅","tel":10010},{
"name":"小李","age":25}]
d2 = pd.DataFrame(d2)
# name age tel
# 0 小剛 22.0 10086.0
# 1 小紅 NaN 10010.0
# 2 小李 25.0 NaN
print(d2)

t2 = {
"name":["xiaoming","xiaogang"],"age":[20,22],"tel":[10086,10010]}
t2 = pd.DataFrame(t2)
print(t2)
# 數據的列
# Index(['name', 'age', 'tel'], dtype='object')
print(t2.columns)
# 數據值
# [['xiaoming' 20 10086]
# ['xiaogang' 22 10010]]
print(t2.values)
# 數據的索引,開始、結尾、步長
# RangeIndex(start=0, stop=2, step=1)
print(t2.index)
# dtypes列的類型
# name object
# age int64
# tel int64
# dtype: object
print(t2.dtypes)
# 2 維度
print(t2.ndim)
# 頭幾行數據
print(t2.head())
# 尾幾行數據
print(t2.tail())
# 相關信息概覽:行數、列數、列索引
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 2 entries, 0 to 1
# Data columns (total 3 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 name 2 non-null object
# 1 age 2 non-null int64
# 2 tel 2 non-null int64
# dtypes: int64(2), object(1)
# memory usage: 176.0+ bytes
# None
print(t2.info())
# 描述信息
# age tel
# count 2.000000 2.000000
# mean 21.000000 10048.000000
# std 1.414214 53.740115
# min 20.000000 10010.000000
# 25% 20.500000 10029.000000
# 50% 21.000000 10048.000000
# 75% 21.500000 10067.000000
# max 22.000000 10086.000000
print(t2.describe())

import pandas as pd
import numpy as np
df = pd.read_csv("dogNames2.csv")
# print(df.head())
# print(df.info())
# dataFrame中排序的方法
# by:通過什麼排序
# ascending:True為降序,False為升序
df = df.sort_values(by="Count_AnimalName",ascending=False)
# print(df.tail())
# # 前五行數據
# print(df.head(5))
# pandas取行或者取列的注意點
# 1.寫括號寫數組,表示取行,對行進行操作
# 2.寫字符串,表示的取列索引,對列進行操作
# 取前二十行
print(df[:20])
# 求出具體的Row_Labels列
print(df["Row_Labels"])
print("------------")
# 同時選擇行和列
print(df[:5]["Row_Labels"])

# loc,iloc
# loc:通過標簽索引行數據
t2 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))
# W X Y Z
# a 0 1 2 3
# b 4 5 6 7
# c 8 9 10 11
print(t2)
# 3
print(t2.loc["a","Z"])
# <class 'numpy.int32'>
print(type(t2.loc["a","Z"]))
# 去整行
print(t2.loc["a"])
# 取列
print(t2.loc[:,'Y'])
# 取多行多列
# a 0
# c 8
print(t2.loc[["a","c"],"W"])
# W Y
# a 0 2
# b 4 6
# c 8 10
print(t2.loc["a":"c",["W","Y"]])
print("=====================")
# iloc:通過位置獲取行數據
# 取第一行
# W 4
# X 5
# Y 6
# Z 7
print(t2.iloc[1,:])
# 取第二列和第一列
# Y X
# a 2 1
# b 6 5
# c 10 9
print(t2.iloc[:,[2,1]])
# 取多行多列
print(t2.iloc[[0,2],[1,2]])
t2.iloc[1:,:2] = np.nan
# W X Y Z
# a 0.0 1.0 2 3
# b NaN NaN 6 7
# c NaN NaN 10 11
print(t2)
import pandas as pd
df = pd.read_csv("dogNames2.csv")
# 條件查詢數量大於800
num = df[df["Count_AnimalName"]>=800]
print(num)
在這裡插入圖片描述
# 分割字符串
print(df["info"].str.split("/"))
# 將分割的字符串變為列表
print(df["info"].str.split("/").tolist())
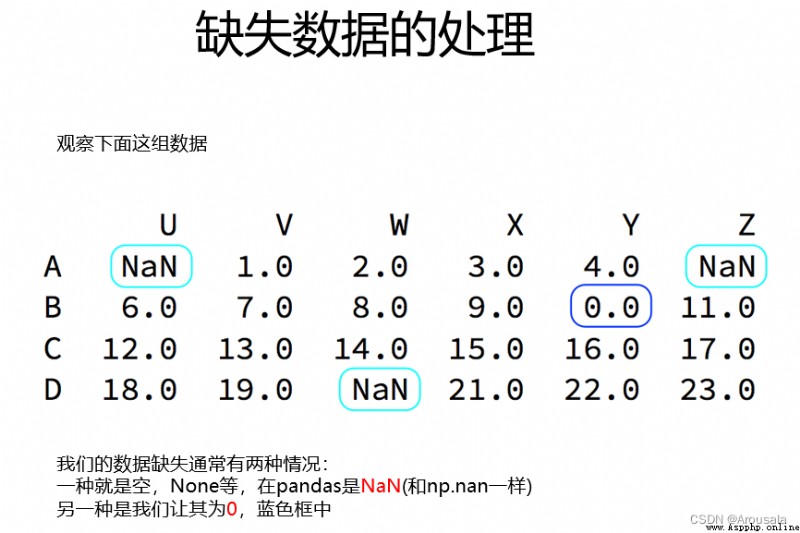

import pandas as pd
import numpy as np
t1 = pd.DataFrame(np.arange(12).reshape(3, 4), index=list('abc'), columns=list('WXYZ'))
t1.iloc[1:3, :2] = np.nan
# W X Y Z
# a 0.0 1.0 2 3
# b NaN NaN 6 7
# c NaN NaN 10 11
print(t1)
# 判斷是否為NaN,若是NaN為True,否則為False
# W X Y Z
# a False False False False
# b True True False False
# c True True False False
print(pd.isnull(t1))
# 判斷是否不為NaN,不為NaN就為True
# W X Y Z
# a True True True True
# b False False True True
# c False False True True
print(pd.notnull(t1))
# W這一列不為NaN的數據
# a True
# b False
# c False
print(pd.notnull(t1["W"]))
# 選擇一列中為True的行
# W X Y Z
# a 0.0 1.0 2 3
print(t1[pd.notnull(t1["W"])])
# 刪除NaN所在的行列,axis=0為行,axis=1為列
# W X Y Z
# a 0.0 1.0 2 3
print(t1.dropna(axis=0))
# 刪除全部為NaN的行,不全部為NaN的行不刪 how=all為全為NaN刪,how=any為不全為NaN的刪
print(t1.dropna(axis=0, how="all"))
# 將NaN的數填充
print(t1.fillna(100))
print(t1.fillna(t1.mean()))
# 處理為0的數據
t1[t1==0] = np.nan
import pandas as pd
from matplotlib import pyplot as plt
file_path = 'IMDB-Movie-Data.csv'
df = pd.read_csv(file_path)
# rating,runtime分布情況
# 選擇圖形:直方圖
runtime_data = df["Runtime (Minutes)"].values
Rating = df["Rating"].values
max_runtime = runtime_data.max()
min_runtime = runtime_data.min()
# 計算組數
num_bin = (max_runtime-min_runtime)//5
plt.figure(figsize=(20,8),dpi=80)
plt.hist(runtime_data,num_bin)
plt.xticks(range(min_runtime,max_runtime+5,5))
plt.show()

import pandas as pd
file_path = 'IMDB-Movie-Data.csv'
df = pd.read_csv(file_path)
# 獲取電影的平均評分
print(df["Rating"].mean())
# 獲取導演的人數
# set() 函數創建一個無序不重復元素集,可進行關系測試,刪除重復數據,還可以計算交集、差集、並集等。
# .unique() 獲取唯一的數據
print(len(set(df["Director"].tolist())))
print(len(df["Director"].unique()))
# 獲取演員人數
actors_list = []
temp_actors_list = df["Actors"].str.split(",").tolist()
for items in temp_actors_list:
for i in items:
actors_list.append(i)
actors_num = len(set(actors_list))
print(actors_num)
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
file_path = 'IMDB-Movie-Data.csv'
df = pd.read_csv(file_path)
# 統計分類的列表(列表嵌套列表的結構)
# [['Action', 'Adventure', 'Sci-Fi'], ['Adventure', 'Mystery', 'Sci-Fi'],
temp_list = df["Genre"].str.split(",").tolist()
# 嵌套展開雙循環 set 表示不重復
genre_list = list(set([i for j in temp_list for i in j]))
# 構造全為0的數組
# Horror War Sci-Fi Action ... Family Western Thriller Crime
# 0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 1 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
# 999 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
zero_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
# 給每個電影出現分類的位置賦值1 df.shape[0]選中行的數量
# loc(行,列)
for i in range(df.shape[0]):
# zeros_df.loc[0,["Sci-fi","Mucical"]] = 1
zero_df.loc[i,temp_list[i]] = 1
print(zero_df.head(5))
# 統計每個分類的電影的數量和 axis=0為行標題
genre_count = zero_df.sum(axis=0)
# print(genre_count)
# 排序
genre_count = genre_count.sort_values()
_x = genre_count.index
_y = genre_count.values
# 畫圖
plt.Figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.show()


import pandas as pd
import numpy as np
t1 = pd.DataFrame(np.ones((2,4)),index=["A","B"],columns=list("abcd"))
t2 = pd.DataFrame(np.zeros((3,3)),index=["A","B","C"],columns=list("xyz"))
# a b c d
# A 1.0 1.0 1.0 1.0
# B 1.0 1.0 1.0 1.0
print(t1)
# x y z
# A 0.0 0.0 0.0
# B 0.0 0.0 0.0
# C 0.0 0.0 0.0
print(t2)
# a b c d x y z
# A 1.0 1.0 1.0 1.0 0.0 0.0 0.0
# B 1.0 1.0 1.0 1.0 0.0 0.0 0.0
print(t1.join(t2))
# x y z a b c d
# A 0.0 0.0 0.0 1.0 1.0 1.0 1.0
# B 0.0 0.0 0.0 1.0 1.0 1.0 1.0
# C 0.0 0.0 0.0 NaN NaN NaN NaN
print(t2.join(t1))
t3 = pd.DataFrame(np.zeros((3,3)),columns=list("fax"))
# f a x
# 0 0.0 0.0 0.0
# 1 0.0 0.0 0.0
# 2 0.0 0.0 0.0
print(t3)
# 按照a的值比較合並
# Columns: [a, b, c, d, f, x]
# Index: []
print(t1.merge(t3,on='a'))
t3.loc[1,"a"] = 1
# a b c d f x
# 0 1.0 1.0 1.0 1.0 0.0 0.0
# 1 1.0 1.0 1.0 1.0 0.0 0.0
print(t1.merge(t3,on='a'))
# 外連接
# a b c d f x
# 0 1.0 1.0 1.0 1.0 0.0 0.0
# 1 1.0 1.0 1.0 1.0 0.0 0.0
# 2 0.0 NaN NaN NaN 0.0 0.0
# 3 0.0 NaN NaN NaN 0.0 0.0
print(t1.merge(t3,on='a',how='outer'))

import pandas as pd
import numpy as np
file_path = 'directory.csv'
df = pd.read_csv(file_path)
# print(df.head(1))
# 通過Country進行分組
grouped = df.groupby(by="Country")
# print(grouped)
# for i in grouped:
# print(i)
# 調用聚合的方法
country_count = grouped["Brand"].count()
print(country_count["CN"])
# 統計中國每個省店鋪的數量
china_data = df[df["Country"]=='CN']
# 根據每個省進行分組,查看Brand的數量
grouped = china_data.groupby(by="State/Province").count()["Brand"]
# 數據按照多個條件進行分組
grouped = df["Brand"].groupby(by=[df["Country"],df["State/Province"]])
# print(grouped.count())
# df["Brand"] 是一個數組,但是df[["Brand"]]是一個series數據,會有index和column
grouped1 = df[["Brand"]].groupby(by=[df["Country"],df["State/Province"]]).count()
print(grouped1)

import pandas as pd
import numpy as np
file_path = 'directory.csv'
df = pd.read_csv(file_path)
grouped1 = df[["Brand"]].groupby(by=[df["Country"],df["State/Province"]]).count()
# 索引的方法和屬性
# print(grouped1.index)
t1 = pd.DataFrame(np.ones((2,4)),index=list("AB"),columns=list("abcd"))
print(t1)
# Index(['A', 'B'], dtype='object')
print(t1.index)
t1.index = ["a","b"]
# Index(['a', 'b'], dtype='object')
print(t1.index)
# a b c d
# a 1.0 1.0 1.0 1.0
# f NaN NaN NaN NaN
print(t1.reindex(["a","f"]))
# 指定某一列作為索引
# Float64Index([1.0, 1.0], dtype='float64', name='a') drop = False,.unique是不重復
# Float64Index([1.0], dtype='float64', name='a')
print(t1.set_index("a",drop=False).index.unique())
import pandas as pd
import numpy as np
a = pd.DataFrame({
'a': range(7),'b': range(7, 0, -1),'c': ['one','one','one','two','two','two', 'two'],'d': list("hjklmno")})
b = a.set_index(["c","d"])
# a b c d
# 0 0 7 one h
# 1 1 6 one j
# 2 2 5 one k
# 3 3 4 two l
# 4 4 3 two m
# 5 5 2 two n
# 6 6 1 two o
# print(a)
# a b
# c d
# one h 0 7
# j 1 6
# k 2 5
# two l 3 4
# m 4 3
# n 5 2
# o 6 1
# print(b)
c = b["a"]
# c d
# one h 0
# j 1
# k 2
# two l 3
# m 4
# n 5
# o 6
# 1
# print(c["one"]["j"])
d = a.set_index(["d","c"])["a"]
# d c
# h one 0
# j one 1
# k one 2
# l two 3
# m two 4
# n two 5
# o two 6
# print(d)
# MultiIndex([('h', 'one'),
# ('j', 'one'),
# ('k', 'one'),
# ('l', 'two'),
# ('m', 'two'),
# ('n', 'two'),
# ('o', 'two')],
# names=['d', 'c'])
# print(d.index)
# d
# h 0
# j 1
# k 2
# Name: a, dtype: int64
# print(d.swaplevel()["one"])
# a 0
# b 7
# Name: h, dtype: int64
print(b.loc["one"].loc["h"])
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = 'starbucks_store_worldwide.csv'
df = pd.read_csv(file_path)
# 使用matplotlib呈現出店鋪總數排名前10的國家
# 准備數據
data1 = df.groupby(by="Country").count()["Brand"].sort_values(ascending=False)[:10]
# print(data1)
_x = data1.index
_y = data1.values
plt.figure(figsize=(20,8),dpi=80)
plt.bar(_x,_y)
plt.show()
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='C:/Windows/Fonts/msyh.ttc')
file_path = 'starbucks_store_worldwide.csv'
df = pd.read_csv(file_path)
df = df[df["Country"]=="CN"]
# 查詢城市店鋪數量
data1 = df.groupby(by="City").count()["Brand"].sort_values(ascending=False)[:25]
# 使用matplotlib呈現出每個中國每個城市的店鋪數量
plt.figure(figsize=(20,8),dpi=80)
_x = data1.index
_y = data1.values
plt.bar(_x,_y,width=0.3,color="orange")
plt.xticks(range(len(_x)),_x,fontproperties=my_font)
plt.show()
現在我們有全球排名靠前的10000本書的數據,那麼請統計一下下面幾個問題:
1.不同年份書的數量
2.不同年份書的平均評分情況
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# 現在我們有全球排名靠前的10000本書的數據,那麼請統計一下下面幾個問題:
file_path = 'books.csv'
df = pd.read_csv(file_path)
# 查找original_publication_year不為nan的數據
# data1 = df[pd.notnull(df["original_publication_year"])]
# # 1.不同年份書的數量
# grouped = data1.groupby(by="original_publication_year").count()["title"]
# 2.不同年份書的平均評分情況
# 去除original_publication_year列中nan的行
data1 = df[pd.notnull(df["original_publication_year"])]
# 計算機平均評分
grouped = data1["average_rating"].groupby(by=data1["original_publication_year"]).mean()
print(grouped)
_x = grouped.index
_y = grouped.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(_x,_y)
plt.show()
現在我們有2015到2017年25萬條911的緊急電話的數據,請統計出出這些數據中不同類型的緊急情況的次數,如果我們還想統計出不同月份不同類型緊急電話的次數的變化情況,應該怎麼做呢?
第一種方法:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from numpy import shape
df = pd.read_csv("911.csv")
# 獲取分類
temp_list = df["title"].str.split(": ").tolist()
cate_list = list(set([i[0] for i in temp_list]))
# ['Traffic', 'Fire', 'EMS']
# 構造全為0的數組
zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(cate_list))),columns=cate_list)
# 賦值
for cate in cate_list:
zeros_df[cate][df["title"].str.contains(cate)] = 1
sum_ret = zeros_df.sum(axis=0)
# print(sum_ret)
第二種方法:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from numpy import shape
df = pd.read_csv("911.csv")
# 獲取分類
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
cate_df = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)),columns=["cate"])
df["cate"] = cate_df
print(df.groupby(by="cate").count()["title"])
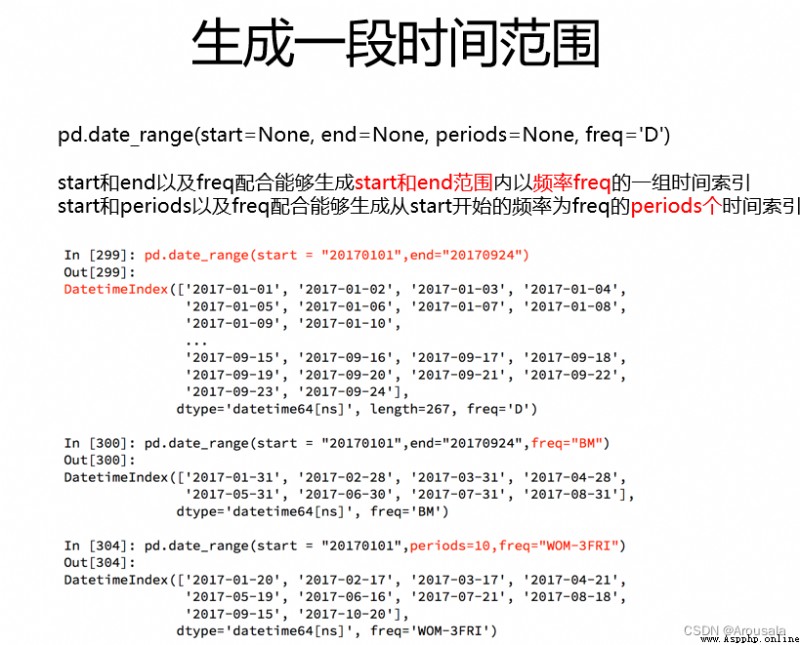


import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from numpy import shape
# freq="D" day表示天
# DatetimeIndex(['2017-12-30', '2018-01-09', '2018-01-19', '2018-01-29'], dtype='datetime64[ns]', freq='10D')
day = pd.date_range(start="20171230",end="20180131",freq="10D")
print(day)
1.統計出911數據中不同月份電話次數的變化情況
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# 統計出911數據中不同月份電話次數的變化情況
# 統計出911數據中不同月份不同類型的電話的次數的變化情況
df = pd.read_csv("911.csv")
df["timeStamp"]=pd.to_datetime(df["timeStamp"])
# inplace=False(默認)表示原數組不變,對數據進行修改之後結果給新的數組。
# inplace=True表示直接在原數組上對數據進行修改。
df.set_index("timeStamp",inplace=True)
# 統計出911數據中不同月份電話次數的變化情況
count_by_month = df.resample("M").count()["title"]
_x = count_by_month.index
_y = count_by_month.values
_x = [i.strftime("%Y%m%d") for i in _x]
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.show()
2.統計出911數據中不同月份不同類型的電話的次數的變化情況
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# 統計出911數據中不同月份不同類型的電話的次數的變化情況
df = pd.read_csv("911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
plt.figure(figsize=(20, 8), dpi=80)
# 添加列,表示分類
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0], 1)))
df.set_index("timeStamp",inplace=True)
# 分組
for group_name,group_data in df.groupby(by="cate"):
# 對不同的分類都進行繪圖
count_by_month = group_data.resample("M").count()["title"]
_x = count_by_month.index
_y = count_by_month.values
_x = [i.strftime("%Y%m%d") for i in _x]
plt.plot(range(len(_x)), _y, label=group_name)
plt.xticks(range(len(_x)), _y, rotation=45)
plt.legend(loc='best')
plt.show()

3.現在我們有北上廣、深圳、和沈陽5個城市空氣質量數據,請繪制出5個城市的PM2.5隨時間的變化情況
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# 現在我們有北上廣、深圳、和沈陽5個城市空氣質量數據,請繪制出5個城市的PM2.5隨時間的變化情況
file_path = "PM2.5/BeijingPM20100101_20151231.csv"
df = pd.read_csv(file_path)
# 把分開的時間字符串通過PeriodIndex轉換為pandas時間類型
period = pd.PeriodIndex(year=df["year"], month=df["month"], day=df["day"], hour=df["hour"], freq="H")
df["datetime"] = period
# 把datatime設置為索引
df.set_index("datetime",inplace=True)
# 進行降采樣
df = df.resample("7D").mean()
# 處理缺失數據,刪除缺失數據
data = df["PM_US Post"].dropna()
data_china = df["PM_Dongsi"].dropna()
# 畫圖
_x = data.index
_x = [i.strftime("%Y%m%d") for i in _x]
_x_china = [i.strftime("%Y%m%d") for i in data_china.index]
_y = data.values
_y_china = data_china.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y,label="US_POST")
plt.plot(range(len(_x_china)),_y_china,label="CN_POST")
plt.xticks(range(0,len(_x),20),list(_x)[::20],rotation=45)
plt.legend(loc="best")
plt.show()