RabbitMq 是實現了高級消息隊列協議(AMQP)的開源消息代理中間件。消息隊列是一種應用程序對應用程序的通行方式,應用程序通過寫消息,將消息傳遞於隊列,由另一應用程序讀取 完成通信。而作為中間件的 RabbitMq 無疑是目前最流行的消息隊列之一。目前使用較多的消息隊列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ。
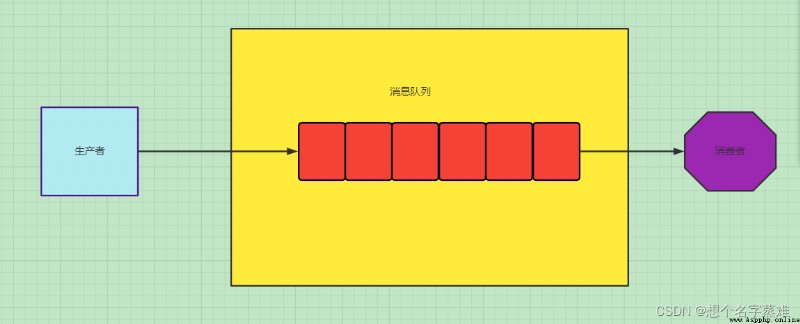
RabbitMQ總體架構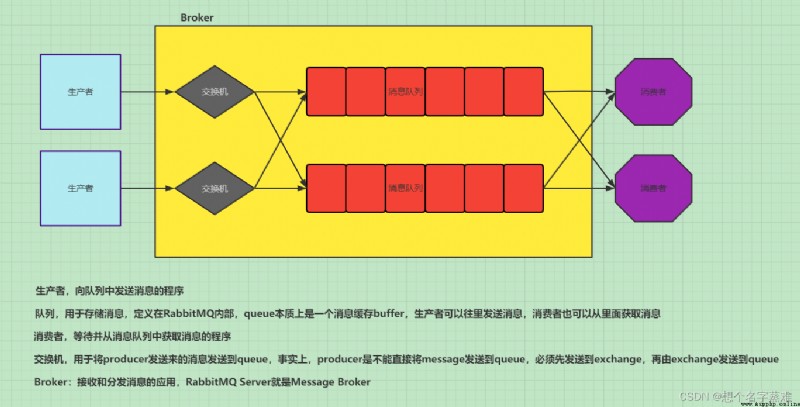
PS:生產者和消費者可能在不同的程序或主機中,當然也有可能一個程序有可能既是生產者,也是消費者。
RabbitMq 應用場景廣泛:
1.系統的高可用:日常生活當中各種商城秒殺,高流量,高並發的場景。當服務器接收到如此大量請求處理業務時,有宕機的風險。某些業務可能極其復雜,但這部分不是高時效性,不需要立即反饋給用戶,我們可以將這部分處理請求拋給隊列,讓程序後置去處理,減輕服務器在高並發場景下的壓力。
2.分布式系統,集成系統,子系統之間的對接,以及架構設計中常常需要考慮消息隊列的應用。
apt-get update
apt-get install erlang
apt-get install rabbitmq-server
#啟動rabbitmq: service rabbitmq-server start
#停止rabbitmq: service rabbitmq-server stop
#重啟rabbitmq: service rabbitmq-server restart
#啟動rabbitmq插件:rabbitmq-plugins enable rabbitmq_management
啟用rabbitmq_management插件後就可以登錄後台管理頁面了,浏覽器輸入ip:15672
自帶的密碼和用戶名都是guest,但是只能本機登錄
所以下面我們添加新用戶,和自定義權限
#添加新用戶
rabbitmqctl add_user 用戶名 密碼
#給指定用戶添加管理員權限
rabbitmqctl set_user_tags 用戶名 administrator
給用戶添加權限
rabbitmqctl set_permissions -p / 用戶名 ".*" ".*" ".*"
在web頁面輸入用戶名,和密碼
python中使用pika操作RabbitMQ
pip install pika
#皮卡皮卡,哈哈
上代碼
# coding=utf-8
### 生產者
import pika
import time
user_info = pika.PlainCredentials('root', 'root')#用戶名和密碼
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))#連接服務器上的RabbitMQ服務
# 創建一個channel
channel = connection.channel()
# 如果指定的queue不存在,則會創建一個queue,如果已經存在 則不會做其他動作,官方推薦,每次使用時都可以加上這句
channel.queue_declare(queue='hello')
for i in range(0, 100):
channel.basic_publish(exchange='',#當前是一個簡單模式,所以這裡設置為空字符串就可以了
routing_key='hello',# 指定消息要發送到哪個queue
body='{}'.format(i)# 指定要發送的消息
)
time.sleep(1)
# 關閉連接
# connection.close()
PS:RabbitMQ中所有的消息都要先通過交換機,空字符串表示使用默認的交換機
# coding=utf-8
### 消費者
import pika
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
# 如果指定的queue不存在,則會創建一個queue,如果已經存在 則不會做其他動作,生產者和消費者都做這一步的好處是
# 這樣生產者和消費者就沒有必要的先後啟動順序了
channel.queue_declare(queue='hello')
# 回調函數
def callback(ch, method, properties, body):
print('消費者收到:{}'.format(body))
# channel: 包含channel的一切屬性和方法
# method: 包含 consumer_tag, delivery_tag, exchange, redelivered, routing_key
# properties: basic_publish 通過 properties 傳入的參數
# body: basic_publish發送的消息
channel.basic_consume(queue='hello', # 接收指定queue的消息
auto_ack=True, # 指定為True,表示消息接收到後自動給消息發送方回復確認,已收到消息
on_message_callback=callback # 設置收到消息的回調函數
)
print('Waiting for messages. To exit press CTRL+C')
# 一直處於等待接收消息的狀態,如果沒收到消息就一直處於阻塞狀態,收到消息就調用上面的回調函數
channel.start_consuming()
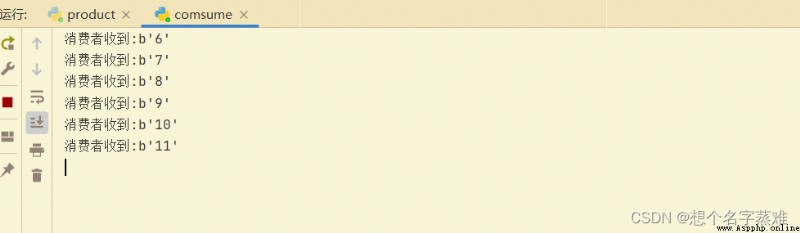
對於上面的這種模式,有一下兩個不好的地方:
一個是在我們的消費者還沒開始消費完隊列裡的消息,如果這時rabbitmq服務掛了,那麼消息隊列裡的消息將會全部丟失,解決方法是在聲明隊列時,聲明隊列為可持久化存儲隊列,並且在生產者在將消息插入到消息隊列時,設置消息持久化存儲,具體如下
# coding=utf-8
### 生產者
import pika
import time
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
# 創建一個channel
channel = connection.channel()
# 如果指定的queue不存在,則會創建一個queue,如果已經存在 則不會做其他動作,官方推薦,每次使用時都可以加上這句
channel.queue_declare(queue='durable_queue',durable=True)
#PS:這裡不同種隊列不允許名字相同
for i in range(0, 100):
channel.basic_publish(exchange='',
routing_key='durable_queue',
body='{}'.format(i),
properties=pika.BasicProperties(delivery_mode=2)
)
# 關閉連接
# connection.close()
消費者與上面的消費者沒有什麼不同,具體的就是消費聲明的隊列,也要是可持久化的隊列,還有就是,即使在生產者插入消息時,設置當前消息持久化存儲(properties=pika.BasicProperties(delivery_mode=2)),並不能百分百保證消息真的被持久化,因為RabbitMQ掛掉的時候它可能還保存在緩存中,沒來得及同步到磁盤中
在生產者插入消息後,立刻停止rabbitmq,並重新啟動,其實我們在web管理頁面也可看到未被消費的信息,當然在啟動消費者後也成功接收到了消息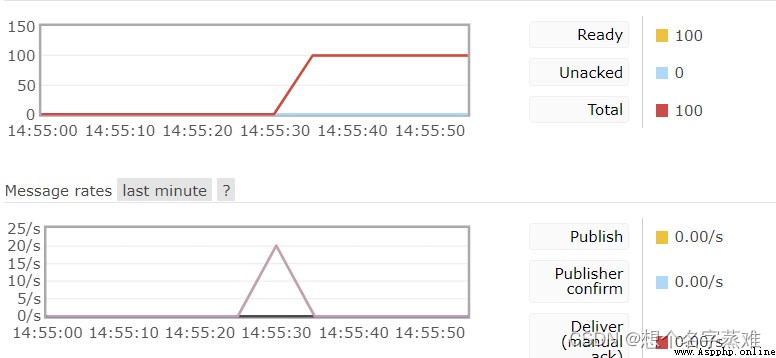
上面說的第二點不好就是,如果在消費者獲取到隊列裡的消息後,在回調函數的處理過程中,消費者突然出錯或程序崩潰等異常,那麼就會造成這條消息並未被實際正常的處理掉。為了解決這個問題,我們只需在消費者basic_consume(auto_ack=False),並在回調函數中設置手動應答即可ch.basic_ack(delivery_tag=method.delivery_tag),具體如下
# coding=utf-8
### 消費者
import pika
import time
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
# 如果指定的queue不存在,則會創建一個queue,如果已經存在 則不會做其他動作,生產者和消費者都做這一步的好處是
# 這樣生產者和消費者就沒有必要的先後啟動順序了
channel.queue_declare(queue='queue')
# 回調函數
def callback(ch, method, properties, body):
time.sleep(5)
ch.basic_ack(delivery_tag=method.delivery_tag)
print('消費者收到:{}'.format(body.decode('utf-8')))
# channel: 包含channel的一切屬性和方法
# method: 包含 consumer_tag, delivery_tag, exchange, redelivered, routing_key
# properties: basic_publish 通過 properties 傳入的參數
# body: basic_publish發送的消息
channel.basic_consume(queue='queue', # 接收指定queue的消息
auto_ack=False, # 指定為False,表示取消自動應答,交由回調函數手動應答
on_message_callback=callback # 設置收到消息的回調函數
)
# 應答的本質是告訴消息隊列可以將這條消息銷毀了
print('Waiting for messages. To exit press CTRL+C')
# 一直處於等待接收消息的狀態,如果沒收到消息就一直處於阻塞狀態,收到消息就調用上面的回調函數
channel.start_consuming()
這裡只需要配置消費者,生產者並不要修改
還有就是在上的使用方式在,都是一個生產者和一個消費者,還有一種情況就是,一個生產者和多個消費者,即多個消費者同時監聽一個消息隊列,這時候隊列裡的消息就是輪詢分發(即如果消息隊列裡有100條信息,如果有2個消費者,那麼每個就會收到50條信息),但是在某些情況下,不同的消費者處理任務的能力是不同的,這時還按照輪詢的方式分發消息並不是很合理,那麼只需要再配合手動應答的方式,設置消費者接收的消息沒有處理完,隊列就不要給我放送新的消息即可,具體配置方式如下:
# coding=utf-8
### 消費者
import pika
import time
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
# 如果指定的queue不存在,則會創建一個queue,如果已經存在 則不會做其他動作,生產者和消費者都做這一步的好處是
# 這樣生產者和消費者就沒有必要的先後啟動順序了
channel.queue_declare(queue='queue')
# 回調函數
def callback(ch, method, properties, body):
time.sleep(0)#通過設置休眠時間來模擬不同消費者的處理時間
ch.basic_ack(delivery_tag=method.delivery_tag)
print('消費者收到:{}'.format(body.decode('utf-8')))
# prefetch_count表示接收的消息數量,當我接收的消息沒有處理完(用basic_ack標記消息已處理完畢)之前不會再接收新的消息了
channel.basic_qos(prefetch_count=1) # 還有就是這個設置必須在basic_consume之上,否則不生效
channel.basic_consume(queue='queue', # 接收指定queue的消息
auto_ack=False, # 指定為False,表示取消自動應答,交由回調函數手動應答
on_message_callback=callback # 設置收到消息的回調函數
)
# 應答的本質是告訴消息隊列可以將這條消息銷毀了
print('Waiting for messages. To exit press CTRL+C')
# 一直處於等待接收消息的狀態,如果沒收到消息就一直處於阻塞狀態,收到消息就調用上面的回調函數
channel.start_consuming()
PS:這種情況必須關閉自動應答ack,改成手動應答。使用basicQos(perfetch=1)限制每次只發送不超過1條消息到同一個消費者,消費者必須手動反饋告知隊列,才會發送下一個
發布訂閱會將消息發送給所有的訂閱者,而消息隊列中的數據被消費一次便消失。所以,RabbitMQ實現發布和訂閱時,會為每一個訂閱者創建一個隊列,而發布者發布消息時,會將消息放置在所有相關隊列中
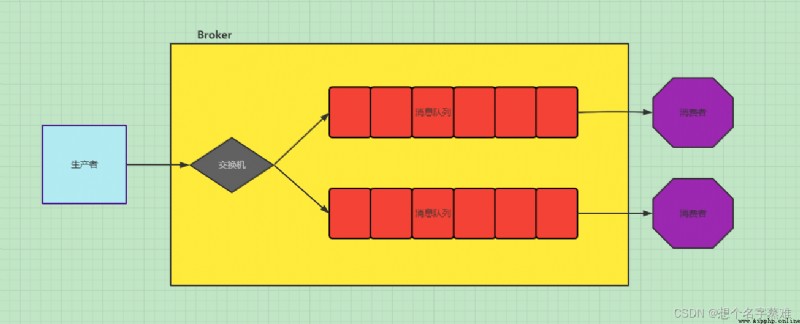
這個模式中會引入交換機的概念,其實在RabbitMQ中,所有的生產者都不會直接把消息發送到隊列中,甚至生產者都不知道消息在發出後有沒有發送到queue中,事實上,生產者只能將消息發送給交換機,由交換機來決定發送到哪個隊列中。
交換機的一端用來從生產者中接收消息,另一端用來發送消息到隊列,交換機的類型規定了怎麼處理接收到的消息,發布訂閱模式使用到的交換機類型為 fanout ,這種交換機類型非常簡單,就是將接收到的消息廣播給已知的(即綁定到此交換機的)所有消費者。
當然,如果不想使用特定的交換機,可以使用 exchange=’’ 表示使用默認的交換機,默認的交換機會將消息發送到 routing_key 指定的queue,可以參考簡單模式。
上代碼:
#生產者
import pika
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
# 創建一個指定名稱的交換機,並指定類型為fanout,用於將接收到的消息廣播到所有queue中
channel.exchange_declare(exchange='交換機', exchange_type='fanout')
# 將消息發送給指定的交換機,在fanout類型中,routing_key=''表示不用發送到指定queue中,
# 而是將發送到綁定到此交換機的所有queue
channel.basic_publish(exchange='交換機', routing_key='', body='這是一條測試消息')
#消費者
import pika
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
channel.exchange_declare(exchange='交換機', exchange_type='fanout')
# 使用RabbitMQ給自己生成一個專有的queue
result = channel.queue_declare(queue='333')
# result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
# 這裡如果設置exclusive=True參數,那麼該隊列就是一個只有隊列,在消費者結束後,該專有隊列也會自動清除,如果queue=''沒有設置名字的話,那麼就會自動生成一個
# 不會重復的隊列名
# 將queue綁定到指定交換機
channel.queue_bind(exchange='交換機', queue=queue_name)
print(' [*] Waiting for message.')
def callback(ch, method, properties, body):
print("消費者收到:{}".format(body.decode('utf-8')))
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
該模式與簡單模式的還有一個區別就是,這裡的消息隊列都是由消費者聲明的,所以如果是生產者先啟動,並將消息發給交換機的畫,這裡的消息就會丟失,所以我們也可以在消費者端聲明隊列並綁定交換機(不能是專有隊列),所以仔細想想,其實這所謂的發布訂閱模式並沒有說什麼了不起,它不過是讓交換機同時推送多條消息給綁定的隊列,我們當然也可以在簡單模式的基礎上多進行幾次basic_publish發送消息到指定的隊列。當然我們這樣做的話,可能就沒辦法做到由交換機的同時發送了,效率可能也沒有一次basic_publish的高
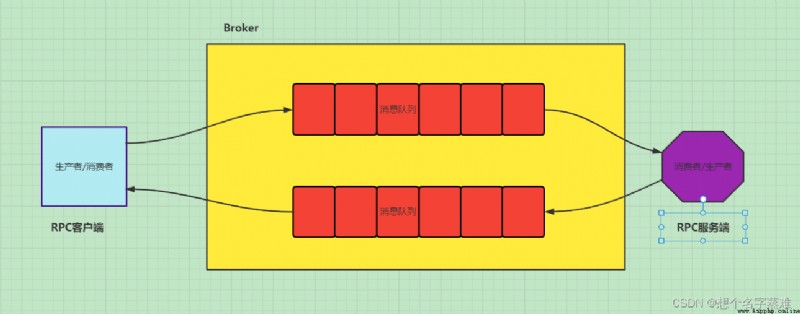
下面實現由rpc遠程調用加減運算
客戶端
import pika
import uuid
import json
class RPC(object):
def __init__(self):
self.call_id = None
self.response = None
user_info = pika.PlainCredentials('root', 'root')
self.connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
self.channel = self.connection.channel()
# 創建一個此客戶端專用的queue,用於接收服務端發過來的消息
result = self.channel.queue_declare(queue='', exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(
queue=self.callback_queue,
on_message_callback=self.on_response,
auto_ack=True)
def on_response(self, ch, method, props, body):
# 判斷接收到的response是否屬於對應request
if self.call_id == props.correlation_id:
self.response = json.loads(body.decode('utf-8')).get('result')
def call(self, func, param):
self.response = None
self.call_id = str(uuid.uuid4()) # 為該消息指定uuid,類似於請求id
self.channel.queue_declare(queue='rpc_queue')
self.channel.basic_publish(
exchange='',
routing_key='rpc_queue', # 將消息發送到該queue
properties=pika.BasicProperties(
reply_to=self.callback_queue, # 從該queue中取消息
correlation_id=self.call_id, # 為此次消息指定uuid
),
body=json.dumps(
{
'func': func,
'param': {'a': param[0], 'b': param[1]}
}
)
)
self.connection.process_data_events(time_limit=3)# 與start_consuming()相似,可以設置超時參數
return self.response
rpc = RPC()
print("發送消息到消費者,等待返回結果")
response = rpc.call(func='del', param=(1, 2))
print("收到來自消費者返回的結果:{}".format(response))
服務端
import pika
import json
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
# 指定接收消息的queue
channel.queue_declare(queue='rpc_queue')
def add_number(a, b):
return a + b
def del_num(a, b):
return a - b
execute_map = {
'add': add_number,
'del': del_num
}
def on_request(ch, method, props, body):
body = json.loads(body.decode('utf-8'))
func = body.get('func')
param = body.get('param')
result = execute_map.get(func)(param.get('a'), param.get('b'))
print('進行{}運算,並將結果返回個消費者'.format(func))
ch.basic_publish(exchange='', # 使用默認交換機
routing_key=props.reply_to, # response發送到該queue
properties=pika.BasicProperties(
correlation_id=props.correlation_id), # 使用correlation_id讓此response與請求消息對應起來
body=json.dumps({'result': result}))
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
# 從rpc_queue中取消息,然後使用on_request進行處理
channel.basic_consume(queue='rpc_queue', on_message_callback=on_request)
print(" [x] Awaiting RPC requests")
channel.start_consuming()
對於rabbitmq的模式還有Routing模式和Topics模式等,這裡就不復述了,其實pika對於RabbitMQ的使用還有很多細節和參數值得深究。這篇博客也就是簡單的記錄下我對pika操作raabbitmq過程和簡單的理解
參考鏈接:
https://www.cnblogs.com/guyuyun/p/14970592.html
https://blog.csdn.net/wohu1104/category_9023593.html
如果有什麼錯誤的地方,還請大家批評指正。最後,希望小伙伴們都能有所收獲。碼字不易,喜歡的話,點贊關注一波在走吧

先自我介紹一下,小編13年上師交大畢業,曾經在小公司待過,去過華為OPPO等大廠,18年進入阿裡,直到現在。深知大多數初中級java工程師,想要升技能,往往是需要自己摸索成長或是報班學習,但對於培訓機構動則近萬元的學費,著實壓力不小。自己不成體系的自學效率很低又漫長,而且容易碰到天花板技術停止不前。因此我收集了一份《java開發全套學習資料》送給大家,初衷也很簡單,就是希望幫助到想自學又不知道該從何學起的朋友,同時減輕大家的負擔。添加下方名片,即可獲取全套學習資料哦