1.簡介
拉依達准則(Pau’ta Criteron)是先假設一組數據中只含有隨機誤差,首先按照一定准則計算標准偏差,按照一定概率確定一定區間,認為不在這個區間的為異常值。當數據呈正太分布或者近似正太分布時可以使用
2.數據集示例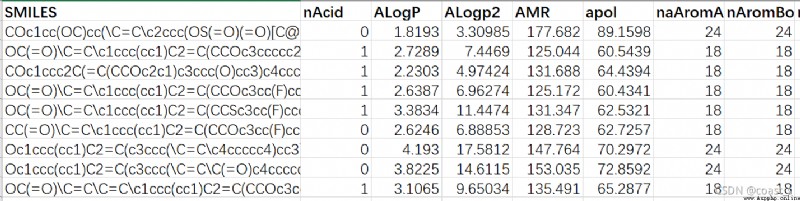
3.完整處理代碼
import numpy as np
import pandas as pd
#設置需讀取文件的路徑
datapath = "traning處理前.xlsx"
data = pd.read_excel(datapath)
# 記錄方差大於3倍的值
#shape[0]記錄行數,shape[1]記錄列數
sigmayb = [0]*data.shape[0]
for i in range(1,data.shape[1]):
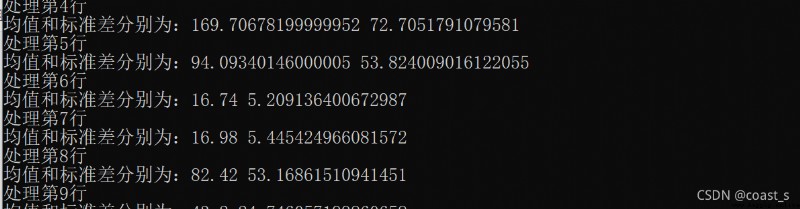
print("處理第"+str(i)+"行")
# 循環 每一列
lie = data.iloc[:, i].to_numpy()
#print(lie)
mea = np.mean(lie)
s = np.std(lie, ddof=1)
# 計算每一列 均值 mea 標准差 s
print("均值和標准差分別為:"+str(mea)+" "+str(s))
#統計大於三倍方差的行
for t in range(1,data.shape[0]):
if (abs(lie[t]-mea) > 3*s):
print(">3sigma"+" "+str(t)+" "+str(i))
#將異常值置空
data.iloc[t,i]=' '
#將處理後的數據存儲到原文件中
data.to_excel(datapath)
4.運行結果